
S&P Quantitative Investment Model Development Competition Report
Published:
개요

현재, AI와 투자의 세계는 데이터의 다양성과 복잡성으로 인해 계속해서 진화하고 있습니다. 금융 데이터 분석 Task에 다양한 AI 기법을 접목한 사례는 계속해서 등장하는 중이고, 그 효과를 충분히 입증하고 있지만 이러한 작업들 하나로 융합하는 형태는 드물었습니다. 또한 개발 지식이 부족한 일반인들은 진입 장벽이 너무나도 높습니다.
최근 GPT-5의 능력이 AGI에 도래했다는 예측이 등장하면서 AI 생태계에 큰 영향을 미치고 있습니다. 현재 ChatGPT는 현재에도 멀티모달리티를 구현했다고 볼 수 있습니다. Conversation AI 형태인 ChatGPT는 OpenAI의 다양한 API를 활용해 사용자에게 훌륭한 아웃풋을 제공하고 있습니다. DALLE-3을 통해 이미지 생성을 할 수도 있고, 영수증을 업로드하면 이미지 인식으로 어떤 품목을 구매했는지 표로 변환할 수 있습니다. csv 파일을 업로드하면 전공자 수준의 데이터 분석도 가능하며, 사용자가 Instructions prompt를 제공하면 내가 원하는 Task에 최적화된 GPT-4 모델을 사용할 수도 있습니다.
결국 AI 생태계의 미래는 AGI가 될 것이라는 것은 누구나 잘 알고 있습니다만, 어떻게 도달하는지가 중요할 것입니다. 그만큼 AGI에 도달하는 것은 굉장히 어려운 일이며, 많은 연구자들이 도전하고 있습니다. 기본적으로 AGI라 하면 다양한 Input에도 사용자가 원하는 output을 내보내야 할 것입니다. 그렇다면 다양한 Input을 인식할 수 있도록 범용적인 AI 모델 아키텍처를 구축할 필요가 있습니다. 금융 데이터 분석에 사용될 AI도 마찬가지라고 생각합니다.
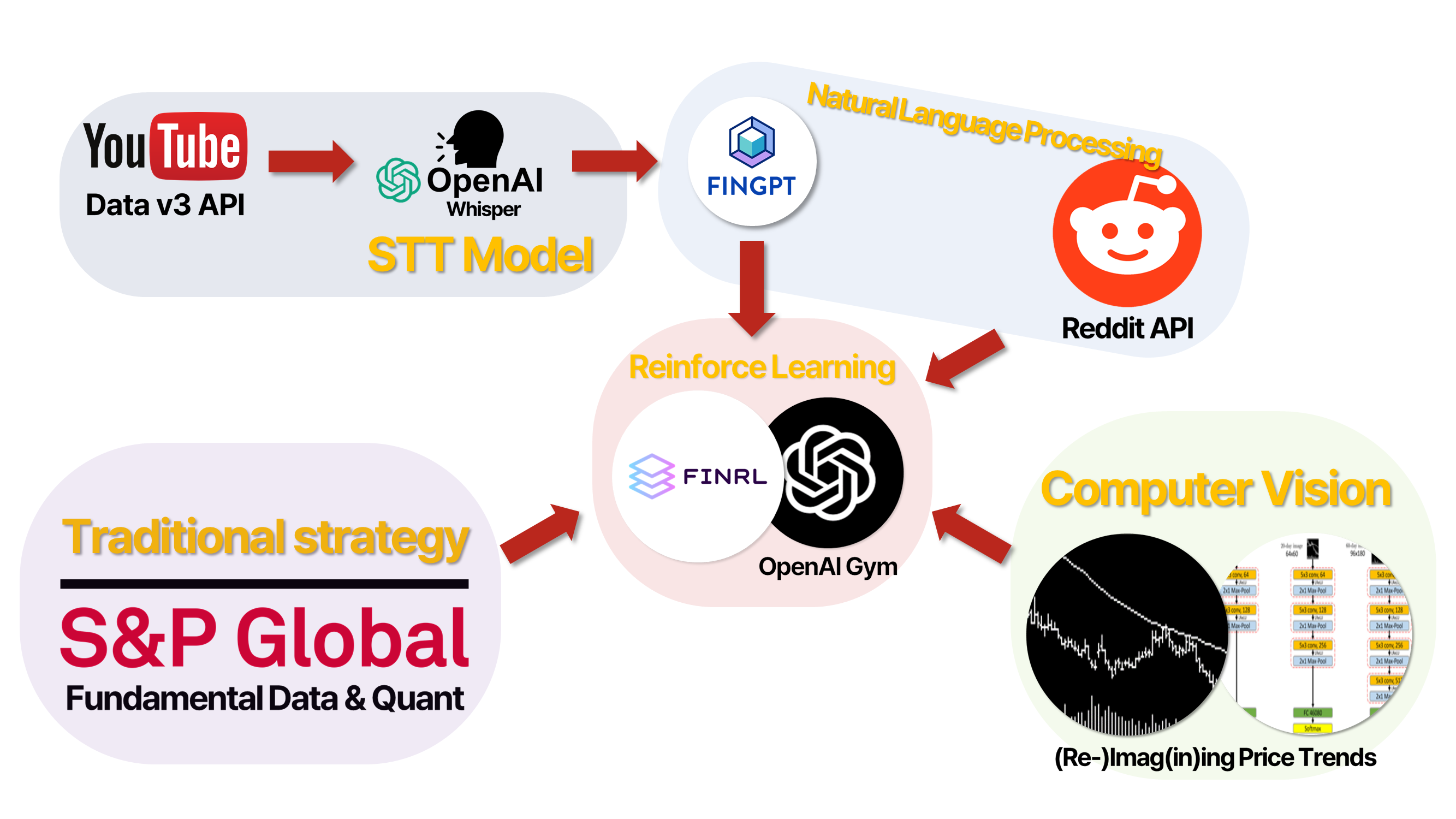
우리 프로젝트의 핵심은 다양한 데이터 소스와 API의 통합입니다. 여기에는 YouTube Data v3 API를 통한 데이터 추출, OpenAI Whisper 같은 STT (Speech-to-Text) 기술, FinGPT (Llama2), Reddit API, S&P Data를 활용한 NLP (Natural Language Processing) 기술, (Re-)Imag(in)ing Price Trends를 통한 CV (Computer Vision), 그리고 S&P Data를 결합한 정량적 데이터 분석이 포함됩니다.
이 멀티모달 데이터 접근 방식을 통해, 우리는 금융 데이터의 다양한 측면을 분석하고, 보다 정확하고 효과적인 투자 결정을 내리는 데 필요한 통찰력을 제공하고 싶습니다. 이 프로젝트는 데이터 과학과 퀀트 금융 분야에서 새로운 지평을 여는 것을 목표로 합니다. 다시 말해, 우리의 “퀀트 투자 모델의 멀티모달리티 적용” 프로젝트는 AI 트렌드를 반영한 혁신적인 접근 방식을 통해 금융 시장의 동향을 예측하고 분석할 것입니다.
목차
- Audio
- Youtube Data V3 API
- Whisper를 활용한 음성 전사
- FinGPT로 감성 분석
- Natural language process
- Reddit API를 활용한 감성 지표 추출
- Computer Vision
- (Re-)Imag(in)ing Price Trends 논문 리뷰
- (Re-)Imag(in)ing Price Trends Clone Coding
- (Re-)Imag(in)ing Price Trends 성과 분석
- Finance
- S&P Dataset, Market
- S&P Dataset, Financials
- 데이터 전처리
- Investment
- OpenAI Gym을 이용한 Trading
- 각 데이터의 I/O로 성과 비교 분석
Audio

재무 보고서나 애널리스트 보고서를 분석해 투자 모델에 적용하는 방법은 상당히 오래 전부터 이어져 왔습니다. 현대에는 Transformer, BERT, LLMs 등 효과적인 자연어 처리 모델이 등장함에 따라 단어 단위의 분석에서 실제 사람이 자연어를 받아들이는 방식으로 보고서를 이해할 수 있게 되었습니다.
Youtube Data V3 API
현재 Youtube는 엄청난 성장세를 보이고 있습니다. 이제 사람들은 정보를 찾기 위해 웹 브라우저를 시랭해 검색 엔진을 사용하는 것이 아니라, Youtube를 실행해 짧은 영상을 시청합니다. 사람들은 매일 수십억 건의 조회수를 생성하고, 매 분마다 500시간이 넘는 동영상 콘텐츠를 수신합니다. 역시나 많은 사람들이 투자 관련 유튜브를 시청하고, 또 그 조언을 믿고 투자하는 경향이 있습니다. 대부분의 사람들은 재무제표나 애널리스트 보고서를 읽지 않고 유튜브 동영상과 숏츠에 편향되어있다는 것입니다.
이러한 의문점에서 시작하여 유튜브 영상 데이터를 투자 모델에 적용하는 방법을 구축했습니다. 동영상 데이터는 프레임 단위로 존재하는 이미지 파일과 음성 파일로 이루어져 있습니다. 우리는 시각 정보 보다는 음성 정보, 즉 콘텐츠 제공자가 이용자에게 전달하고자 하는 주요 정보에 입각하여 음성 파일을 분석합니다.
"stock OR Finance OR analysis OR investment OR NASDAQ OR S&P OR US market" 다음과 같은 검색어를 이용하여 2017년부터 2023년까지 매 월 50개의 영상의 음성 파일을 다운로드 했습니다.
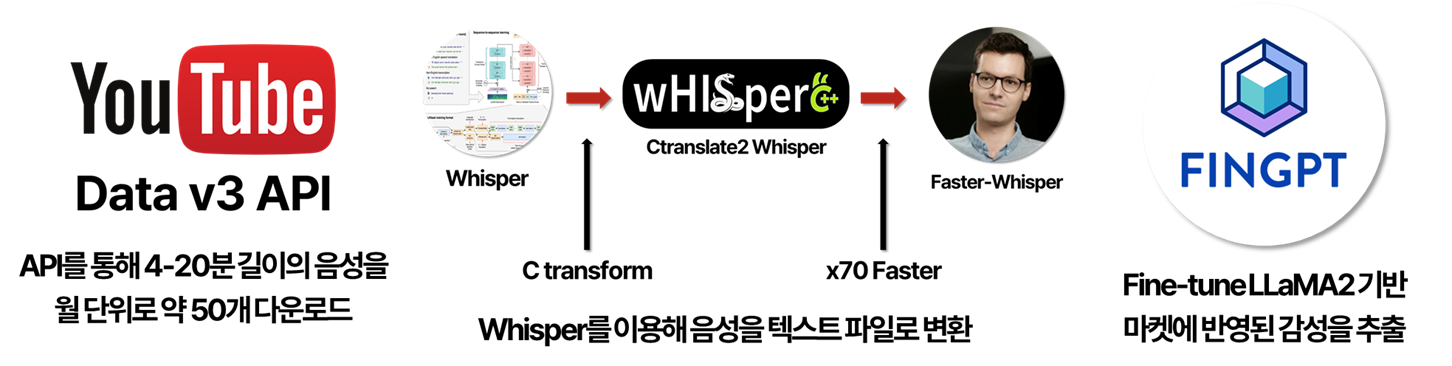
Whisper를 활용한 음성 전사

해당 파일은 OpenAI의 STT Model인 Whisper를 이용하여 전사할 수 있습니다. 해당 모델의 영어 전사 성능은 99%에 달합니다. 그러나 수 천개에 달하는 유튜브 영상의 음성 파일을 모두 전사하는 데에는 너무나도 큰 GPU 리소스가 소모될 것입니다. 따라서 이를 최적화하는 방법이 꼭 필요합니다.
우리는 여러 개발자들의 오픈소스 프로젝트들을 종합했습니다. Ctranslate2는 모델 파라미터를 C로 구현하여 더 빠르게 inference하는 오픈소스 프로젝트고, 이를 적용한 Whisper.cpp가 등장했습니다. 그럼에도 불구하고 Whisper의 모델이 너무 커 역시나 빠른 편은 아니었습니다. 이후, 다양한 방법론들이 등장하면서 모델의 성능을 잃지 않으면서도 inference 속도를 빠르게 하기 위한 노력이 계속되었고, 현재는 Faster-whisper 또는 distil-Whisper가 가장 좋은 성능을 보이고 있습니다. 우리는 Faster-whisper를 사용했으며, 이는 일반 Whsiper보다 4배 이상 빠릅니다.
NLP
금융 데이터 분석에 자연어 처리를 사용하는 것은 현재 충분히 보편화 되었으며, 다양한 분야와 방법으로 수행되고 있습니다. 자연어 처리야 말로 가장 대표적인 비정형 데이터를 정형화 또는 팩터화하는 프로세스일 것입니다. 우리는 멀티모달리티의 자연어 처리 프로세스를 구현하기 위해 Reddit 데이터를 사용하는 것으로 결정했습니다.
Reddit은 21년 기준으로 100억 달러 규모의 기업 가치를 가집니다. 많은 유저들이 정보를 공유하고 트래픽을 생성하며, 금융 채널도 별도로 존재하여 그 데이터의 질이 다른 커뮤니티보다 좋다고 볼 수 있을 것입니다. 추가로 덧붙히자면, 트위터는 API 사용 제한이 존재하여 사용하지 않았으나 충분히 고려해볼만한 선택지입니다.
FinGPT로 감성 분석
전사된 txt 파일은 FinGPT로 감성 분석를 진행합니다. FinGPT는 오픈소스 프로젝트로, GPT와 관련된 AI 기술들을 이용하여 금융 데이터 분석에 최적화를 수행합니다. FinGPT 감성 분류기는 Llama2로 구현되었으며, 다양한 금융 데이터셋을 통해 Fine-turing을 수행하였습니다. GPT4와 벤치마크 테스트를 진행해도 FinGPT Llama2 모델이 더 높은 정확도를 보여줍니다.
최종 아웃풋은 금융 시장에 대한 월별 감성 스코어입니다. 해당 점수는 투자 지표로 사용되며, 감성 스코어가 낮을 경우에는 투자를 중지하고, 높을 경우에는 투자를 진행하도록 사용할 수 있습니다. 이번 프로젝트에서는 검색어를 주식 시장과 미국 시장을 중심으로 하였으나, 원자재나 채권, 개별 종목 등으로 검색어를 조정하여 데이터를 생성한다면 다양한 아웃풋을 창출할 수 있을 것 으로 기대합니다.
4-20분의 중간 길이의 유튜브 영상을 텍스트로 전사하였을 때의 그 문자열의 길이는 평균적으로 10,000자라는 통계를 알 수 있습니다. 우리가 간과한 사실은, Llama2의 최대 토큰의 수가 512개밖에 되지 않는다는 것입니다. 또, max_length인 512개로 묶어 분석을 진행하게 되면 약 10~20초 정도의 inference 시간이 소요됩니다. 2017년부터 2023년까지 영상은 모두 3000개이므로, 이를 GPU로 하나로 inference하게 되면 244시간이라는 어마어마한 시간이 소요됩니다.
영상 전체의 감성을 분석해내는 초기 목적과는 다소 다르지만, 구현 가능한 어쩔 수 없는 대안을 선택했습니다. 개별 영상 전체의 text 중 임의의 구간 512자를 정해서, 그 512자가 어떤 감성을 가지는지를 분석하는 것입니다. 예를 들어, 주식 시장을 예측하는 동영상 15분 분량의 스크립트가 존재할 때, 우리는 전사된 텍스트의 길이를 기반으로 15분 중 랜덤하게 구간을 정합니다. 이렇게 랜덤하게 선택된 구간의 텍스트를 감성 분석하여 영상 전체의 분위기를 파악하겠습니다.
사실 4-20분의 중간 길이 영상에서 랜덤하게 텍스트를 추출할 경우 실제 영상 분위기와 정 반대의 감성이 추출될 가능성이 매우 높습니다. 평균적으로 1만자에 달하는 영상 스크립트 중 500자만 사용한다는 것은 전체 영상의 5%만 사용한다는 것과 같습니다. 따라서 해당 지표는 신빙성이 매우 낮을 수 있습니다.
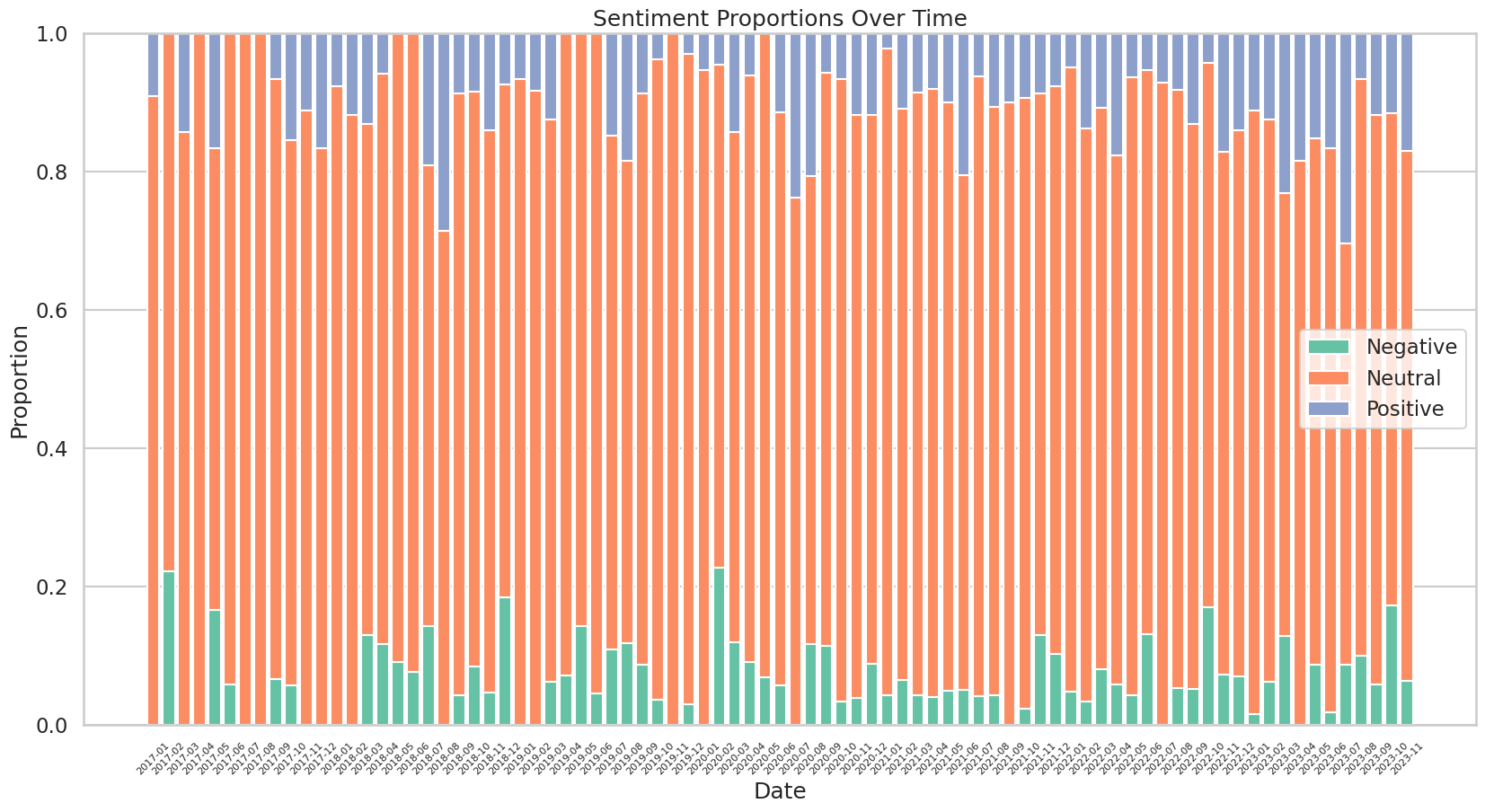
따라서 이 절차는 이렇게 시도할 수 있다라는 측면으로 기록하며, 실제 모델에는 사용하지 않겠습니다. 추후 뉴스의 헤드라인이나 S&P에서 제공하는 Events의 헤드라인 데이터를 이용하면 더 빠르고 효과적으로 활용할 수 있을 것입니다. 더불어 4-20분의 중간 길이 영상보다, 1분 미만의 숏츠를 집중적으로 타겟한다면 통계적으로 신빙성 있는 가설을 설정할 수 있을 것입니다.
Reddit tradestie API로 Ticker 별 감성 점수 추출
tradestie는 역시 오픈소스 프로젝트로, Reddit의 금융(주식) 관련 데이터를 가공하여 이용자들이 편하게 사용할 수 있도록 API의 형태로 제공합니다. 따라서 우리는 별도의 구현 과정이 전혀 필요 없으며, 단순 API 요청을 통해 JSON 형식의 응답을 받아 파싱하여 팩터로 사용하기만 하면 됩니다. 아래의 코드는 해당 API의 사용 과정을 보여줍니다. 다음과 같은 JSON을 Python을 통해 적절히 파싱하여 데이터프레임으로 변환 후 지표로 사용하겠습니다.
curl -XGET 'https://tradestie.com/api/v1/apps/reddit?date=2022-04-03'
[{ "no_of_comments": 179, "sentiment": "Bullish", "sentiment_score": 0.13, "ticker": "GME" }, { "no_of_comments": 37, "sentiment": "Bullish", "sentiment_score": 0.159, "ticker": "AMC" }, { "no_of_comments": 17, "sentiment": "Bullish", "sentiment_score": 0.22, "ticker": "PLTR" }, ...]
Computer Vision
(Re-)Imag(in)ing Price Trends 논문 리뷰

(Re-)Imag(in)ing Price Trends는 시카고 부스 연구소의 논문으로, Jingwen Jiang, Bryan T. kelly, Dacheng Xiu가 작성했습니다. 특히 Kelly와 Xiu는 금융 데이터 분석에 머신러닝과 딥러닝을 적용하는 대표적인 연구자입니다. 금융의 AI 접목에 대해 관심이 있는 사람들은 이 연구자들의 논문들(Financial Machine Learning, Empirical Asset Pricing Via Machine Learning, Autoencoder Asset Pricing Models)을 읽으면 정말 좋습니다.
이 논문은 가설을 설정하는 것이나 모멘텀이나 리버설 전략과 같은 패턴보다, 소위 차티스트나 추세초종 트레이더라고 불리는 투자자들의 투자 패턴에서 착안하여, 미래 수익률을 가장 잘 예측하는 가격 패턴을 유연하게 학습하는 방법을 사용해 추세 기반 예측 가능성이라는 개념을 정의하려고 합니다. 놀라운 것은 예측 데이터의 원시 데이터가 우리가 눈으로 보는 주식 수준의 가격 차트이며, 이 때 머신러닝 이미지 분석 방법을 사용해 수익률을 가장 잘 예측하는 가격 패턴을 도출합니다.
이 논문에서 식별할 수 있는 예측 패턴은 일반적인 논문들에서 분석되는 추세 신호와 크게 다른 점을 보입니다. 더 정확한 수익률 예측을 제공하고, 더 수익성 있는 투자 전략으로 변환할 수 있으며, 다양한 상황 변화에 대해 Robust합니다. 가장 큰 장점은 어떤 상황에 구애받지 않는다는 것입니다. 일별 데이터로 추정된 예측 패턴을 월별 데이터에 그대로 적용했을 때에도 비슷한 예측력을 제공하며, 미국 주식에서 학습한 패턴은 해외 시장에서도 잘 적용되는 전이학습의 가능성까지 보여줍니다.
(Re-)Imag(in)ing Price Trends Clone Coding
21년에 처음 게재된 이 논문은 비교적 최근인 23년 8월 2일, 세계적인 재무 금융 저널 Journal of Finance 에 게재되었습니다. 저자들은 자세한 구현 방법을 설명함과 동시에 재현 가능한 코드를 저널에 업로드하였습니다. 따라서 우리는 밑바닥부터 스크래치로 구현하는 것이 아니라, 저자의 코드를 우리의 환경에서 잘 동작하도록 조금 수정한 것 뿐입니다. 양질의 코드를 분석할 수 있어 굉장히 좋은 기회였습니다.
데이터셋 제작
저자는 1993년 ~ 2000년까지의 데이터를 이용해서 모델을 학습하고, 2001년 ~ 2019년까지 검증을 합니다. 이 때 저자는 CRSP의 US 데이터를 사용했는데, 우리는 마침 S&P 데이터가 존재하므로 2017년 ~ 2023년 10월까지의 데이터를 사용하겠습니다. 학습 기간은 2017-01-01 ~ 2021-12-31이며, 검증 기간은 2022-01-01 ~ 2022-09-20입니다.
그러나 학습기간이 줄어든 만큼 전체 데이터의 크기에 줄어들어 제대로 학습이 되지 않는 문제가 발생할 수 있습니다. 따라서 우리는 S&P 데이터의 장점을 살리려고 합니다. WFE 기준 시가총액 상위 24개 거래소의 주식 데이터를 모두 사용할 때 주식의 종류는 11000여개에 달합니다. 데이터의 신빙성을 위해 특정 임계치를 넘는 결측치 가지는 주식 데이터를 처리한 이후에도 무려 5500여개의 데이터를 활용할 수 있었습니다.
S&P 데이터의 아쉬운 점은 OHLCV 데이터 중, OHL 데이터가 존재하지 않는다는 것입니다. 주식 데이터를 이미지로 변환할 때 고가와 시가 또한 반영해야 했으므로, 존재하지 않는 데이터를 추가로 채워야만 합니다. 따라서 우리는 CRSP 데이터 형식에 맞게 yfinance를 이용하여 최종 데이터셋을 제작하였습니다. 우리가 제작한 데이터는 거의 CRSP 데이터와 유사합니다.
모델 아키텍처
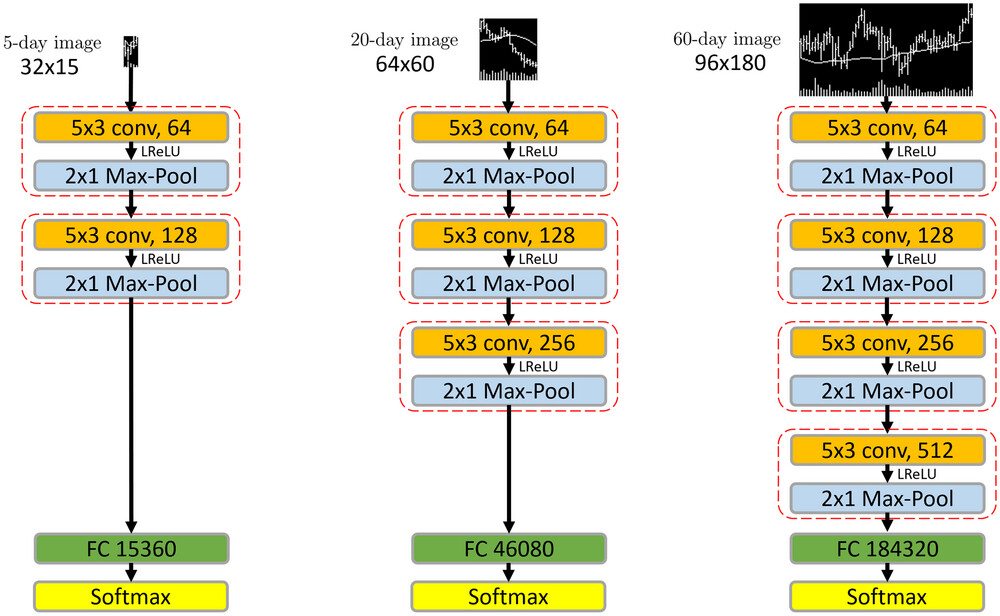 모델은 생각보다 복잡하지 않습니다. 5x3 Conv 층과 2x1 Max-Pool 층이 번갈아가면서 등장하는 전형적인 CNN입니다. 이렇게 0과 1로 채워져있는 단순한 이미지 데이터는 모델이 복잡하지 않아도 CNN으로 충분히 SOTA 성능을 내고 있습니다. 가장 비슷한 대표적인 예가 MNIST 손글씨 예측 Task입니다.
모델은 생각보다 복잡하지 않습니다. 5x3 Conv 층과 2x1 Max-Pool 층이 번갈아가면서 등장하는 전형적인 CNN입니다. 이렇게 0과 1로 채워져있는 단순한 이미지 데이터는 모델이 복잡하지 않아도 CNN으로 충분히 SOTA 성능을 내고 있습니다. 가장 비슷한 대표적인 예가 MNIST 손글씨 예측 Task입니다.
가장 마지막 층은 FC Layer(Fully Connected Layer)로 내보내고, 입력 이미지의 길이인 ws 기준으로 pw일 뒤의 가격이 오를지 내릴지 예측하는 확률을 Softmax 함수를 이용해 출력합니다. 논문에서는 ws와 pw를 다음과 같이 설정했습니다.
ws = [5, 20, 60]
ps = [5, 20, 60]
저자들은 이렇게 선택 가능한 9가지 조합에 delay를 추가하는 등의 추가 분석도 진행했습니다. 예를 들어 60일 뒤의 수익률을 보는 것이 아니라, 65일 뒤의 수익률을 보거나, ps일 뒤의 확률을 예측하는 것은 동일하지만 포트폴리오의 수익률을 계산할 때 ps일 뒤의 수익률이 아니라 ps+delay일 뒤에 해당하는 수익률을 계산하는 방법을 활용했습니다.
10분위 포트폴리오
이 모델을 사용하면, 검증 기간 내의 모든 주식에 대해 ps일 뒤의 확률을 얻을 수 있습니다. 우리는 검증 기간의 실제 수익률을 알고 있으므로 수익률을 shift하여 손쉽게 실제 ps일 뒤의 수익률과 매칭할 수 있습니다. 이렇게 만든 데이터를 이용하여 10분위 포트폴리오를 구성할 수 있습니다. High에 해당하는 포트폴리오는 오를 확률이 높은 주식들만 고려되며, 반대로 Low에 해당하는 주식들은 내릴 확률이 높은 주식들로만 고려됩니다. H-L를 통해 Long-Short Portfolio를 구성할 수도 있습니다.
(Re-)Imag(in)ing Price Trends 성과 분석
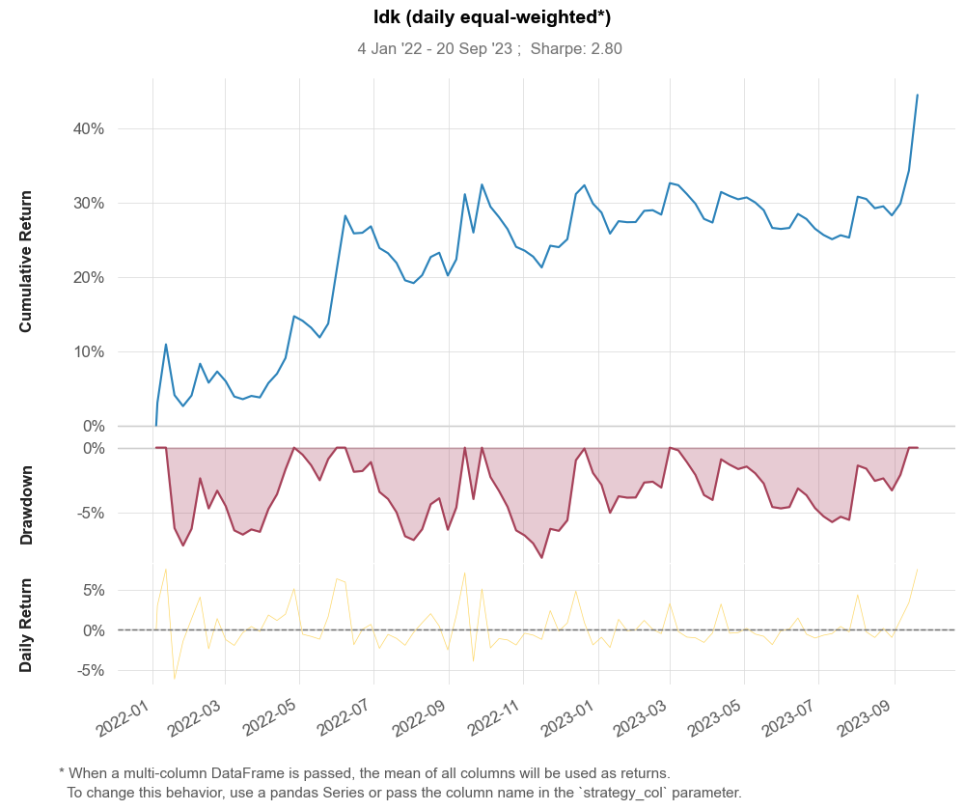
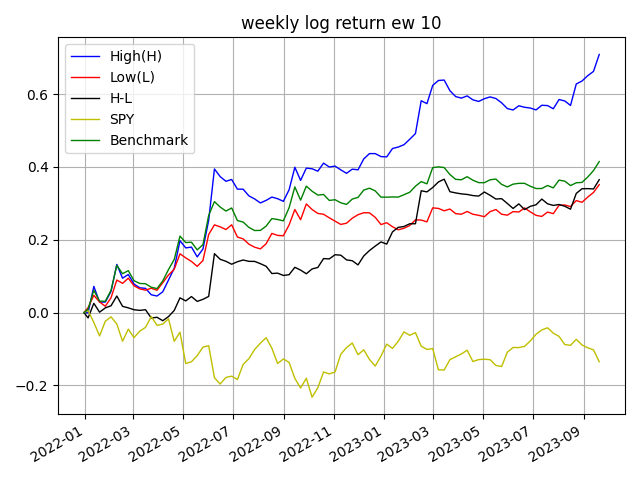
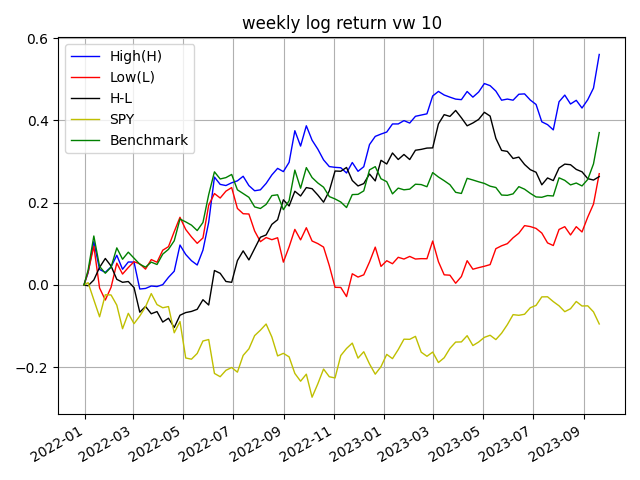
우리는 ws기간을 20일로 설정하고, ps 기간을 5일로 설정했습니다. 즉, 20일의 차트를 인식해서 5일 뒤의 성과를 예측하는 것입니다. 선택 가능한 9가지 조합을 모두 실험해보아야 하지만, GPU 학습 속도의 한계로 인해 한 가지 테스트만 진행한 점 양해를 부탁드립니다. 추후 다양한 기간으로 실험을 진행하여 벤치마크를 나타내야 합니다.
아래 그래프는 주간 수익률을 사용해 동일 가중 포트폴리오와 시가총액 가중 포트폴리오의 수익률을 시각화 한 것입니다. 모두 로그 조정수익률이며, High는 10분위 포트폴리오 중 1분위에 해당하는 값이며, Low는 그 역입니다. 벤치마크의 경우 5500개의 모든 종목에 균등 투자한 것과 시가총액 가중 방식으로 투자한 것입니다.
| Quantile | ret | std | SR |
| Low | 0.211688 | 0.130185 | 1.626057 |
| 2 | 0.235491 | 0.159037 | 1.480729 |
| 3 | 0.258983 | 0.161208 | 1.606517 |
| 4 | 0.229987 | 0.162912 | 1.411726 |
| 5 | 0.223883 | 0.162781 | 1.375361 |
| 6 | 0.22045 | 0.163362 | 1.349453 |
| 7 | 0.198265 | 0.161929 | 1.22439 |
| 8 | 0.256625 | 0.171152 | 1.499397 |
| 9 | 0.253139 | 0.171171 | 1.478866 |
| High | 0.434365 | 0.221733 | 1.958958 |
| H-L | 0.222677 | 0.155156 | 1.435175 |
| Turnover | 5.540268 |
위 표는 각 퀀타일에 해당하는 수익률, 표준편차, 샤프 비율을 나타냅니다. Turnover가 554%이므로 거래 비용과 슬리피지를 감안했다면 높은 수익을 얻기란 쉽지 않아보입니다. 아무래도 종목이 많다보니 Turnover도 비정상적으로 상승합니다. 현실과는 조금 동떨어진 분석 자료입니다. 다만, CNN이 주식 패턴을 예측한다는 것을 입증하기에는 충분합니다.
Finance
Preprocessing
데이터 분석을 진행할 때, 어떻게 구현하는 것보다 무슨 데이터를 왜 사용해야 하는지 입증하는 것은 정말 중요한 절차 중 하나라고 생각합니다. 우리는 이 경진대회의 목적에 의거하여, 최대한 S&P dataset을 사용하고자 하였습니다. 제일 먼저 활용한 것은 역시나 Market 데이터입니다.
거래소를 선택하고, 자산군을 선택하고, 섹터를 선택하고, 개별 종목을 선택해야 비로소 앞으로의 투자 모델의 틀이 잡힐 것입니다. 만약 이러한 계획이 없었다면 위의 모든 분석들은 진행할 수 없었을 것입니다. 따라서 우리는 Market 데이터의 시계열과 종목을 최대한 사용하지만, 사전에 설정한 규칙에 의거하여 기준을 적용할 때마다 데이터를 필터링합니다.
우리는 다음과 같은 프로세스로 투자 종목을 한정했습니다.
- WFE 기준으로 시가총액 상위 24개에 속하는 거래소에 상장된 종목들만 남기고 다른 종목은 모두 지웁니다.
- 상장된 통화가 달라 중복인 행은 제거합니다.
- StockID를 기준으로, 전체 기간 중 임계값 이상 NaN을 가지고 있으면 해당 StockID를 사용하지 않습니다.
- 위 절차를 통과한 후, Date 기준으로 임계값 이상 NaN을 가지고 있으면 해당 Date를 사용하지 않습니다.
- 나머지 날짜에 존재하는 결측값은 각 거래소 특성에 의한 휴장일 등으로 간주하여 Forward Fill을 적용합니다.
- 최종 생성된 데이터는 약 5500개 종목이며, 2017-01-01 ~ 2023-10-10의 기간을 가집니다.
Financials, Others
S&P에서 제공한 재무 데이터는 양적으로나 질적으로 매우 훌륭합니다. 위에서 전처리 한 데이터에 Financials 데이터를 join하여 해당 StockID가 재무적으로 어떤 지표를 갖는지 보다 더 쉽게 알 수 있도록 합니다.
이것 외에도 KeyDev나 Estimate와 같은 데이터도 충분히 활용할 만합니다. 전통적인 퀀트 전략에 초점을 맞추기 위해서라면 해당 데이터를 이용해 최대한 놓치는 정보 없이 재무 데이터를 구축하는 것이 옳습니다만, 우리의 목적은 멀티 모달리티 적용에 있으므로 우선순위를 조금 뒤로 미루겠습니다.
Investment
우리는 최종적으로 Financial Reinforcement Learning Agent로 투자를 진행합니다. 해당 Agent는 OpenAI에서 개발한 오픈소스 강화학습 라이브러리 gym을 사용합니다.
Reference
Youtube
- Youtube API Guide
- YouTube Statistics Marketers Need to Know in 2023
- Latest YouTube Statistics (2023 User And Revenue Data)
OpenAI Whisper
FinGPT
Reddit API
Quant
- AI4Finance-Foundation/FinRL-Tutorials
- Deep Reinforcement Learning for Stock Trading from Scratch: Portfolio Allocation
- Quantstats
Comments