
AI 프로젝트를 위한 WSL2 개발 환경 세팅 가이드
Published:
들어가는 글
최근 KAIST, UNIST, 경희대학교 3개 대학에서 공동 주관하고 S&P Global에서 주최한 퀀트 투자 모델 경진대회에 참가하면서 다양한 코드들을 수집하고 또 분석하고 있다. 프로젝트를 진행하면서 깨닫는 것도 많고, 얻는 것도 많다. 대회를 진행하면서 수 많은 생각을 하게 되고 내가 앞으로 어떤 개발자가 되고 싶은지 윤곽이 보이곤 한다. 이번 대회를 통해 얻은 인사이트는 잘 정리해서 많은 사람들에게 공유하고 싶다. 개발 지식, 프로젝트 관리 기법, 공동의 문제 해결을 위해 접근하는 방법론이 대부분일 것 같다.
현재 KHUDA에서 기술 블로그 스터디를 진행하고 있지만, 항상 내 가슴 한 켠에 불편함이 자리 잡고 있다. 소위 블로그란, 많은 사람들에게 [나]와 [정보]를 공유하기 위한 공간이라고 나는 정의한다. 더 나아가 기술 블로그란, 내가 온전히 나의 것으로 만든 지식을 다른 사람들에게 소개하고 쉬운 방법으로 설명하기 위해 작성하는 글이라고 계설한다.
나는 나에게 되묻는다. ‘이렇게 단발적인 지식 공유로 한 주를 마무리 해도 되는 것일까?’, ‘그 지식이란 온전히 내 것이 되었는가?’, ‘다른 사람에게 충분히 설명할 수 있을만큼 이해했는가?’, ‘글은 짜임새 있게 누구나 이해하기 쉽도록 작성되었는가?’가 주요 질문이다. 참 어려운 질문이다. 그러나 다시 생각해보면 당연한 질문이다. 습득하는 지식에 대한 허들조차도 높은데, 그 지식을 올바른 형태로 재가공하여 설명하는 글로써 타인에게 공유한다는 것은 매우 어려운 일이 아닌가.
이러한 고민 자체가 나를 더 나은 사람으로 몰아넣고 있다는 것에는 적극 동의하며, 결국 내가 스스로 내린 피드백은 다음과 같다.
- 이 행위의 우선순위는 더 높아야 한다.
- 이 행위는 시간과 정성을 들여야 한다.
- 복사-붙여넣기는 안하느니만 못하다.
어렵지만 어쩌겠는가. No Pain, No Gain이라고 하였고, 결국 하지 않으면 아무 일도 일어나지 않는다.
WSL2를 선택한 배경
현재 연구실 컴퓨터는 Windows 11로 사용하고 있다. 때문에 Python 개발 환경을 구축하고 나면 해결하기 조금 까다로운 오류들이 자주 발생하곤 한다. 오류를 해결하기 위해 구글링을 하면 대부분 Linux 개발 환경에서의 해결 방법만 공유하고 있어 실질적으로 도움이 되는 글들은 발견하기 어렵다. 당연한 이야기지만 Linux 환경이 개발하기에는 훨씬 호환성도 좋다. CLI 환경에서 이미 널리 공유되고 있는 명령어 몇 개만 입력해주면 GPU 드라이버 설치와 CUDA 세팅이 끝나고, Python 개발 환경 구축도 서로 충돌하는 일 없이 잘 마무리 된다.
나는 프로젝트 계획 상 Llama2 모델을 사용해야 했고, VRAM을 약 14GB 정도 사용해서 Colab에서 T4로 돌리는 것보다 차라리 내 컴퓨터(RTX 4070 Ti)에서 돌리는 것이 낫겠다고만 계속 생각했다. 오류를 해결하려고 계속 노력했지만 원인을 알 수 없는 오류가 계속 발생했고, 어차피 WSL2 필요하다고 생각은 계속 하고 있었기에 이왕 세팅해보자고 마음 먹었다.
WSL2 설치 및 개발 환경 구축
내가 WSL를 처음 다룰 때에는 2021년 학부 수업 ‘데이터센터프로그래밍’을 수강할 때 였는데, 그 때에도 이성원 교수님께서 Linux를 적극 권장하고 Windows 유저는 오류가 날 수도 있지만 WSL를 잘 해보라고 하셨다. 그 강의 영상도 녹화본이어서 아마 2020년 기준으로는 더 오류가 많았을 것이다. 내가 수행했던 21년은 그나마 오류가 거의 없다시피 했다.
지금은 WSL2가 나왔는데, 세월의 흐름을 어마어마하게 느낄 수 있을 만큼 성능이 정말 좋다고 느꼈다. 앞으로 듀얼 부팅은 전혀 필요 없을 것 같고, Windows로도 충분히 개발 환경 구축을 할 수 있을 것 같다는 생각이다. Mac이 개발 친화적이라고는 많이 이야기 하지만, WSL만 잘 활용한다면 딱히 그렇지도 않은 것 같다. 특히 마이크로소프트 공식 문서에 설명이 매우 잘 되어있어, 가이드만 잘 따라하기만 해도 구축하는 것은 정말 쉬웠다.
WSL 설치
PowerShell에서 wsl 설치 명령어를 입력해준다. Linux OS나 Version도 선택할 수 있는 것 같다.
wsl --install

설치가 완료되면 사용자 이름과 암호를 설정하면 Bash로 접근할 수 있게 된다. 공식 문서에서는 일단 업데이트를 권장한다. 그 다음 여러가지 권장 사항을 제시하는데, 내가 수행한 절차는 굵은 글씨로 표시한다.
sudo apt update && sudo apt upgrade
설정을 위한 모범 사례
- Windows Terminal 설정
- File Storage
- Visual Studio Code 사용
- Visual Studio 사용
- Git으로 버전 관리 설정
- Docker로 원격 개발 컨테이너 설정
- 데이터베이스 설정
- 더 빠른 성능을 위해 GPU 가속 설정
- 외장형 드라이브 또는 USB 탑재
- Linux GUI 앱 실행
Linux용 Windows 하위 시스템에서 Visual Studio Code 사용 시작
wget 및 ca-certificates를 추가하기 위해 다음 명령어를 입력한다.
sudo apt-get update
sudo apt-get install wget ca-certificates
이제 code .를 입력하면 VS code를 Linux에서 접속할 수 있다. 이 때, WSL Extensions를 사용하면 더 편하게 WSL를 사용할 수 있다. 해당 확장은 VS Code를 “클라이언트-서버” 아키텍처로 이해한다. SSH Remote로 서버에 접근하는 것처럼 내 WSL에도 VS Code를 통해 접근할 수 있게 된다.
Linux용 Windows 하위 시스템에서 Git 사용 시작
이제 Windows에서 작업한 코드를 가져오기 위해 Git을 설치한다. 나는 이미 Windows에서 Git을 사용하고 있기 때문에, Linux 시스템에서만 설치하면 된다. Linux의 장점은 모든 설치를 CLI 환경에서 명령어로 대체할 수 있다는 점이다.
sudo apt-get install git
Git 구성 파일 설정
이제 Git의 구성 파일 설정을 통해 내 Git 계정을 인증한다.
git config --global user.name "Your Name"
git config --global user.email "youremail@domain.com"
혹시 느꼈을지도 모르겠지만 지금까지의 모든 절차가 너무 쉽다. WSL2 짱짱.
WSL2에서 Docker 원격 컨테이너 시작
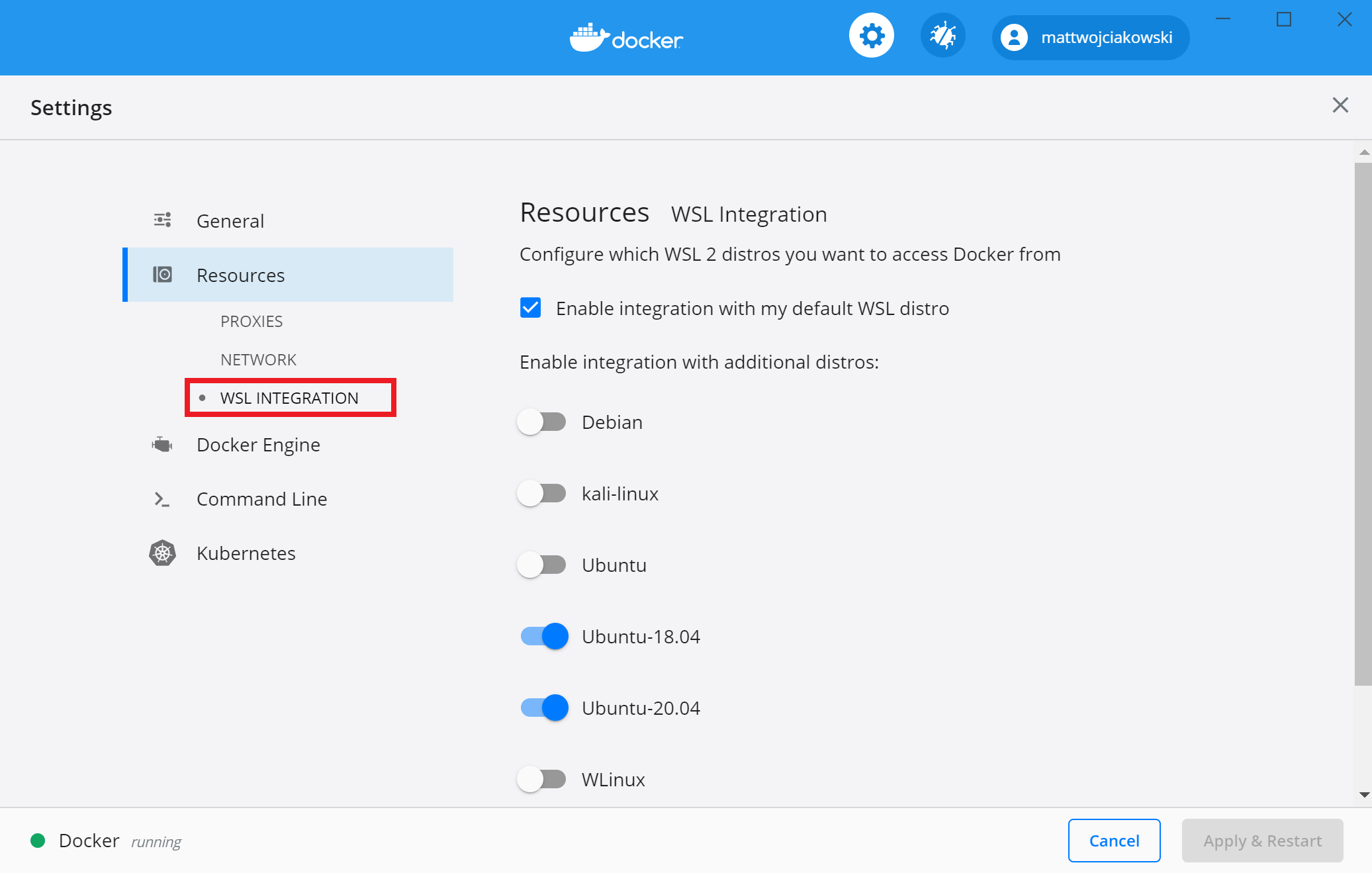
사실 처음에는 Docker 원격 컨테이너를 통해 개발 환경을 구축하려고 했다. 그러나 pipenv로 가상환경 구축을 하면 되겠다는 판단이 들어서 Docker 까지는 사용하지 않기로 결정했다. 나는 Windows 에서도 이미 Docker Desktop을 사용하고 있었는데, WSL2가 되면서 Docker Desktop GUI가 정말 보기 좋게 잘 바뀌었다. 또 WSL INTERGRATION 설정에서 내 WSL2를 추가하면 Windows 환경에서도 Linux에서 동작하고 있는 Docker 엔진을 GUI 형태로 관리 할 수 있다. 관심있는 사람은 시도해도 좋을 것같다.
WSL에서 ML용 GPU 가속 시작
솔직히 여기서 조금 오래 걸릴 줄 알았는데 제일 놀랐다. 예전에는 이 정도 편의성은 아니었던 것 같은데 지금은 진짜 쉬운 것 같다. 2~3년전 만해도 쉽지 않았다. 마치 아래의 짤이 생각나는 요즘이다.
2년 전의 나
- NVIDIA 드라이버 설치
- Tensorflow/Pytorch 공식 문서에서 호환하는 Python Version 및 CUDA 세팅 체크
- 버전에 맞는 Python 설치
- 버전에 맞는 CUDA 설치
- 버전에 맞는 CuDDN 설치
- 시스템 환경 변수 세팅
- 버전에 맞는 Tensorflow/Pytorch 설치
- 안됨. (중간에 어디서 실수 하나 했음)
지금의 나
- WSL2 설치
- 딸깍
- 됨
일단 나는 로컬에서 GPU 세팅이 끝나있었기 때문에, 더 쉬운 감이 있었다.
필수 조건
- Windows 11 또는 Windows 10 버전 21H2 이상을 실행 중인지 확인합니다.
- WSL을 설치하고 Linux 배포용 사용자 이름과 암호를 설정합니다.
Docker로 NVIDIA CUDA 설정
- NVIDIA GPU용 최신 드라이버 다운로드 및 설치
- 다음 명령을 실행하여 Docker Desktop을 설치하거나 WSL에 직접 Docker 엔진을 설치합니다.
curl https://get.docker.com | sh
sudo service docker start
- Docker 엔진을 직접 설치한 경우 아래 단계에 따라 NVIDIA Container Toolkit를 설치합니다.
- 다음 명령을 실행하여 NVIDIA Container Toolkit에 대한 안정적인 리포지토리를 설정합니다.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-docker-keyring.gpg
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-docker-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
이렇게만 하면 GPU 가속 설정이 마무리된다. 간단한 설명을 ChatGPT4에게 부탁했다.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID): 이 명령어는 현재 사용 중인 리눅스 배포판의 ID와 버전 번호를 결합하여distribution변수에 저장한다. 이 정보는 나중에 적절한 NVIDIA Docker 리포지토리를 선택하는 데 사용된다.curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-docker-keyring.gpg: 이 명령어는 NVIDIA Docker의 GPG 키를 다운로드하고, 이를 시스템의 키 저장소에 추가한다. 이는 후속 단계에서 NVIDIA Docker 패키지가 신뢰할 수 있는 소스에서 왔음을 검증하는 데 필요합니다.curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-docker-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-docker.list: 이 명령어는 NVIDIA Docker의 APT 소스 리스트를 다운로드하고, 해당 GPG 키가 해당 소스를 서명했음을 나타내는 정보를 추가한 후, 이를 시스템의 APT 소스 리스트 디렉토리에 저장한다.sudo apt-get update: 이 명령어는 시스템의 패키지 목록을 최신 상태로 업데이트한다. 이 과정에서 위에서 추가한 NVIDIA Docker 리포지토리의 패키지 정보도 포함된다.sudo apt-get install -y nvidia-docker2: 마지막으로, 이 명령어는 NVIDIA Docker 2를 시스템에 설치합니다. NVIDIA Docker 2는 Docker와 NVIDIA GPU 사이의 통합을 담당하는 소프트웨어다.
그런데 위에서도 말했듯이 사실 나는 Docker를 사용하지 않기로 했다. 위는 Docker를 통해 개발환경을 구축했을 때, GPU 가속을 지원하기 위한 절차이다. 물론 위 절차도 수행을 완료했지만, 나중에 사용하기 위함이었다. 나는 pipenv를 이용해서 Python 가상환경을 구축하고, 딥러닝 라이브러리를 설치하는 과정에서 자연스럽게 개발 환경 구축이 완성되었다. 이는 pipenv의 호환성 및 의존성 체크와 Linux의 강점이지 않나 싶다.
pipenv로 Python 개발 환경 구축하기
pipenv는 파이썬에서도 패키지를 프로젝트 단위로 관리를 할 수 있도록 도와주는 고급 패키지 관리 도구이다. 기본적으로 pip를 기반으로 동작하지만, 프로젝트 별로 격리된 가상 환경(virtual environment)과 프로젝트 단위의 패키지 관리 매커니즘을 제공한다.
pipenv 기본 설정
pip install pipenv
mkdir finance-python && cd finance-python
pipenv --python 3.10
여기서 finance-python은 프로젝트 이름이다. 설치할 수 있는 Python 버전은 실제로 설치가 되어있어야 한다. 나는 3.10 버전만 설치되어 있어 일단 호환성 및 의존성 문제는 없을 것이라 가정하고 3.10 버전으로 설치했다.
pipenv shell
그 다음 shell 명령어를 통해 가상환경을 터미널에서 사용할 수 있다. 또, 실제 Python 가상환경도 별도로 존재하여 주피터 커널로 사용할 수도 있다.
pipenv 패키지 설치
pipenv install transformers==4.3
Installing transformers==4.32.0...
Resolving transformers==4.32.0...
Added transformers to Pipfile's [packages] ...
✔ Installation Succeeded
이제 패키지 설치 시, 위처럼 기존에 pip를 통해 설치하던 작업을 pipenv로만 수정하면 된다. 자동으로 패키지가 버전을 자동 관리 해주기 때문에 호환성이나 의존성 문제에서 비교적 자유롭다고 느꼈다.
pipenv 추가 기능
pipenv에는 graph라는 기능이 존재하는데, 각 라이브러리 간의 호환성 및 의존성을 트리 형태로 볼 수 있다.
pipenv graph
bitsandbytes==0.41.2.post2
datasets==2.15.0
├── aiohttp [required: Any, installed: 3.9.0]
│ ├── aiosignal [required: >=1.1.2, installed: 1.3.1]
│ │ └── frozenlist [required: >=1.1.0, installed: 1.4.0]
│ ├── async-timeout [required: >=4.0,<5.0, installed: 4.0.3]
│ ├── attrs [required: >=17.3.0, installed: 23.1.0]
│ ├── frozenlist [required: >=1.1.1, installed: 1.4.0]
│ ├── multidict [required: >=4.5,<7.0, installed: 6.0.4]
│ └── yarl [required: >=1.0,<2.0, installed: 1.9.2]
│ ├── idna [required: >=2.0, installed: 3.4]
│ └── multidict [required: >=4.0, installed: 6.0.4]
├── dill [required: >=0.3.0,<0.3.8, installed: 0.3.7]
├── fsspec [required: >=2023.1.0,<=2023.10.0, installed: 2023.10.0]
├── huggingface-hub [required: >=0.18.0, installed: 0.19.4]
│ ├── filelock [required: Any, installed: 3.13.1]
│ ├── fsspec [required: >=2023.5.0, installed: 2023.10.0]
│ ├── packaging [required: >=20.9, installed: 23.2]
│ ├── pyyaml [required: >=5.1, installed: 6.0.1]
│ ├── requests [required: Any, installed: 2.31.0]
│ │ ├── certifi [required: >=2017.4.17, installed: 2023.11.17]
│ │ ├── charset-normalizer [required: >=2,<4, installed: 3.3.2]
│ │ ├── idna [required: >=2.5,<4, installed: 3.4]
│ │ └── urllib3 [required: >=1.21.1,<3, installed: 2.1.0]
│ ├── tqdm [required: >=4.42.1, installed: 4.66.1]
│ └── typing-extensions [required: >=3.7.4.3, installed: 4.8.0]
├── multiprocess [required: Any, installed: 0.70.15]
│ └── dill [required: >=0.3.7, installed: 0.3.7]
├── numpy [required: >=1.17, installed: 1.26.2]
├── packaging [required: Any, installed: 23.2]
├── pandas [required: Any, installed: 2.1.3]
│ ├── numpy [required: >=1.22.4,<2, installed: 1.26.2]
│ ├── python-dateutil [required: >=2.8.2, installed: 2.8.2]
│ │ └── six [required: >=1.5, installed: 1.16.0]
│ ├── pytz [required: >=2020.1, installed: 2023.3.post1]
│ └── tzdata [required: >=2022.1, installed: 2023.3]
├── pyarrow [required: >=8.0.0, installed: 14.0.1]
│ └── numpy [required: >=1.16.6, installed: 1.26.2]
├── pyarrow-hotfix [required: Any, installed: 0.5]
├── pyyaml [required: >=5.1, installed: 6.0.1]
├── requests [required: >=2.19.0, installed: 2.31.0]
│ ├── certifi [required: >=2017.4.17, installed: 2023.11.17]
│ ├── charset-normalizer [required: >=2,<4, installed: 3.3.2]
│ ├── idna [required: >=2.5,<4, installed: 3.4]
│ └── urllib3 [required: >=1.21.1,<3, installed: 2.1.0]
├── tqdm [required: >=4.62.1, installed: 4.66.1]
(...중략...)
또 pipenv은 Pipfile과 Pipfile.lock로 동료와 버전 공유를 할 수 있다. pip의 requirements.txt와 같은 역할을 한다고 생각하면 된다. 현재 내 Pipfile은 이렇게 구성되어 있다.
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
transformers = "==4.32.0"
peft = "*"
sentencepiece = "*"
accelerate = "*"
torch = "*"
datasets = "*"
bitsandbytes = "*"
scipy = "*"
ipykernel = "*"
jupyter = "*"
ipywidgets = "*"
google = "*"
protobuf = "*"
[dev-packages]
[requires]
python_version = "3.10"
python_full_version = "3.10.12"
결국 이렇게 WSL2를 통해 Llama를 로컬 환경에서 inference 하는 것에 성공했다.
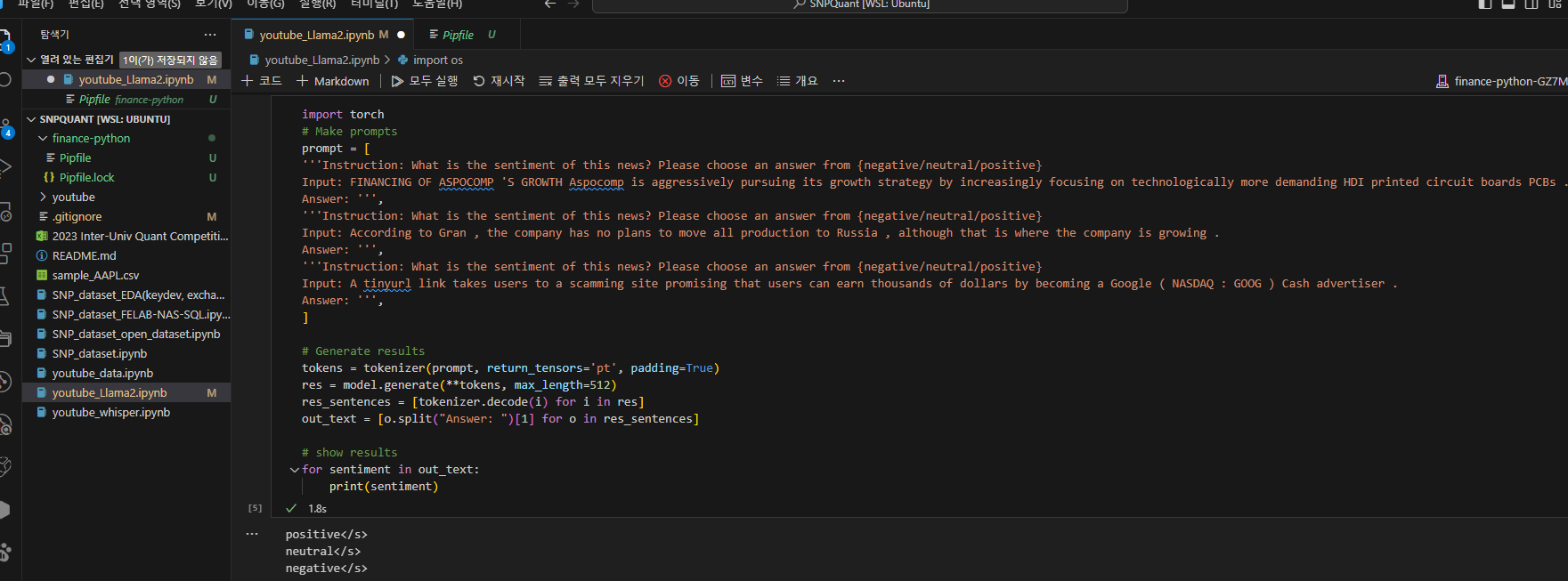
마무리하는 글
해당 글은 옵시디언으로 작성했다. 최근 옵시디언을 사용하려고 관련 자료를 많이 찾아보고 있는데 확실히 좋은 것 같으면서도 자잘한 세팅에서 어려움을 느끼고 있다. 유튜브를 통해서 가이드를 많이 받았었는데, 차라리 카페나 블로그 글을 정독하는 것이 더 도움될 것 같다. 더불어 이 글은 2023년 11월 20일 새벽 2시 32분에 마무리하며, 작성하는 데에는 약 3시간 정도 소요되었다.
많은 사람들이 지식관리론을 공부한다. 또, 지식을 관리하기 위해 효율적이라고 알려진 노트 앱들을 많이 사용한다. 노션을 사용하는 사람, 옵시디언을 사용하는 사람, 굿노트를 사용하는 사람처럼 각자의 취향이 존재하고 각 앱마다 장단점이 존재한다. 이러한 노트 앱과 마찬가지로 지식관리론의 핵심은 내가 얻은 지식을 얼마나 효율적으로 표현하는 것, 저장하는 것, 최종적으로 나의 장기·영구 기억으로 남기는 것에 있다.
그러나 많은 사람들이 이 지식관리론에 심취하고 빠져들어 효율성에만 매몰되고 있는 것 같다는 생각이 든다. 과거 오일러는 눈이 멀 때까지 계산을 하였고, 눈이 멀어서도 암산을 통해서 계산을 했다고 한다. 불과 30년 전만해도 인터넷이라는 것은 존재하지도 않았지만 인간사에 한 획을 긋는 연구과 논문은 항상 존재했다.
오류를 해결하기 위해 StackOverFlow이 아니라 ChatGPT에 의존하고, 효율적인 코드를 찾기 위해 Github을 탐색하는 것이 아니라 Copilot에 의존하고, 이론적 검증을 위해 논문과 책을 보는 것이 아니라 개인이 쓴 블로그 글에 의존하는 지금, 인간의 지식 생산 수준은 점점 수렴하고 있는 것이 아닐까. 감히 나는 개발자를 개발자 호소인과 진짜 개발자로 구분한다. 진짜 개발자는 자칭 개발자의 10%도 되지 않는 것 같다. 우리는 진짜 개발자가 되기 위해 끊임없이 노력해야 한다.
이렇게 AI의 수준이 높아지고 지식관리 기법이 보편화되면 모두의 능력은 상향 평준화 될 것 같다. 그 때가 되면 아마 제일 중요한 능력은 ‘주어진 문제를 해결을 위해 스스로 프로젝트를 이끌어 갈 수 있는가’가 되지 않을까? 그래서 더욱 글을 읽는 것과, 생각하는 것, 글을 쓰는 것이 중요해졌다. 항상 의심하고, 사색하고, 사유하고, 생각해야 하는 시대가 왔다. 이미 릴스와 숏츠는 인간의 도파민을 잠식하고 있다. 머지 않은 미래에는 숏폼을 만드는 1%, 숏폼을 시청하는 99%로 사람을 분류할 수 있을 것이다.
Comments