8. 정적 크롤링 실습하기#
각종 금융 웹사이트에는 주가, 재무정보 등 우리가 원하는 대부분의 주식 정보가 제공되고 있으며, 크롤링을 통해 이러한 데이터를 수집할 수 있다. 크롤링 혹은 스크래핑이란 웹사이트에서 원하는 정보를 수집하는 기술이다. 이번 장에서는 크롤링에 대한 간단한 설명과 예제를 살펴보겠다.
Note
크롤링을 할 때 주의해야 할 점이 있다. 특정 웹사이트의 페이지를 쉬지 않고 크롤링하는 행위를 무한 크롤링이라고 한다. 무한 크롤링은 해당 웹사이트의 자원을 독점하게 되어 타인의 사용을 막게 되며 웹사이트에 부하를 준다. 일부 웹사이트에서는 동일한 IP로 쉬지 않고 크롤링을 할 경우 접속을 막아버리는 경우도 있다. 따라서 하나의 페이지를 크롤링한 후 1~2초 가량 정지하고 다시 다음 페이지를 크롤링하는 것이 좋다.
또한 신문기사나 책, 논문, 사진 등 저작권이 있는 자료를 통해 부당이득을 얻는다는 등의 행위를 할 경우 법적 제재를 받을 수 있다.
이 책에서 설명하는 크롤링을 통해, 상업적 가치가 있는 데이터에 접근을 시도하여 발생할 수 있는 어떠한 상황에 대해서도 책임을 질 수 없다는 점을 명심하기 바란다.
8.1. GET과 POST 방식 이해하기#
우리가 인터넷에 접속해 서버에 파일을 요청(Request)하면, 서버는 이에 해당하는 파일을 우리에게 보내준다(Response). 크롬과 같은 웹 브라우저는 이러한 과정을 사람이 수행하기 편하고 시각적으로 보기 편하도록 만들어진 것이며, 인터넷 주소는 서버의 주소를 기억하기 쉽게 만든 것이다. 우리가 서버에 데이터를 요청하는 형태는 다양하지만 크롤링에서는 주로 GET과 POST 방식을 사용한다.
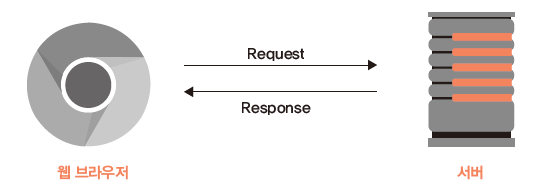
Fig. 8.1 클라이언트와 서버 간의 요청/응답 과정#
8.1.1. GET 방식#
GET 방식은 인터넷 주소를 기준으로 이에 해당하는 데이터나 파일을 요청하는 것이다. 주로 클라이언트가 요청하는 쿼리를 앰퍼샌드(&) 혹은 물음표(?) 형식으로 결합해 서버에 전달한다.
네이버 홈페이지에 접속한 후 [퀀트]를 검색하면, 주소 끝부분에 [&query=퀀트]가 추가되며 이에 해당하는 페이지의 내용을 보여준다. 즉, 해당 페이지는 GET 방식을 사용하고 있으며 입력 종류는 query, 입력값은 퀀트임을 알 수 있다.
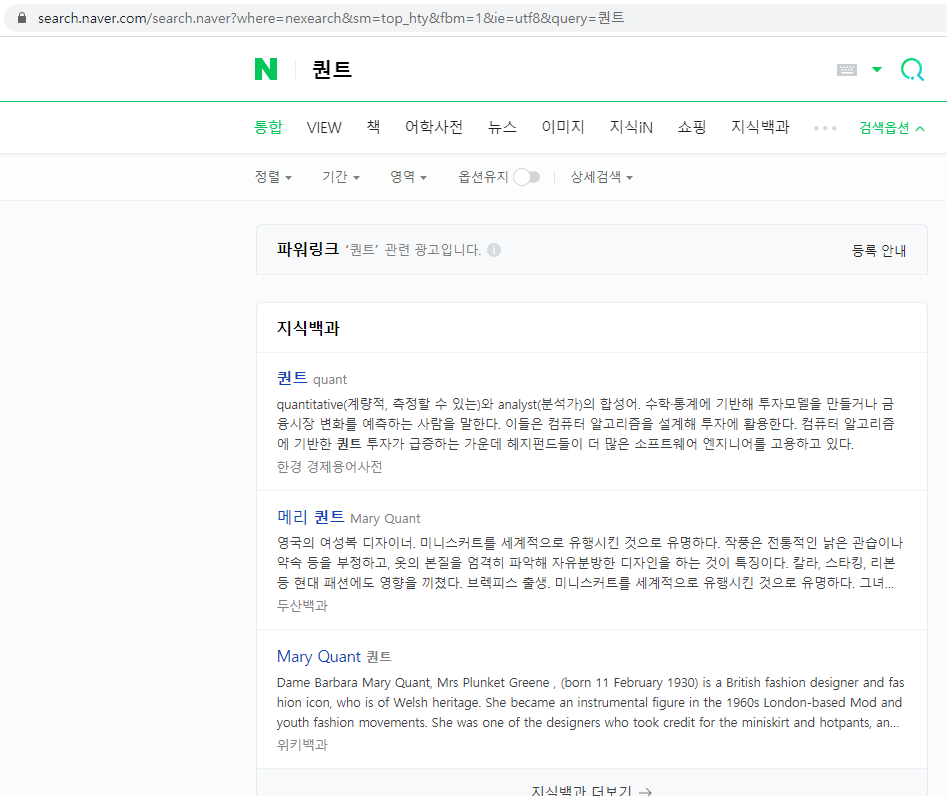
Fig. 8.2 네이버 검색 결과#
[헤지펀드]를 다시 검색하면, 주소 끝부분이 [&query=헤지펀드&oquery=퀀트…]로 변경된다. 현재 입력값은 헤지펀드, 기존 입력값은 퀀트이며 이러한 과정을 통해 연관검색어가 생성됨도 유추해볼 수 있다.
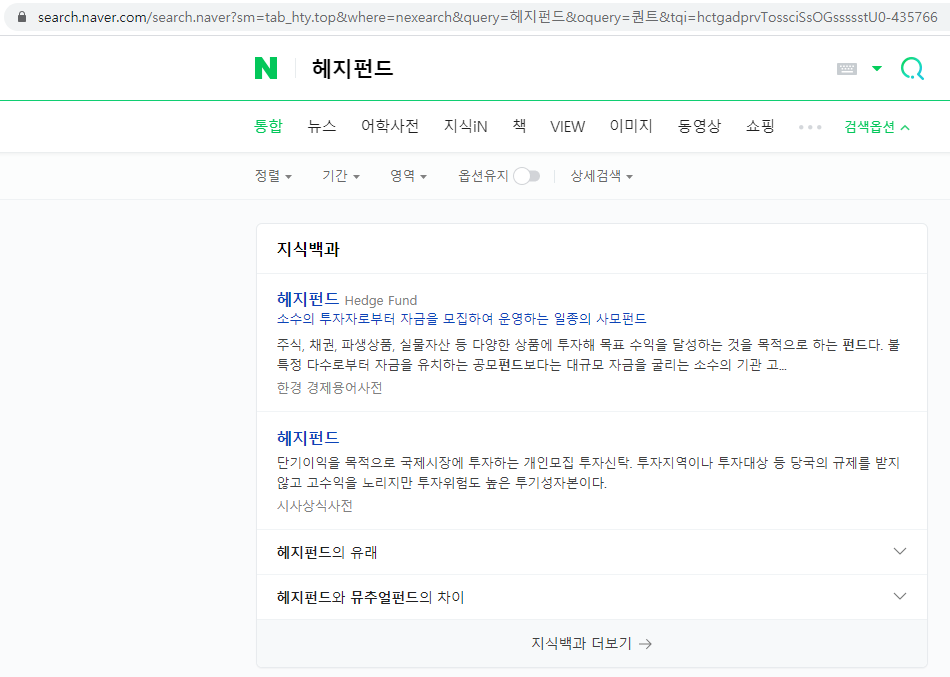
Fig. 8.3 네이버 재검색 결과#
8.1.2. POST 방식#
POST 방식은 사용자가 필요한 값을 추가해서 요청하는 방법이다. GET 방식과 달리 클라이언트가 요청하는 쿼리를 body에 넣어서 전송하므로 요청 내역을 직접 볼 수 없다. 동행복권 홈페이지에 접속해 [당첨결과] 메뉴를 확인해보자.
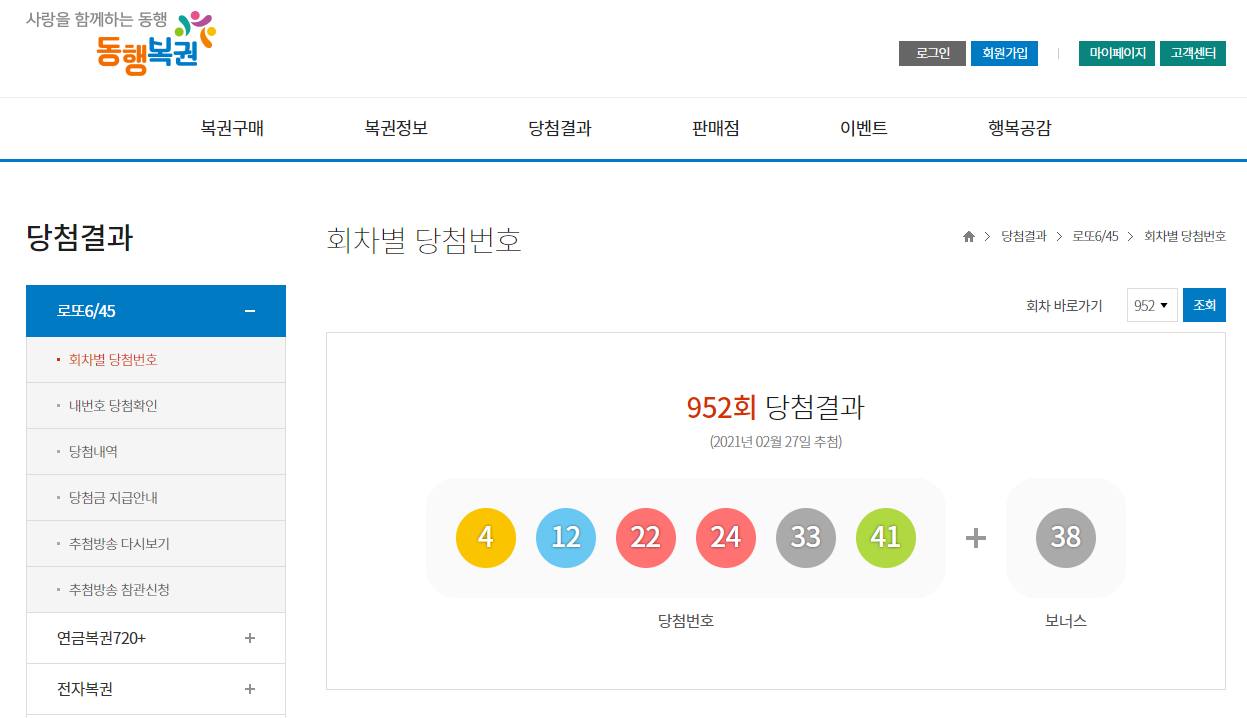
Fig. 8.4 회차별 당첨번호#
이번엔 회차 바로가기를 변경한 후 [조회]를 클릭한다. 페이지의 내용은 선택일 기준으로 변경되었지만, 주소는 변경되지 않고 그대로 남아 있다. GET 방식에서는 입력 항목에 따라 웹페이지 주소가 변경되었지만, POST 방식을 사용해 서버에 데이터를 요청하는 해당 웹사이트는 그렇지 않은 것을 알 수 있다.
POST 방식의 데이터 요청 과정을 살펴보려면 개발자도구를 이용해야 하며, 크롬에서는 [F12]키를 눌러 개발자도구 화면을 열 수 있다. 개발자도구 화면을 연 상태에서 다시 한번 [조회]를 클릭해보자. [Network] 탭을 클릭하면, [조회]을 클릭함과 동시에 브라우저와 서버 간의 통신 과정을 살펴볼 수 있다. 이 중 상단의 gameResult.do?method=byWin 이라는 항목이 POST 형태임을 알 수 있다.
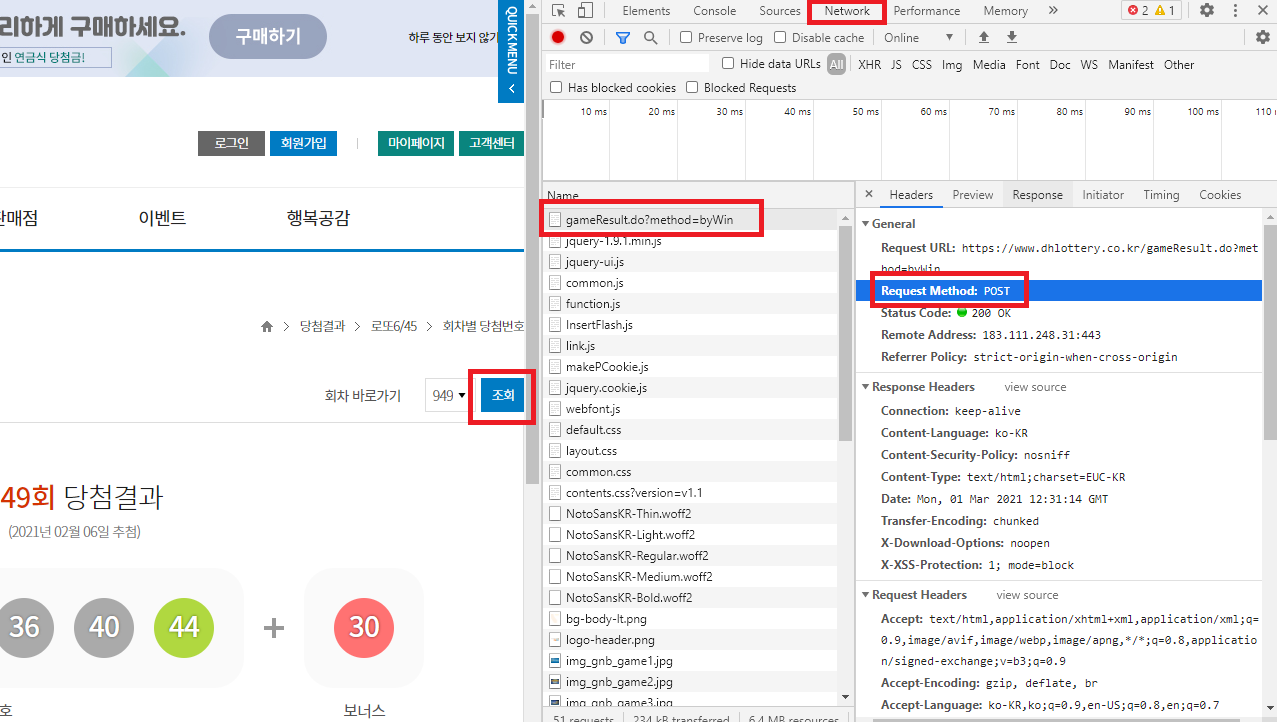
Fig. 8.5 크롬 개발자도구의 Network 화면#
해당 메뉴를 클릭하면 통신 과정을 좀 더 자세히 알 수 있다. [Payload] 탭의 [Form Data]에는 서버에 데이터를 요청하는 내역이 있다. drwNo와 dwrNoList에는 선택한 회차의 숫자가 들어가있다.
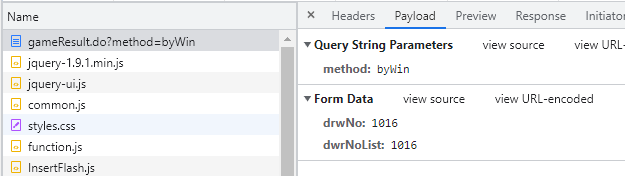
Fig. 8.6 POST 방식의 서버 요청 내역#
이처럼 POST 방식은 요청하는 데이터에 대한 쿼리가 GET 방식처럼 URL을 통해 전송되는 것이 아닌 body를 통해 전송되므로, 이에 대한 정보는 웹 브라우저를 통해 확인할 수 없으며, 개발자도구 화면을 통해 확인해야 한다.
8.2. 크롤링 예제#
일반적으로 크롤링은 Fig. 8.7의 과정을 따른다. 먼저, request 패키지의 get() 혹은 post() 함수를 이용해 데이터를 요청한 후 HTML을 정보를 가져오며, bs4 패키지의 함수들을 이용해 원하는 데이터를 찾는 과정으로 이루어진다. 기본적인 크롤링을 시작으로 GET 방식과 POST 방식으로 데이터를 받는 예제를 학습해 보겠다.
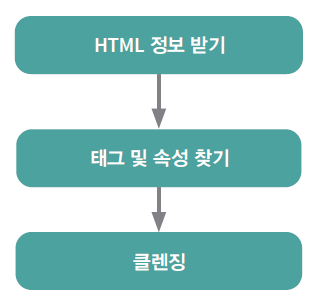
Fig. 8.7 일반적인 크롤링 과정#
8.2.1. 명언 크롤링하기#
크롤링의 간단한 예제로 ‘Quotes to Scrape’ 사이트에 있는 명언을 수집하겠다.
https://quotes.toscrape.com/
해당사이트에 접속한 후, 명언에 해당하는 부분에 마우스 커서를 올려둔 후 마우스 오른쪽 버튼을 클릭하고 [검사]를 선택하면 개발자도구 화면이 나타난다. 여기서 해당 글자가 HTML 내에서 어떤 부분에 위치하는지 확인할 수 있다.
각 네모에 해당하는 부분: [class가 quote인 div 태그]
명언: 위의 태그 하부의 [class가 text인 span 태그]
말한 사람은 [span 태그 하단의 class가 author인 small 태그]
말한 사람에 대한 정보인 about의 링크: [a 태그 href 속성]의 속성값
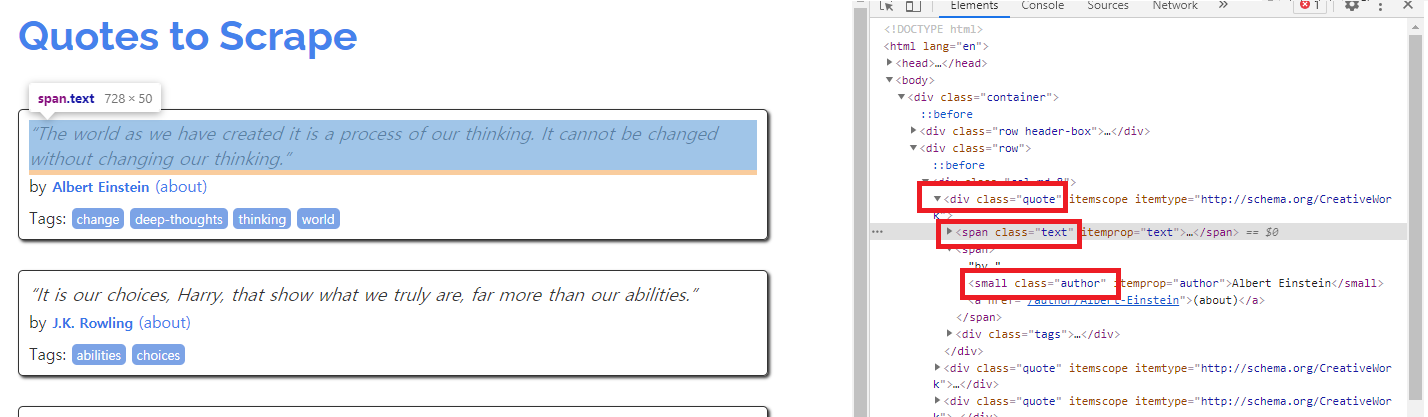
Fig. 8.8 Quotes to Scrape의 명언부분 HTML#
이제 위의 내용을 하나씩 크롤링 해보도록 하자. 먼저 해당 페이지의 내용을 불러온다.
import requests as rq
url = 'https://quotes.toscrape.com/'
quote = rq.get(url)
print(quote)
<Response [200]>
url에 해당 주소를 입력한 후 get() 함수를 이용해 해당 페이지의 내용을 받았다. 이를 확인해보면 Response가 200, 즉 데이터가 이상 없이 받아졌음이 확인된다.
quote.content[:1000]
b'<!DOCTYPE html>\n<html lang="en">\n<head>\n\t<meta charset="UTF-8">\n\t<title>Quotes to Scrape</title>\n <link rel="stylesheet" href="/static/bootstrap.min.css">\n <link rel="stylesheet" href="/static/main.css">\n</head>\n<body>\n <div class="container">\n <div class="row header-box">\n <div class="col-md-8">\n <h1>\n <a href="/" style="text-decoration: none">Quotes to Scrape</a>\n </h1>\n </div>\n <div class="col-md-4">\n <p>\n \n <a href="/login">Login</a>\n \n </p>\n </div>\n </div>\n \n\n<div class="row">\n <div class="col-md-8">\n\n <div class="quote" itemscope itemtype="http://schema.org/CreativeWork">\n <span class="text" itemprop="text">\xe2\x80\x9cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\xe2\x80\x9d</span>\n <span>by <small class="author" it'
content를 통해 함수를 통해 받아온 내용을 확인할 수 있으며, 텍스트 형태로 이루어져있다. BeautifulSoup() 함수를 이용해 원하는 HTML 요소에 접근하기 쉬운 BeautifulSoup 객체로 변경할 수 있다.
from bs4 import BeautifulSoup
quote_html = BeautifulSoup(quote.content, 'html.parser')
quote_html.head()
[<meta charset="utf-8"/>,
<title>Quotes to Scrape</title>,
<link href="/static/bootstrap.min.css" rel="stylesheet"/>,
<link href="/static/main.css" rel="stylesheet"/>]
BeautifulSoup() 함수 내에 HTML 정보에 해당하는 quote.content와 파싱 방법에 해당하는 html.parser를 입력하면 개발자도구 화면에서 보던 것과 비슷한 형태인 BeautifulSoup 객체로 변경되며, 이를 통해 원하는 요소의 데이터를 읽어올 수 있다.
Note
BeautifulSoup() 함수는 다양한 파서를 지원하며, 그 내용은 다음과 같다.
Parser |
선언방법 |
장점 |
단점 |
|---|---|---|---|
html.parser |
|
설치할 필요 없음 |
|
lxml HTML parser |
|
매우 빠름 |
lxml 추가 설치 필요 |
lxml XML parser |
|
매우 빠름 |
lxml 추가 설치 필요 |
html5lib |
|
웹 브라우저와 같은 방식으로 페이지 파싱. |
html5lib 추가 설치 필요 |
8.2.1.1. find() 함수를 이용한 크롤링#
먼저 BeautifulSoup 모듈의 find() 함수를 통해 크롤링 하는법을 알아보자. 우리는 개발자도구 화면에서 명언에 해당하는 부분이 [class가 quote인 div 태그 → class가 text인 span 태그]에 위치하고 있음을 살펴보았다. 이를 활용해 명언만을 추출하는 방법은 다음과 같다.
quote_div = quote_html.find_all('div', class_='quote')
quote_div[0]
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="change,deep-thoughts,thinking,world" itemprop="keywords"/>
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
find_all() 함수를 이용할 경우 원하는 태그의 내용들을 찾아올 수 있다. 먼저 태그에 해당하는 ‘div’를 입력하고, class 이름인 ‘quote’를 입력한다. class라는 키워드는 파이썬에서 클래스를 만들 때 사용하는 키워드이므로 언더바(_)를 통해 중복을 피해준다. 조건에 만족하는 결과가 리스트 형태로 반환되므로, 첫번째 내용만 확인해보면 div class="quote"에 해당하는 내용을 찾아왔으며, 이제 여기서 [class가 text인 span 태그]에 해당하는 내용을 추가로 찾도록 하자.
quote_span = quote_div[0].find_all('span', class_='text')
quote_span
[<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>]
다시 한번 find_all() 함수를 이용해 원하는 부분('span', class_='text')을 입력하면 우리가 원하던 명언에 해당하는 내용이 찾아진다.
quote_span[0].text
'“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'
결과물 마지막에 .text를 입력하면 텍스트 데이터만을 출력할 수 있다. for문 중에서 리스트 내포 형태를 이용하여 명언에 해당하는 부분을 한번에 추출해보도록 하자.
quote_div = quote_html.find_all('div', class_ = 'quote')
[i.find_all('span', class_ ='text')[0].text for i in quote_div]
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
'“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”',
"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”",
'“Try not to become a man of success. Rather become a man of value.”',
'“It is better to be hated for what you are than to be loved for what you are not.”',
"“I have not failed. I've just found 10,000 ways that won't work.”",
"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”",
'“A day without sunshine is like, you know, night.”']
Note
find_all() 함수가 아닌 find() 함수를 사용하면 해당 태그의 첫번째 내용만을 가져온다.
8.2.1.2. select() 함수를 이용한 크롤링#
위 예제에서는 간단하게 원하는 데이터를 찾았지만, 데이터가 존재하는 곳의 태그를 여러번 찾아 내려가야 할 경우 find_all() 함수를 이용하는 방법은 매우 번거롭다. select() 함수의 경우 좀더 쉬운 방법으로 원하는 데이터가 존재하는 태그를 입력할 수 있다. 위의 동일한 내용을 select() 함수를 이용해 크롤링해보도록 하자.
quote_text = quote_html.select('div.quote > span.text')
quote_text
[<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>,
<span class="text" itemprop="text">“It is our choices, Harry, that show what we truly are, far more than our abilities.”</span>,
<span class="text" itemprop="text">“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”</span>,
<span class="text" itemprop="text">“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”</span>,
<span class="text" itemprop="text">“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”</span>,
<span class="text" itemprop="text">“Try not to become a man of success. Rather become a man of value.”</span>,
<span class="text" itemprop="text">“It is better to be hated for what you are than to be loved for what you are not.”</span>,
<span class="text" itemprop="text">“I have not failed. I've just found 10,000 ways that won't work.”</span>,
<span class="text" itemprop="text">“A woman is like a tea bag; you never know how strong it is until it's in hot water.”</span>,
<span class="text" itemprop="text">“A day without sunshine is like, you know, night.”</span>]
select() 함수 내에 찾고자 하는 태그를 입력하며, 클래스명이 존재할 경우 점(.)을 붙여준다. 또한 여러 태그를 찾아 내려가야할 경우 > 기호를 이용해 순서대로 입력해주면 된다. 즉 ‘div.quote > span.text’는 [class가 quote인 div 태그] 중에서 [class가 text인 span 태그]를 찾는다. 이제 텍스트 데이터만 추출해보도록 하자.
quote_text_list = [i.text for i in quote_text]
quote_text_list
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
'“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”',
"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”",
'“Try not to become a man of success. Rather become a man of value.”',
'“It is better to be hated for what you are than to be loved for what you are not.”',
"“I have not failed. I've just found 10,000 ways that won't work.”",
"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”",
'“A day without sunshine is like, you know, night.”']
find_all() 함수를 이용한 것 보다 훨씬 간단하게 원하는 데이터를 찾을 수 있었다.
이번에는 명언을 말한 사람 역시 크롤링해보도록 하자. 해당 데이터는 [class가 quote인 div 태그] 하단의 [span 태그], 다시 하단의 [class가 author인 small 태그]에 위치하고 있다.
quote_author = quote_html.select('div.quote > span > small.author')
quote_author_list = [i.text for i in quote_author]
quote_author_list
['Albert Einstein',
'J.K. Rowling',
'Albert Einstein',
'Jane Austen',
'Marilyn Monroe',
'Albert Einstein',
'André Gide',
'Thomas A. Edison',
'Eleanor Roosevelt',
'Steve Martin']
위와 동일한 방법을 이용해 말한 사람 역시 손쉽게 추출이 가능합니다.
마지막으로 말한 사람에 대한 정보인 (about)에 해당하는 링크도 추출해보자. 해당 주소는 [class가 quote인 div 태그] 하단의 [span 태그], 다시 하단의 [a 태그의 href 속성] 중 속성값에 위치하고 있다.
quote_link = quote_html.select('div.quote > span > a')
quote_link
[<a href="/author/Albert-Einstein">(about)</a>,
<a href="/author/J-K-Rowling">(about)</a>,
<a href="/author/Albert-Einstein">(about)</a>,
<a href="/author/Jane-Austen">(about)</a>,
<a href="/author/Marilyn-Monroe">(about)</a>,
<a href="/author/Albert-Einstein">(about)</a>,
<a href="/author/Andre-Gide">(about)</a>,
<a href="/author/Thomas-A-Edison">(about)</a>,
<a href="/author/Eleanor-Roosevelt">(about)</a>,
<a href="/author/Steve-Martin">(about)</a>]
이 중에서 우리는 속성값에 해당하는 정보만 필요하다. 속성값의 경우 HTML 정보 뒤에 [‘속성’]을 입력하면 추출할 수 있다.
quote_link[0]['href']
'/author/Albert-Einstein'
모든 속성값을 한 번에 추출한 후, 완전한 URL을 만들기 위해 주소 부분도 합쳐주도록 하자.
['https://quotes.toscrape.com' + i['href'] for i in quote_link]
['https://quotes.toscrape.com/author/Albert-Einstein',
'https://quotes.toscrape.com/author/J-K-Rowling',
'https://quotes.toscrape.com/author/Albert-Einstein',
'https://quotes.toscrape.com/author/Jane-Austen',
'https://quotes.toscrape.com/author/Marilyn-Monroe',
'https://quotes.toscrape.com/author/Albert-Einstein',
'https://quotes.toscrape.com/author/Andre-Gide',
'https://quotes.toscrape.com/author/Thomas-A-Edison',
'https://quotes.toscrape.com/author/Eleanor-Roosevelt',
'https://quotes.toscrape.com/author/Steve-Martin']
8.2.1.3. 모든 페이지 데이터 크롤링하기#
화면 하단의 [Next→] 부분을 클릭하면 URL이 https://quotes.toscrape.com/page/2/ 로 바뀌며 다음 페이지의 내용이 나타난다. 이처럼 웹페이지 하단에서 다음 페이지 혹은 이전 페이지로 넘어가게 해주는 것을 흔히 페이지네이션이라고 한다.

Fig. 8.9 페이지네이션#
URL의 ‘page/’ 뒤에 위치하는 숫자를 for문을 이용해 바꿔준다면, 모든 페이지의 데이터를 크롤링할 수 있다.
import requests as rq
from bs4 import BeautifulSoup
import time
text_list = []
author_list = []
infor_list = []
for i in range(1, 100):
url = f'https://quotes.toscrape.com/page/{i}/'
quote = rq.get(url)
quote_html = BeautifulSoup(quote.content, 'html.parser')
quote_text = quote_html.select('div.quote > span.text')
quote_text_list = [i.text for i in quote_text]
quote_author = quote_html.select('div.quote > span > small.author')
quote_author_list = [i.text for i in quote_author]
quote_link = quote_html.select('div.quote > span > a')
qutoe_link_list = ['https://quotes.toscrape.com' + i['href'] for i in quote_link]
if len(quote_text_list) > 0:
text_list.extend(quote_text_list)
author_list.extend(quote_author_list)
infor_list.extend(qutoe_link_list)
time.sleep(1)
else:
break
명언과 말한 사람, 링크가 들어갈 빈 리스트(text_list, author_list, infor_list)를 만든다.
for문을 1부터 100까지 적용하여 URL을 생성한다.
HTML 정보를 받아온 후
BeautifulSoup()함수를 통해 파싱한다.명언과 말한 사람, 링크에 해당하는 내용을 각각 추출한다.
해당 웹페이지는 10페이지까지 데이터가 존재하며, 11페이지부터는 아무런 내용이 없다. 그러나 이러한 정보는 사전에 알 수 없기에 만약 데이터가 있는 경우 위에서 생성한 리스트에
extend()함수를 사용하여 데이터를 추가하며, 그렇지 않을 경우break를 통해 for문을 종료한다.한 번 루프가 돌때마다 1초간 정지를 준다.
text_list와 author_list, infor_list를 확인해보면 모든 페이지의 내용이 저장되어 있다. 이제 크롤링 한 내용을 데이터프레임 형태로 만들도록 한다.
import pandas as pd
pd.DataFrame({'text': text_list, 'author': author_list, 'infor': infor_list})
| text | author | infor | |
|---|---|---|---|
| 0 | “The world as we have created it is a process ... | Albert Einstein | https://quotes.toscrape.com/author/Albert-Eins... |
| 1 | “It is our choices, Harry, that show what we t... | J.K. Rowling | https://quotes.toscrape.com/author/J-K-Rowling |
| 2 | “There are only two ways to live your life. On... | Albert Einstein | https://quotes.toscrape.com/author/Albert-Eins... |
| 3 | “The person, be it gentleman or lady, who has ... | Jane Austen | https://quotes.toscrape.com/author/Jane-Austen |
| 4 | “Imperfection is beauty, madness is genius and... | Marilyn Monroe | https://quotes.toscrape.com/author/Marilyn-Monroe |
| ... | ... | ... | ... |
| 95 | “You never really understand a person until yo... | Harper Lee | https://quotes.toscrape.com/author/Harper-Lee |
| 96 | “You have to write the book that wants to be w... | Madeleine L'Engle | https://quotes.toscrape.com/author/Madeleine-L... |
| 97 | “Never tell the truth to people who are not wo... | Mark Twain | https://quotes.toscrape.com/author/Mark-Twain |
| 98 | “A person's a person, no matter how small.” | Dr. Seuss | https://quotes.toscrape.com/author/Dr-Seuss |
| 99 | “... a mind needs books as a sword needs a whe... | George R.R. Martin | https://quotes.toscrape.com/author/George-R-R-... |
100 rows × 3 columns
8.2.2. 금융 속보 크롤링#
이번에는 금융 속보의 제목을 추출해보겠다. 먼저 네이버 금융에 접속한 후 [뉴스 → 실시간 속보]를 선택하며, URL은 다음과 같다.
https://finance.naver.com/news/news_list.nhn?mode=LSS2D§ion_id=101§ion_id2=258
이 중 뉴스의 제목에 해당하는 텍스트만 추출해보도록 하자. 개발자도구 화면을 통헤 제목에 해당하는 부분은 [dl 태그 → class가 articleSubject 인 dd 태그 → a 태그 중 title 속성]에 위치하고 있음을 확인할 수 있다.
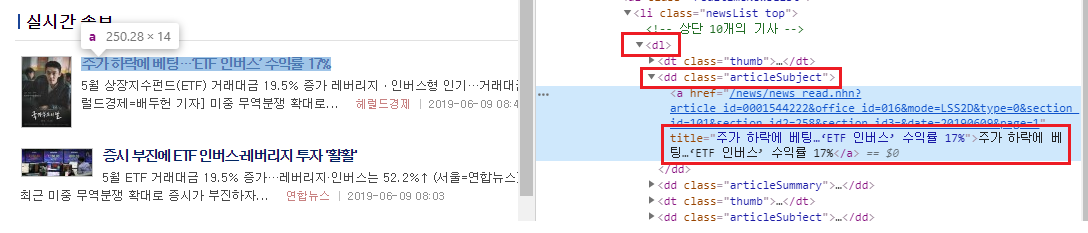
Fig. 8.10 실시간 속보의 제목 부분 HTML#
import requests as rq
from bs4 import BeautifulSoup
url = 'https://finance.naver.com/news/news_list.nhn?mode=LSS2D§ion_id=101§ion_id2=258'
data = rq.get(url)
html = BeautifulSoup(data.content, 'html.parser')
html_select = html.select('dl > dd.articleSubject > a')
html_select[0:3]
[<a href="/news/news_read.naver?article_id=0013357016&office_id=001&mode=LSS2D&type=0§ion_id=101§ion_id2=258§ion_id3=&date=20220805&page=1" title="코스피 0.72% 상승한 2,490대 마감">코스피 0.72% 상승한 2,490대 마감</a>,
<a href="/news/news_read.naver?article_id=0000009613&office_id=648&mode=LSS2D&type=0§ion_id=101§ion_id2=258§ion_id3=&date=20220805&page=1" title='"국내는 좁다" 롯데헬스케어, 프리미엄 웰니스 글로벌 정조준'>"국내는 좁다" 롯데헬스케어, 프리미엄 웰니스 글로벌 정조준</a>,
<a href="/news/news_read.naver?article_id=0006261884&office_id=421&mode=LSS2D&type=0§ion_id=101§ion_id2=258§ion_id3=&date=20220805&page=1" title="[코스피] 17.69p(0.72%) 오른 2490.8 마감">[코스피] 17.69p(0.72%) 오른 2490.8 마감</a>]
get()함수를 이용해 페이지의 내용을 받아온다.BeautifulSoup()함수를 통해 HTML 정보를 BeautifulSoup 객체로 만든다.select()함수를 통해 원하는 태그로 접근해 들어간다.
출력된 내용을 살펴 보면 우리가 원하는 제목은 title 속성에 위치하고 있다.
html_select[0]['title']
'코스피 0.72% 상승한 2,490대 마감'
속성값에 해당하는 내용을 추출했다. 이제 for문으로 묶어 한번에 제목들을 추출하도록 하겠다.
[i['title'] for i in html_select]
['코스피 0.72% 상승한 2,490대 마감',
'"국내는 좁다" 롯데헬스케어, 프리미엄 웰니스 글로벌 정조준',
'[코스피] 17.69p(0.72%) 오른 2490.8 마감',
'[코스닥] 6.48p(0.79%) 오른 831.64 마감',
'[달러/원] 환율 11.8원 내린 1298.3원 마감',
'[속보] 코스피, 17.69포인트(0.72%) 오른 2490.80 마감',
'셀트리온, 셀트리온헬스케어에 미국 법인 매각[주목 e공시]']
8.2.3. 테이블 크롤링하기#
우리가 크롤링하고자 하는 데이터가 테이블 형태로 제공될 경우, 위와 같이 복잡한 과정을 거칠 필요 없이 매우 간단하게 테이블에 해당하는 내용만 가져올 수 있다. 먼저 아래 사이트에는 각 국가별 GDP가 테이블 형태로 제공되고 있다.
https://en.wikipedia.org/wiki/List_of_countries_by_stock_market_capitalization
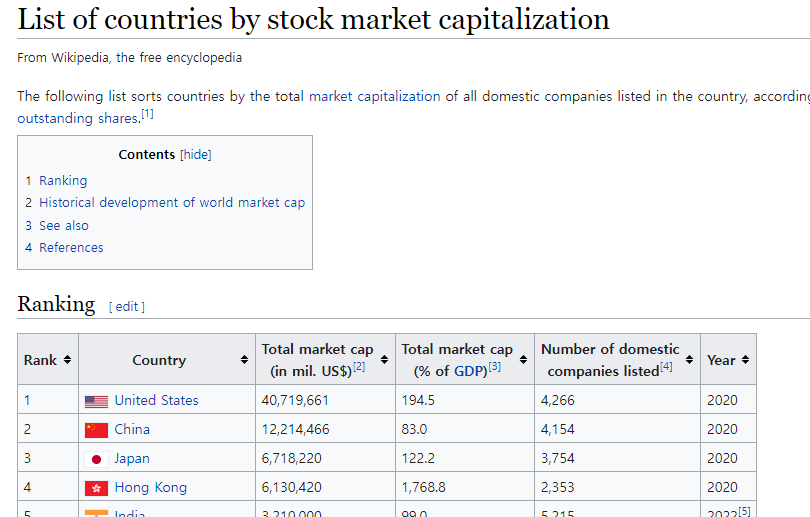
Fig. 8.11 국가별 시가총액 데이터#
해당 내역을 크롤링하는 법은 매우 간단하다.
import pandas as pd
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_stock_market_capitalization'
tbl = pd.read_html(url)
tbl[0].head()
| Rank | Country | Total market cap(in mil. US$)[2] | Total market cap(% of GDP)[3] | Number of domesticcompanies listed[4] | Year | |
|---|---|---|---|---|---|---|
| 0 | 1 | United States | 40719661 | 194.5 | 4266 | 2020 |
| 1 | 2 | China | 12214466 | 83.0 | 4154 | 2020 |
| 2 | 3 | Japan | 6718220 | 122.2 | 3754 | 2020 |
| 3 | 4 | Hong Kong | 6130420 | 1768.8 | 2353 | 2020 |
| 4 | 5 | India | 3210000 | 99.0 | 5215 | 2022[5] |
URL을 입력한다.
pandas 패키지의
read_html()함수에 URL을 입력하면, 해당 페이지에 존재하는 테이블을 가져온 후 데이터프레임 형태로 불러온다.
이처럼 테이블 형태로 존재하는 데이터는 HTML 정보를 불러온 후 태그와 속성을 찾을필요 없이 read_html() 함수를 이용해 매우 손쉽게 불러올 수 있다.
8.2.4. 기업공시채널에서 오늘의 공시 불러오기#
한국거래소 상장공시시스템(kind.krx.co.kr)에 접속한 후 [오늘의 공시 → 전체 → 더보기]를 선택해 전체 공시내용을 확인할 수 있다.
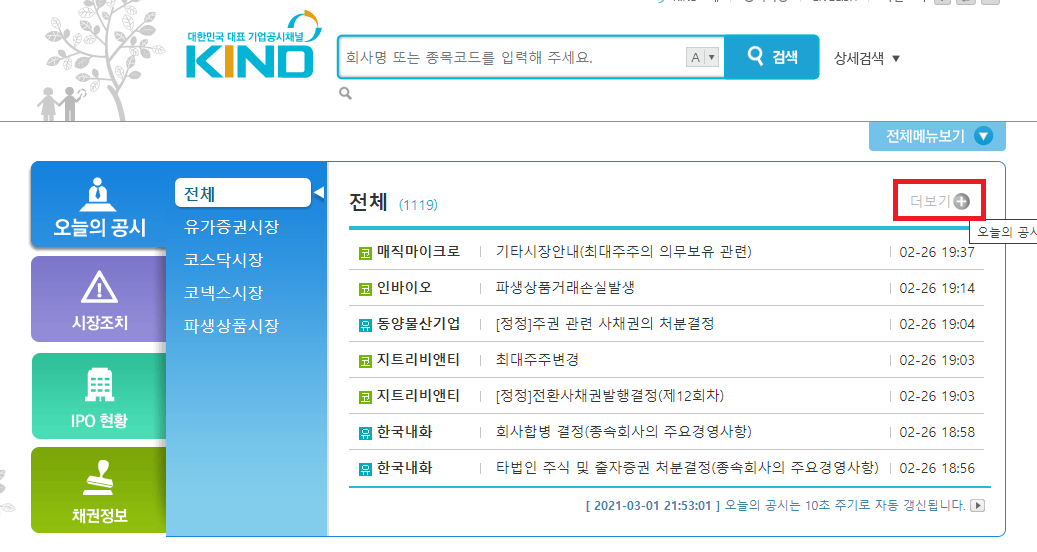
Fig. 8.12 오늘의공시 확인하기#
해당 페이지에서 날짜를 변경한 후 [검색]을 누르면, 페이지의 내용은 해당일의 공시로 변경되지만 URL은 변경되지 않는다. 이처럼 POST 방식은 요청하는 데이터에 대한 쿼리가 body의 형태를 통해 전송되므로, 개발자도구 화면을 통해 해당 쿼리에 대한 내용을 확인해야 한다.
개발자도구 화면을 연 상태에서 조회일자를 원하는 날짜로 선택, [검색]을 클릭한 후 [Network] 탭의 todaydisclosure.do 항목에서 [Headers]탭의 [General] 부분에는 데이터를 요청하는 서버 주소가, [Payload] 탭의 [Form Data]를 통해 서버에 데이터를 요청하는 내역을 확인할 수 있다. 여러 항목 중 selDate 부분이 우리가 선택한 일자로 설정되어 있다.
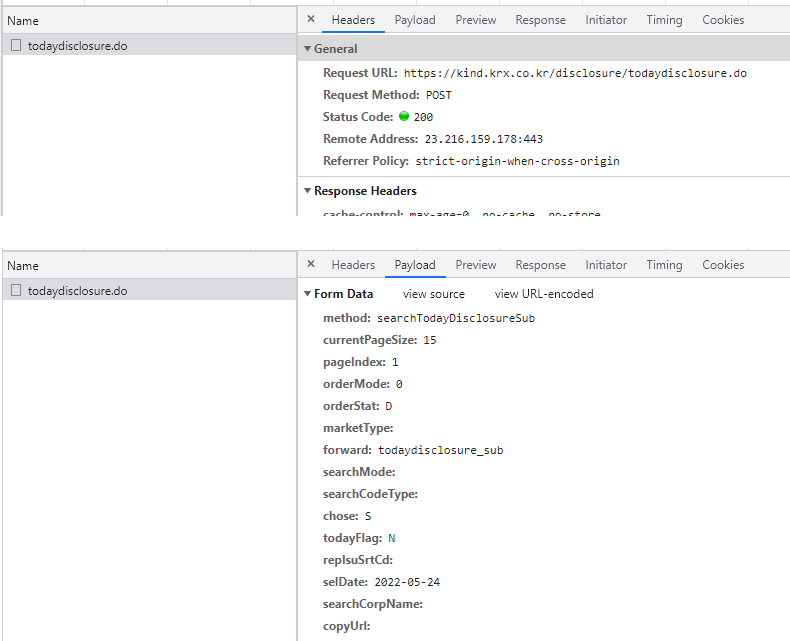
Fig. 8.13 POST 방식의 데이터 요청#
POST 방식으로 쿼리를 요청하는 방법을 코드로 나타내면 다음과 같다.
import requests as rq
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://kind.krx.co.kr/disclosure/todaydisclosure.do'
payload = {
'method': 'searchTodayDisclosureSub',
'currentPageSize': '15',
'pageIndex': '1',
'orderMode': '0',
'orderStat': 'D',
'forward': 'todaydisclosure_sub',
'chose': 'S',
'todayFlag': 'N',
'selDate': '2022-07-27'
}
data = rq.post(url, data=payload)
html = BeautifulSoup(data.content, 'html.parser')
# print(html)
URL과 쿼리를 입력한다. 쿼리는 딕셔너리 형태로 입력하며, Form Data와 동일하게 입력해준다. 쿼리 중 marketType과 같이 값이 없는 항목은 입력하지 않아도 된다.
POST()함수를 통해 해당 URL에 원하는 쿼리를 요청한다.BeautifulSoup()함수를 통해 파싱한다.
읽어온 데이터를 확인해보면 엑셀 데이터가 HTML 형태로 나타나있다. 따라서 이를 변형해 데이터프레임 형태로 불러오도록 한다.
html_unicode = html.prettify()
tbl = pd.read_html(html.prettify())
tbl[0].head()
| Unnamed: 0 | Unnamed: 1 | Unnamed: 2 | Unnamed: 3 | Unnamed: 4 | |
|---|---|---|---|---|---|
| 0 | 19:08 | 지나인제약 | 기타시장안내(상장적격성 실질심사 사유추가 안내) | 코스닥시장본부 | 공시차트 주가차트 |
| 1 | 19:00 | 지나인제약 | 최대주주변경 | 지나인제약 | 공시차트 주가차트 |
| 2 | 18:57 | 지나인제약 | 최대주주 변경을 수반하는 주식 담보제공 계약 체결 | 지나인제약 | 공시차트 주가차트 |
| 3 | 18:45 | 디딤 | [정정] 최대주주 변경을 수반하는 주식 담보제공 계약 체결 | 디딤 | 공시차트 주가차트 |
| 4 | 18:39 | 케이옥션 | 추가상장(무상증자) | 코스닥시장본부 | 공시차트 주가차트 |
prettify()함수를 이용해 BeautifulSoup 에서 파싱한 파서 트리를 유니코드 형태로 다시 돌려준다.read_html()함수를 통해 테이블을 읽어온다.
데이터를 확인하면 화면과 동일한 내용이 들어가있다. POST 형식의 경우 쿼리 내용을 바꾸어 원하는 데이터를 받을 수 있다. 만일 다른 날짜의 공시를 확인하고자 한다면 위의 코드에서 ‘selDate’만 해당일로 변경해주면 된다.