2. 파이썬 기초 배워보기#
이번 장에서는 변수와 상수, 데이터의 타입, 제어문, 함수 등 기본적인 파이썬 문법과 패키지를 사용하는 방법에 대해 살펴보도록 하겠다.
2.1. 상수와 변수#
프로그래밍의 가장 기본은 상수와 변수이다. 먼저 아래의 코드를 실행해보자.
var = 10
print(var)
10
10 이라는 숫자 혹은 문자와 같은 값 자체를 상수(constant)라고 한다. 반면 이러한 상수가 저장된 공간인 var는 변수(variable)라고 한다. var = 10은 var라는 변수에 10을 할당(저장)하라는 의미다. print()는 결과물을 출력하는 함수로써, var의 내용을 출력한다.
var = 'Hello World'
print(var)
Hello World
var라는 변수에 새롭게 ‘Hellow World’라는 상수(문자)를 입력하였더니 그 값이 바뀌었다.
var1 = 1
var2 = 2
print(var1 + var2)
3
var1이라는 변수에는 1이라는 숫자가, var2이라는 변수에는 2라는 숫자를 입력하였다. var1 + var2는 1+2와 같으므로 3이라는 결과가 출력된다.
var1 = 3
print(var1 + var2)
5
var1이라는 변수에 다시 3이라는 숫자를 입력하면 var1 + var2는 3+2가 되므로 5라는 결과가 출력된다. 이처럼 변수에는 계속해서 다른 상수를 입력할 수 있다.
2.2. 데이터 타입#
파이썬에는 다양한 데이터 타입이 존재하며, 이에 대해 하나씩 알아보도록 하자.
2.2.1. 숫자형#
숫자형(Number)은 정수나 실수와 같이 숫자 형태로 이루어진 데이터 타입이다. (8진수나 16진수도 있으나 거의 사용하지 않는다).
먼저 정수형(Integer)이란 -2, -1, 0, 1, 2처럼 소수점을 사용하지 않고 숫자를 표현한 것이다.
type(1)
int
type() 함수는 데이터 타입을 확인해주는 역할을 한다. 1이라는 숫자의 타입을 확인해보면 int, 즉 정수임을 알 수 있다. 한편 실수형(Floating-point)이란 소수점이 포함된 숫자다.
type(1.0)
float
1.0이라는 숫자의 타입을 확인해보면 float, 즉 실수임을 알 수 있다. 일반적으로 1과 1.0은 동일한 숫자라고 생각할 수 있지만, 프로그래밍에서 정수형과 실수형은 엄밀하게는 다른 타입이다.
2.2.1.1. 숫자형 연산하기#
숫자형은 다양한 연산이 가능하다.
print(2 + 1)
3
print(2 - 1)
1
print(2 * 3)
6
print(6 / 2)
3.0
파이썬에서는 기본적인 사칙연산(+, -, *, /)을 쉽게 할 수 있다. 이 외에도 다양한 연산자가 존재한다.
3 ** 2
9
연산자 ** 는 제곱을 의미한다. 즉 3**2는 \(3^2\) 을 의미한다.
7 // 3
2
연산자 //는 나눗셈의 몫을 반환한다. 7을 3으로 나누면 몫은 2가 된다.
7 % 3
1
연산자 %는 나눗셈의 나머지를 반환한다. 7을 3으로 나누면 몫은 2가 되며 나머지는 1이 된다.
2.2.2. 문자열#
문자열(String)이란 문자, 단어 등으로 구성된 문자들의 집합을 의미한다. 파이썬에서 문자열을 만드는 방법은 총 4가지가 있다.
"Hello World"
먼저 큰 따옴표(“)로 양쪽을 둘러싸서 문자열을 만들 수 있다.
'Hello World'
따옴표(‘)로 양쪽을 둘러싸서도 문자열을 만들 수 있다.
"""퀀트 투자 포트폴리오 만들기"""
'''퀀트 투자 포트폴리오 만들기'''
큰 따옴표 3개를 연속(“””)으로 양쪽을 둘러싸거나, 작은 따옴표 3개를 연속(‘’’)으로 써서 양쪽을 둘러싸서도 문자열을 만들 수 있다. 따옴표를 3개 사용할 경우 줄 바꿈을 통해 여러줄의 문자열을 만들 수 있다.
multiline = """Life is too short
You need python"""
print(multiline)
Life is too short
You need python
파이썬에서는 문자열도 더하거나 곱할 수 있다.
a = 'Hello'
b = ' World'
a + b
'Hello World'
a라는 변수에 ‘Hello’라는 글자를, b라는 변수에 ‘ World’라는 글자를 입력한 후 두 변수를 더하면 두 글자가 합쳐진다.
c = 'Quant'
c * 3
'QuantQuantQuant'
이번에는 c라는 변수에 ‘Quant’를 입력한 후 3을 곱하면, c가 세 번 반복된다.
2.2.2.1. f-string 포매팅#
문자열에서 특정 부분만이 바뀌고 나머지 부분은 일정할 경우, 파이썬에서는 f-string 포매팅을 이용해 매우 쉽게 나타낼 수 있다. (해당 기능은 파이썬 3.6 버전 이상부터 사용이 가능하다.)
name = '이현열'
birth = '1987'
f'나의 이름은 {name}이며, {birth}년에 태어났습니다.'
'나의 이름은 이현열이며, 1987년에 태어났습니다.'
f-string의 형태는 f'문자열 {변수} 문자열' 이다. 즉 문자열 맨 앞에 f를 붙이면 f-string 포매팅이 선언되며, 중괄호 안에 변수를 넣으면 해당 부분에 변수의 값이 입력된다.
2.2.2.2. 문자열 길이 구하기#
문자열의 길이를 구할때는 len() 함수가 사용된다.
a = 'Life is too short'
len(a)
17
‘Life is too short’이라는 문장은 빈 칸을 포함하여 총 17 글자로 이루어져 있다.
2.2.2.3. 문자열 치환하기#
특정한 문자를 다른 문자로 바꾸는데는 replace() 함수가 사용된다.
var = '퀀트 투자 포트폴리오 만들기'
var.replace(' ', '_')
'퀀트_투자_포트폴리오_만들기'
먼저 var 변수에 ‘퀀트 투자 포트폴리오 만들기’라는 문자열을 입력했다. 그 후 문자열.replace(a, b) 메서드를 사용하면 문자열에서 a라는 문자를 b라는 문자로 바꿀 수 있다. 즉 ‘ ‘는 공백을 의미하여, 이러한 공백을 모두 밑줄(_)로 변경하였다.
2.2.2.4. 문자열 나누기#
split() 메서드를 이용하면 문자열을 나눌 수 있다.
var = '퀀트 투자 포트폴리오 만들기'
var.split(' ')
['퀀트', '투자', '포트폴리오', '만들기']
split() 메서드 내부에 값을 입력하면, 해당 값을 기준으로 문자열을 나눠준다. 위 예제에서는 공백(’ ‘)을 기준으로 각각의 단어를 나누었다.
2.2.2.5. 문자열 인덱싱과 슬라이싱#
인덱싱(Indexing)이란 문자열 중 특정 위치의 값을 가져오는 것이며, 슬라이싱(Slicing)이란 특정 위치가 아닌 범위에 해당하는 문자열을 가지고 오는 것이다.
var = 'Quant'
var[2]
'a'
인덱싱과 슬라이싱은 대괄호([ ])를 사용해서 표현한다. var[2]란 두번째 문자를 의미하며, 이에 해당하는 ‘a’이 출력되었다. 참고로 파이썬은 숫자를 1이 아닌 0부터 세므로 ‘Quant’에서 Q는 var[0], u는 var[1], a는 var[2]에 해당한다.
단어 |
Q |
u |
a |
n |
t |
|---|---|---|---|---|---|
위치 |
0 |
1 |
2 |
3 |
4 |
var[-2]
'n'
인덱싱에 마이너스(-) 기호를 붙이면 문자열을 뒤에서부터 읽는다. 즉 var[-2]은 뒤에서 두번째 문자를 의미하며 이에 해당하는 ‘n’이 출력되었다.
var[0:3]
'Qua'
슬라이싱은 [] 내부에 콜론(:) 기호를 사용하여 시작:마지막에 해당하는 문자를 출력한다. 즉 var[0] 부터 var[3]까지를 출력한다. 그런데 Quant에서 3에 해당하는 단어는 n임에도 불구하고 그 이전인 Qua 까지만 출력이 되었다. 이는 슬라이싱에서 var[시작:마지막]을 지정할 때 마지막 번호에 해당하는 단어는 포함되지 않기 때문이며, var[0:3]은 0 이상 3 미만에 해당하는 문자만 출력한다.
var[:2]
'Qu'
시작에 해당하는 부분을 명시하지 않으면 처음(0)부터 2 미만까지의 문자를 출력한다.
var[3: ]
'nt'
반대로 마지막에 해당하는 부분을 명시하지 않으면 3부터 마지막까지 문자를 출력한다.
2.2.3. 리스트#
파이썬에서는 연속된 데이터를 표현하기 위해 리스트(List) 자료형을 사용한다.
a = []
type(a)
list
리스트는 대괄호([ ])를 이용하여 생성할 수 있으며, 아무 값도 입력하지 않을 경우 빈 리스트가 생성된다.
list_num = [1, 2, 3]
print(list_num)
[1, 2, 3]
list_char = ['a', 'b', 'c']
print(list_char)
['a', 'b', 'c']
list_complex = [1, 'a', 2]
print(list_complex)
[1, 'a', 2]
리스트 내부에 각 요소는 쉼표(,)를 이용해 구분해준다. 요소값은 숫자(list_num), 문자열(list_char), 혹은 숫자와 문자열(list_complex)을 함께 가질 수도 있다.
list_nest = [1, 2, ['a', 'b']]
print(list_nest)
[1, 2, ['a', 'b']]
혹은 리스트 자체를 하나의 요솟값으로 가질 수도 있다. 즉 리스트 안에는 어떠한 자료형도 들어갈 수 있다.
2.2.3.1. 리스트 인덱싱과 슬라이싱#
리스트도 문자열과 동일한 방법으로 인덱싱과 슬라이싱을 할 수 있다.
var = [1, 2, ['a', 'b', 'c']]
var[0]
1
문자열과 동일하게 var[0]을 입력할 경우 해당 요소값인 1이 출력된다.
var[2]
['a', 'b', 'c']
var[2]를 입력할 경우 [‘a’, ‘b’, ‘c’]라는 리스트가 출력된다. 추가로 [‘a’, ‘b’, ‘c’] 리스트에서 ‘a’라는 문자열만 추출하는 방법은 다음과 같다.
var[2][0]
'a'
먼저 var[2]를 통해 [‘a’, ‘b’, ‘c’]를 추출하며, 뒤에 [0]을 추가적으로 붙여 첫번째 요소인 ‘a’가 출력된다. 이처럼 중첩된 리스트에서도 인덱싱은 여러번 하면 얼마든지 원하는 값을 선택할 수 있다. 이번에는 리스트의 슬라이싱에 대해서 살펴보자.
var = [1, 2, 3, 4, 5]
var[0:2]
[1, 2]
문자열의 슬라이싱과 동일하게 var[0:2]를 입력하면 리스트 a의 0 이상 2 미만에 해당하는 요소들이 출력된다.
2.2.3.2. 리스트 연산하기#
리스트도 +, * 연산을 제한적으로 사용할 수 있다.
a = [1, 2, 3]
b = [4, 5, 6]
a+b
[1, 2, 3, 4, 5, 6]
리스트 사이에 + 기호를 사용하면 두 리스트를 하나로 합친다.
a = [1, 2, 3]
a * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
리스트에 * 기호를 사용하면 해당 리스트를 n번 반복한다.
2.2.3.3. 리스트에 요소 추가하기#
다양한 방법을 통해 기존의 리스트에 새로운 데이터를 추가하거나 삽입할 수 있다.
var = [1, 2, 3]
var.append(4)
print(var)
[1, 2, 3, 4]
append() 메서드는 기존의 리스트 맨 마지막에 데이터를 추가한다.
var = [1, 2, 3]
var.append([4, 5])
print(var)
[1, 2, 3, [4, 5]]
만약 append() 메서드 내에 리스트 형태를 입력할 경우 중첩된 형태로 데이터가 추가된다. 리스트에 새로운 리스트를 중첩된 형태가 아니라 리스트 형태로 확장하고 싶을 경우에는 extend() 메서드를 사용하면 된다.
var = [1, 2, 3]
var.extend([4, 5])
print(var)
[1, 2, 3, 4, 5]
extend() 메서드 내의 리스트인 [4, 5]가 중첩된 형태가 아니라 기존 데이터인 [1, 2, 3] 뒤에 확장이 되었다.
2.2.3.4. 리스트의 수정과 삭제#
인덱싱과 슬라이싱을 이용하면 리스트의 요소를 수정 혹은 삭제할 수 있다.
var = [1,2,3,4,5]
var[2] = 10
print(var)
[1, 2, 10, 4, 5]
먼저 var라는 변수에 1부터 5까지 숫자로 구성된 리스트를 만들었다. 그 후 var의 두번재 요소에 10을 입력하면 해당 값으로 요소가 변경되었다.
var[3] = ['a', 'b', 'c']
print(var)
[1, 2, 10, ['a', 'b', 'c'], 5]
이번에는 세번째 요소를 [‘a’, ‘b’, ‘c’]라는 요소로 변경하였다.
var[0 : 2] = ['가', '나']
print(var)
['가', '나', 10, ['a', 'b', 'c'], 5]
슬라이싱을 이용해 데이터를 수정할 수도 있다. var[0 : 2]는 0 부터 1 까지의 데이터를 의미하며, 해당 데이터를 [‘가’, ‘나’]로 변경하였다.
이번에는 리스트에서 요소를 삭제하는 방법에 대해 살펴보겠으며, 먼지 del 명령어를 사용하는 방법에 대해 알아보자.
var = [1, 2, 3]
del var[0]
print(var)
[2, 3]
del 객체를 이용하여 데이터를 삭제할 수 있다. 위의 예제에서 del var[0]는 var에서 첫번째 요소를 삭제하라는 의미다. 인덱싱 뿐만 아니라 dal var[0:2]와 같이 슬라이싱을 통해서도 데이터를 삭제할 수 있다.
var = [1, 2, 3]
var[0:1] = []
print(var)
[2, 3]
슬라이싱을 통해 범위를 지정한 후 빈 리스트([])를 입력하여 해당 부분의 데이터를 삭제할 수도 있다.
var = [1, 2, 3, 1, 2, 3]
var.remove(1)
print(var)
[2, 3, 1, 2, 3]
remove(x) 메서드는 리스트에서 첫 번째로 나오는 x를 삭제하는 함수이다. 위 예제에서는 가장 먼저 나오는 1이 삭제된 것을 확인할 수 있다.
var = [1, 2, 3]
var.pop()
3
print(var)
[1, 2]
pop() 메서드는 리스트의 맨 마지막 요소를 반환하고 해당 요소는 삭제한다. 위 예에서 가장 마지막 요소인 3이 출력되고, var를 확인해보면 최종적으로 [1, 2]만 남아있다.
2.2.3.5. 리스트 정렬하기#
리스트 내의 데이터들은 sort() 메서드를 통해 정렬할 수 있다.
var = [2, 4, 1, 3]
var.sort()
print(var)
[1, 2, 3, 4]
1부터 4까지의 순서가 무작위로 존재했지만, sort()를 입력하면 오름차순으로 정렬된다.
2.2.4. 튜플#
튜플(Tuple) 자료형은 리스트와 매우 흡사하며 약간의 차이점만 있다. 먼저 리스트는 대괄호([ ])를 이용해 생성하지만 튜플은 소괄호(( ))를 이용해 생성한다. 또한 튜플은 값을 수정하거나 삭제할 수 없다.
var = ()
type(var)
tuple
리스트와 마찬가지로 소괄호를 입력하면 빈 튜플이 생성된다.
var = (1, )
print(var)
(1,)
만일 값이 하나만 있을 경우에는 요소 뒤에 콤마(,)를 반드시 붙여야 한다.
var = (1, 2, ('a', 'b'))
print(var)
(1, 2, ('a', 'b'))
튜플 역시 요소를 중첩하여 사용할 수 있다.
var = (1, 2)
del var[0]

만일 del 명령어를 이용해 요소값을 삭제하려고 할 경우 오류가 발생한다. 이처럼 튜플은 수정 혹은 삭제가 불가능하다.
var = (1, 2, 3, 4, 5)
var[0]
1
인덱싱이나 슬라이싱의 경우 리스트와 동일하게 사용이 가능하다.
2.2.5. 딕셔너리#
딕셔너리(Dictionary)는 대응 관계를 나타내는 자료형으로써, 리스트나 튜플처럼 순서가 존재하지 않으며 대신 Key와 Value가 존재한다. 딕셔너리는 다음과 같은 형태를 가지고 있다.
{Key1:Value1, Key2:Value2, Key3:Value3, ...}
딕셔너리는 중괄호({ })를 감싸서 표현한다. 키(Key)-값(Value)의 형태로 데이터가 이루어져 있으며, 각각은 쉼표(,)로 구분된다. 예시를 살펴보도록 하자.
var = {'key1' : 1, 'key2' : 2}
print(var)
{'key1': 1, 'key2': 2}
키 값이 key1인 곳에는 1이라는 값이, 키 값이 key2인 곳에는 2라는 값이 딕셔너리 형태로 입력되었다.
var = {'key1': [1, 2, 3], 'key2': ('a', 'b', 'c')}
print(var)
{'key1': [1, 2, 3], 'key2': ('a', 'b', 'c')}
딕셔너리의 값에는 리스트나 튜플 형태도 입력이 가능하다.
2.2.5.1. Key를 사용해 Value 구하기#
문자열이나 리스트, 튜플의 경우 인덱싱이나 슬라이싱을 통해 요소값을 구할 수 있었지만, 딕셔너리는 순서가 존재하지 않으므로 이러한 방법을 사용할 수 없다. 딕셔너리는 Key를 사용해 이에 해당되는 Value를 얻을 수 있다.
var = {'key1': 1, 'key2': 2, 'key3': 3}
var['key1']
1
먼저 var라는 변수에 딕셔너리를 입력한 후, var['key1']을 입력하면 딕셔너리 중 Key값이 key1에 해당하는 데이터의 Value를 반환한다. 즉 딕셔너리 변수에서 [ ] 안의 값은 순서를 뜻하는 것이 아니라 Key 값을 의미한다.
2.2.5.2. 쌍 추가하기 및 삭제하기#
기존 딕셔너리에 쌍을 추가하는 방법과 삭제하는 방법에 대해 살펴보자.
var = {'key1': 1, 'key2': 2}
var['key3'] = 3
print(var)
{'key1': 1, 'key2': 2, 'key3': 3}
먼저 key1과 key2로 이루어진 딕셔너리를 만들었다. 그 후 var['key3'] = 3을 입력하면 Key는 key3, Value는 3인 딕셔너리 쌍이 추가된다.
del var['key1']
print(var)
{'key2': 2, 'key3': 3}
리스트와 마찬가지로 딕셔너리에서도 del 명령어를 사용하면 해당 Key를 가진 딕셔너리 쌍이 삭제된다.
2.2.5.3. Key와 Value 구하기#
이번에는 딕셔너리의 Key와 Value를 한번에 구하는 법에 대해 살펴보자.
var = {'key1': 1, 'key2': 2, 'key3': 3}
var.keys()
dict_keys(['key1', 'key2', 'key3'])
var.keys()를 입력하면 var라는 딕셔너리에서 Key만을 모아 dict_keys 객체로 반환한다. 만일 이를 리스트 형태로 만들고자할 때는 다음과 같이 하면 된다.
list(var.keys())
['key1', 'key2', 'key3']
결과를 list()로 감싸주면 Key값이 리스트 형태로 출력된다.
var.values()
dict_values([1, 2, 3])
var.values()는 var라는 딕셔너리에서 값만을 모아 dict_values 객체로 반환한다.
2.2.6. 집합#
집합(Set)은 집합에 관련된 자료형이며, set() 키워드를 사용해 만들 수 있다. 집합 자료형의 특징으로는 중복을 허용하지 않는다는 점과, 순서가 없다는 점이다.
set1 = set([1, 2, 3])
print(set1)
{1, 2, 3}
set() 내에 리스트를 입력하면 집합이 만들어진다.
set2 = set('banana')
print(set2)
{'n', 'a', 'b'}
반면 set() 내에 banana라는 단어를 입력했더니 ‘a’, ‘b’, ‘n’만 입력이 되었다. 이는 집합이 중복을 허용하지 않기 때문에 고유한 값만이 남았으며, 순서도 입력한 것과 다르다.
2.2.6.1. 합집합, 교집합, 차집합 구하기#
집합 자료형을 통해 합집합, 교집합, 차집합을 구해보도록 하자.
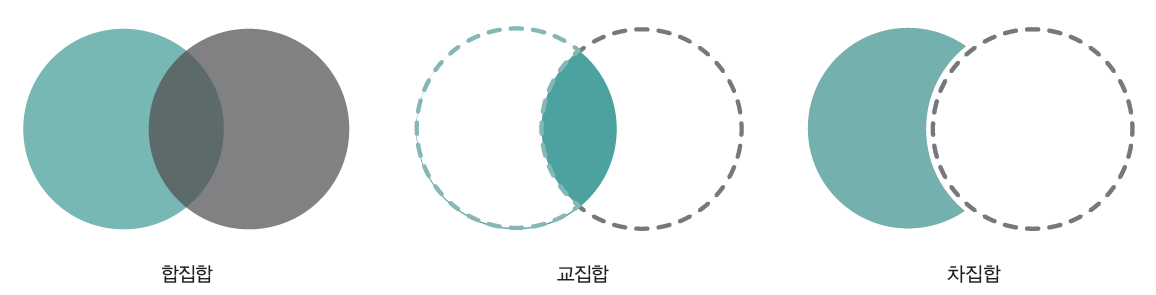
Fig. 2.1 집합 연산의 종류#
s1 = set([1, 2, 3, 4])
s2 = set([3, 4, 5, 6])
먼저 합집합을 구해보도록 하자. 합집합이란 하나에라도 속하는 원소들을 모두 모은 집합이다.
s1.union(s2)
{1, 2, 3, 4, 5, 6}
union() 메서드를 사용하면 합집합을 구할 수 있다. 즉 1부터 6까지의 숫자가 집합에 입력되며, 두 집합에 공통으로 존재하는 3과 4는 한번만 입력이 된다.
다음으로 교집합을 구해보도록 하자. 교집합이란 두 집합이 공통으로 포함하는 원소로 이루어진 집합이다.
s1.intersection(s2)
{3, 4}
intersection() 메서드를 사용하면 교집합을 구할 수 있다. 즉 두 집합에 공통으로 존재하는 3과 4가 반환된다.
마지막으로 차집합을 구해보도록 하자. 차집합이란 집합 A에는 속하지만 집합 B에는 속하지 않는 원소들로 이루어진 집합이다.
s1.difference(s2)
{1, 2}
difference() 메서드를 사용하면 집합 s1에서 교집합을 제외한 {1, 2}만이 반환된다.
2.2.7. 불리언#
불리언(Boolean) 자료형이란 참(True) 혹은 거짓(False)을 나타내는 자료형으로, 이 두가지 값만을 가질 수 있다. 참고로 True와 False는 첫 문자는 항상 대문자로 사용해야 한다.
var = True
type(var)
bool
var 변수에 True를 입력한 후 타입을 확인해보면 bool, 즉 불리언 자료형임을 알 수 있다.
1 == 1
True
파이썬에서 == 는 양측 값이 같은지를 확인하는 비교연산자이다. 좌측의 1과 우측의 1은 같으므로 True 즉 참이 반환된다.
1 != 2
True
!= 는 양측 값이 다른지를 확인하는 비교연산자이다. 좌측의 1과 우측의 2는 다르므로 역시나 True가 반환된다.
2.2.7.1. 자료형의 참과 거짓#
자료형 자체에도 참과 거짓이 존재한다.
bool(0)
False
bool() 함수는 참(True)과 거짓(False)을 반환하는 함수다. 숫자 0은 False에 해당한다.
bool(1)
True
bool(2)
True
반면 0이 아닌 숫자는 True에 해당한다.
bool(None)
False
None은 값의 부재를 나타내는데 사용되며, False에 해당한다.
bool("")
False
bool([])
False
bool({})
False
bool(())
False
문자열, 리스트, 딕셔너리, 튜플 등의 값이 비어 있을 경우는 False에 해당한다.
bool('Python')
True
bool([1, 2, 3])
True
bool({'Key':'Value'})
True
bool((1, 2))
True
반면 데이터가 존재하면 True에 해당한다. 이를 요약하면 다음과 같다.
값 |
True or False |
|---|---|
0 |
False |
0 외의 숫자 |
True |
None |
False |
“” |
False |
[] |
False |
{} |
False |
() |
False |
[데이터] |
True |
{key:value} |
True |
(데이터) |
True |
2.2.8. 날짜와 시간#
날짜와 시간은 파이썬에서 기본으로 제공하는 자료형에는 포함되어 있지 않지만 데이터 분석을 할 때 빈번하게 다루는 자료형이다. 날짜와 시간과 관련된 패키지는 다음과 같다.
2.2.8.1. 날짜와 시간 구하기#
datetime 패키지를 이용해 현재 날짜 및 시간 정보를 구할 수 있다(패키지에 대한 자세한 설명은 이번 장의 맨 마지막에서 자세히 다룬다).
import datetime
var = datetime.datetime.now()
var
datetime.datetime(2024, 2, 12, 16, 49, 20, 306183)
type(var)
datetime.datetime
datetime 클래스의 now() 메서드는 현재 날짜와 시간을 반환한다. 앞에서부터 [연도, 월, 일, 시, 분, 초, 마이크로초]를 의미한다. 이 중 연도에 해당하는 부분만 선택해보자.
print(var.year)
2024
var. 뒤에 속성을 입력하면 이에 해당하는 값이 출력된다. 날짜와 시간과 관련된 속성은 다음과 같다.
year: 연도
month: 월
day: 일
hour: 시
minute: 분
second: 초
microsecond: 마이크로초 (백만분의 일초)
각 속성을 한번에 출력해보도록 하자.
var.year, var.month, var.day, var.hour, var.minute, var.second, var.microsecond
(2024, 2, 12, 16, 49, 20, 306183)
datetime 클래스에는 이 외에도 다양한 메서드가 존재한다.
var.weekday()
0
weekday는 요일을 반환한다. 결과값으로 0은 월요일, 1은 화요일, 2는 수요일, 3은 목요일, 4은 금요일, 5는 토요일, 6은 일요일을 뜻한다.
var.date(), var.time()
(datetime.date(2024, 2, 12), datetime.time(16, 49, 20, 306183))
date()는 날짜에 관련된 정보만, time()은 시간에 관련된 정보만 반환한다.
2.2.8.2. 포맷 바꾸기#
포맷을 바꾸는데는 크게 두가지 메서드가 사용된다.
strftime: 시간 정보를 문자열로 바꿈strptime: 문자열을 시간 정보로 바꿈
먼저 strftime를 이용해 시간 정보를 문자 정보로 바꿔보도록 하자.
var
datetime.datetime(2024, 2, 12, 16, 49, 20, 306183)
위의 시간 정보를 일반적으로 많이 사용하는 ‘yyyy-mm-dd’, 즉 ‘연도-월-일’ 형태로 바꿔보도록 하자.
var.strftime('%Y-%m-%d')
'2024-02-12'
%Y, %m, %d는 날짜 및 시간을 어떤 형식의 문자열로 만들지 결정하는 형식 문자열이다. 날짜 및 시간을 나타내는 형식은 다음과 같다.
그룹 |
코드 |
뜻 |
|---|---|---|
년 |
%Y |
연도 (전체) |
%y |
연도 (뒤 2자리만) |
|
월 |
%m |
월 |
%B |
Locale 월 표현 (전체) |
|
%b |
Locale 월 표현 (축약) |
|
일 |
%d |
일 |
%j |
연중 일 |
|
시 |
%H |
시 (24시간) |
%I |
시 (12시간) |
|
%p |
Locale 오전, 오후 |
|
분 |
%M |
분 |
초 |
%S |
초 |
마이크로초 |
%f |
마이크로초 |
요일 |
%w |
요일 |
%A |
Locale 요일 (전체) |
|
%a |
Locale 요일 (축약형) |
|
주 |
%W |
연중 몇 번째 주인지 표현 (월요일 시작 기준) |
%U |
연중 몇 번째 주인지 표현 (일요일 시작 기준) |
|
날짜 표현 |
%c |
Locale 날짜와 시간 표현 |
%x |
Locale 날짜 표현 |
|
%X |
Locale 시간 표현 |
예를 들어 시간 정보를 문자열로 바꿔보도록 하자.
t = datetime.datetime(2022, 12, 31, 11, 59, 59)
t.strftime("%a %d, %b %y")
'Sat 31, Dec 22'
t.strftime("%H시 %M분 %S초")
'11시 59분 59초'
반대로 문자열로부터 날짜와 시간 정보를 읽은 후 datetime 클래스 객체로 만들 수 있으며, 이 경우 strptime 메서드를 사용한다.
datetime.datetime.strptime("2022-12-31 11:59:59", "%Y-%m-%d %H:%M:%S")
datetime.datetime(2022, 12, 31, 11, 59, 59)
첫 번째 인자에 날짜와 시간 정보를 가진 문자열을, 두 번째 인자에 이에 해당하는 형식 문자열을 입력하면 datetime 클래스 객체로 변경된다.
2.2.8.3. 날짜와 시간 연산하기#
날짜 혹은 시간의 간격을 구할 수도 있다.
dt1 = datetime.datetime(2022, 12, 31)
dt2 = datetime.datetime(2021, 12, 31)
td = dt1 - dt2
td
datetime.timedelta(days=365)
2022년 12월 31일에서 2021년 12월 31일을 빼면 days=365, 즉 365일의 차이가 있음을 확인할 수 있다. 이번에는 날짜에 특정 기간을 더해보도록 하자.
dt1 = datetime.datetime(2021, 12, 31)
dt1 + datetime.timedelta(days = 1)
datetime.datetime(2022, 1, 1, 0, 0)
timedelta 객체를 통해 원하는 기간을 더해거나 빼줄 수 있다. 2021년 12월 31일에 days = 1, 즉 1일을 더하면 다음날인 2022년 1월 1일이 계산된다. 그러나 timedelta 객체의 단점은 날짜와 초 단위로만 연산을 할 수 있다는 점이며, 월 단위의 경우 dateutil 패키지의 relativedelta 클래스를 이용하면 된다.
from dateutil.relativedelta import relativedelta
dt1 + relativedelta(months = 1)
datetime.datetime(2022, 1, 31, 0, 0)
timedelta와 사용법은 같으며, months = 1을 통해 한 달의 기간을 더할 수 있다.
2.2.8.4. 코드를 일시정지 하기#
time 패키지의 sleep() 함수를 사용하면 일정 시간동안 프로세스를 일시정지할 수 있다.
import datetime
import time
for i in range(3) :
print(i)
print(datetime.datetime.now())
print('-------')
time.sleep(2)
0
2024-02-12 16:49:20.401262
-------
1
2024-02-12 16:49:22.401705
-------
2
2024-02-12 16:49:24.402400
-------
위 코드는 0부터 2까지 for문 내에서 i와 현재 시간을 출력하며, time.sleep(2)을 통해 루프당 2초의 일시정지를 준다. 출력된 결과를 살펴보면 한 번의 루프가 끝난 후 약 2초 후에 다음 루프가 실행된 것을 확인할 수 있다.
2.3. 제어문#
파이썬 프로그래밍은 위에서부터 아래 방향으로 작성된 내용을 순서대로 실행한다. 반면 이러한 흐름을 제어하여 실행 순서를 바꾸거나 여러 번 반복하도록 하는 것이 제어문이다. 파이썬의 제어문에는 크게 if문, while문, for문이 있다.
2.3.1. if 문#
if문, 혹은 조건문이란 입력된 조건을 판단하여 해당 조건에 맞는 상황을 실행한다. if문의 기본적인 구조는 다음과 같다.
if 조건:
실행
if를 통해 if문을 선언하고, 바로 뒤에 조건을 입력한 후 콜론(:)을 붙인다.줄바꿈을 해준 후 만일 조건이 True일 경우 실행할 코드를 입력한다. 이 때 조건문 바로 아래부터는 if문에 속하는 문장이므로 들여쓰기를 해주어야 하며, 공백을 4번 입력하거나 탭을 누른다. 만일 들여쓰기가 제대로 되지 않을 경우 오류가 발생한다.
예를 살펴보도록 하자.
x = 2
if x > 0:
print('값이 0보다 큽니다.')
값이 0보다 큽니다.
먼저 x라는 변수에 2라는 숫자를 입력한다.
if를 통해 조건을 선언하며 조건에는x > 0을 설정한 후 콜론을 입력한다.만일 위 조건이 True일 경우 ‘값이 0보다 큽니다.’를 출력한다.
실제 결과를 살펴보다 2는 0보다 크므로 해당 문장이 출력된다.
x = -1
if x > 0:
print('값이 0보다 큽니다.')
반면 위의 경우 코드를 실행해도 아무런 결과가 나타나지 않는다. 이는 x에 입력된 -1이 0보다 작으므로 조건이 False이기 때문이다. 이처럼 조건문이 False일때 실행할 상황은 else를 이용한다.
if 조건:
실행 1
else:
실행 2
만일 조건이 True일 경우에는 [실행 1]에 해당하는 코드가 실행되지만, 그렇지 않을 경우 [실행 2]에 해당하는 코드가 실행된다. if와 마찬가지로 else문 아래의 문장도 들여쓰기를 해주어야 한다.
x = -1
if x > 0:
print('값이 0보다 큽니다.')
else:
print('값이 음수입니다.')
값이 음수입니다.
-1이 0보다 작으므로 조건은 False다. 따라서 else에 속하는 ‘값이 음수입니다.’가 출력된다. 만일 조건이 여러개인 다중 조건을 판단하려면 if와 else 사이에 elif를 추가하면 된다.
if 조건 1:
실행 1
elif 조건 2:
실행 2
elif 조건 3:
실행 3
...
else:
실행 n
if의 [조건 1]이 False일 경우 바로 아래의 elif를 통해 [조건 2]를 판단한다. 만일 [조건 2]가 True일 경우에는 [실행 2]에 해당하는 코드가 실행되지만, False일 경우에는 다시 [조건 3]을 판단한다. 만일 모든 elif의 조건이 False일 경우 최종적으로 [실행 n]에 해당하는 코드가 실행되며, elif는 개수에 제한 없이 사용할 수 있다.
x = 3
if x >= 10:
print('값이 10보다 큽니다.')
elif x >= 0:
print('값이 0 이상 10 미만입니다.')
else:
print('값이 음수입니다.')
값이 0 이상 10 미만입니다.
먼저 if 조건에서 3은 10 보다 크지 않으므로 조건이 False이며, 이에 해당하는 코드가 실행되지 않는다. 그 후 elif 조건에서 3은 0보다 크므로 이에 해당하는 코드인 ‘값이 0 이상 10 미만입니다.’가 출력된다.
만일 조건문이 if와 else로만 구성될 경우 다음과 같이 간단하게 작성할 수도 있다.
[조건문이 True인 경우] if 조건문 else [조건문이 False 경우]
예제를 살펴보도록 하자.
x = 7
'0 이상' if x >= 0 else '음수'
'0 이상'
x가 0 이상일 경우에는 ‘0 이상’을 출력하며, 그렇지 않을 경우엔 ‘음수’를 출력한다. 이처럼 조건부 표현식은 한 줄로 작성할 수 있어 훨씬 가독성이 좋다.
2.3.2. while문#
while문, 혹은 반복문은 특정 조건을 만족하는 동안 반복해서 코드를 실행한다. while문의 기본적인 구조는 다음과 같다.
while 조건:
실행
[조건]에 해당하는 부분이 True인 동안에는 [실행]에 해당하는 코드가 반복해서 수행된다. while문도 if문과 마찬가지로 [실행]에 해당하는 부분은 들여쓰기를 해주어야 한다. 예제를 살펴보도록 하자.
num = 1
while num < 5:
print(num)
num = num + 1
1
2
3
4
먼저 num에 1을 입력한다.
만일 num이 5 미만일 경우 아래의 코드를 계속해서 수행한다.
num을 출력한다.
num에 1을 더한다.
1부터 4까지 숫자가 출력되다가, num이 5가 된 순간에는 while문의 조건이 False 이므로 코드 실행이 종료된다. 만약 num = num + 1 부분이 없다면 num은 계속 1인 상태이므로 print(num)이 무한대로 실행된다.
while문 내부에 if문을 추가할 수도 있다.
num = 1
while num < 10 :
if num % 2 == 0 :
print(f'{num}은 짝수입니다.')
num = num + 1
2은 짝수입니다.
4은 짝수입니다.
6은 짝수입니다.
8은 짝수입니다.
num에 1을 입력한다.
while을 통해 num이 10 미만일 경우 아래의 코드를 계속해서 수행한다.if를 추가하여 num % 2 == 0일 경우, 즉 나머지가 0일 경우 글자를 출력한다.num에 1을 더한다.
즉 1부터 9까지 숫자 중, 짝수인 부분만 글자를 출력한다. 만일 코드가 계속해서 실행되다가 특정 조건을 만족할 경우 멈추게 하고 싶을 경우 if문에 break를 사용하면 된다.
money = 1000
while True:
money = money - 100
print(f'잔액은 {money}원 입니다.')
if money <= 0 :
break
잔액은 900원 입니다.
잔액은 800원 입니다.
잔액은 700원 입니다.
잔액은 600원 입니다.
잔액은 500원 입니다.
잔액은 400원 입니다.
잔액은 300원 입니다.
잔액은 200원 입니다.
잔액은 100원 입니다.
잔액은 0원 입니다.
money에 1000을 입력한다.
while True를 통해 코드가 무한히 반복된다.money에서 100을 빼준 후, 잔액을 출력한다.
if문을 통해 잔액이 0 미만일 경우
break를 통해 while문을 멈춘다.
결과를 살펴보면 잔액이 100원씩 줄어들다가 0원이 된 순간, if문의 조건이 True이므로 break를 통해 while문이 멈추게 된다.
2.3.3. for문#
for문은 while문과 동일한 반복문이지만, 무한히 반복되는 것이 아닌 특정 횟수만큼만 반복되는 특징이 있다. for문의 기본적인 구조는 다음과 같다.
for 변수 in 리스트(또는 튜플, 문자열):
실행
리스트 또는 튜플, 문자열의 첫 번째 요소부터 마지막 요소까지 차례로 변수에 대입된 후 [실행]에 해당하는 코드가 실행되며, 역시나 들여쓰기를 해야한다. 예제를 살펴보도록 하자.
var = [1, 2, 3]
for i in var:
print(i)
1
2
3
var에 해당하는 [1, 2, 3]의 리스트 중 첫 번째 요소인 1이 먼저 변수 i에 대입된 후 print(i)가 실행된다. 그 후 두 번째 요소인 2가 다시 변수 i에 대입되어 print(i)가 실행되고, 리스트의 마지막 요소까지 반복된다.
for문 역시 if문과 함께 사용할 수 있다.
var = [10, 15, 17, 20]
for i in var:
if i % 2 == 0:
print(f'{i}는 짝수입니다.')
else:
print(f'{i}는 홀수입니다.')
10는 짝수입니다.
15는 홀수입니다.
17는 홀수입니다.
20는 짝수입니다.
var에 [10, 15, 17, 20]를 입력한다.
for문을 통해 var의 요소를 하나씩 i에 대입하여 아래의 코드들을 실행한다.
if문을 통해 만일 나머지가 0일 경우 ‘짝수입니다.’라는 글자를, 그렇지 않을 경우 else를 통해 ‘홀수입니다.’라는 글자를 출력한다.
for문은 range() 함수와 함께 쓰이는 경우가 많다. range() 함수는 숫자(정수) 리스트를 자동으로 만들어준다.
range(10)
range(0, 10)
range() 함수 내에 10을 입력할 경우 0부터 10 미만의 숫자에 해당하는 range 객체를 만들어 준다.
range(5, 10)
range(5, 10)
시작과 끝 숫자를 지정할 수도 있다. range(5, 10)을 입력하면 5부터 10 미만의 숫자에 해당하는 range 객체를 만들어 준다. range() 함수의 예시를 살펴보도록 하자.
for i in range(5):
print(i)
0
1
2
3
4
range(5)는 0부터 5 미만의 숫자 리스트를 의미하며, for문을 통해 요소를 하나씩 출력하였다.
리스트 안에 for문을 포함하는 리스트 내포(List Comprehension)을 사용하면 더욱 직관적인 코딩이 가능하다.
a = [1, 2, 3]
만일 위 값들의 제곱을 구하려면 어떻게 해야할까? 일반적인 for문을 사용한 코드는 다음과 같다.
result = []
for i in a:
result.append(i**2)
print(result)
[1, 4, 9]
빈 리스트(result)를 만든다.
i에 요소를 하나씩 입력하여 제곱(
i**2)을 구한 후, append를 이용해 리스트에 추가한다.결과를 확인해보면 모든 요소의 제곱이 구해졌다.
그러나 리스트 내포 안에 if 조건을 사용하면 위 코드를 훨씬 간단하게 나타낼 수 있다. 리스트 내포의 문법은 다음과 같다.
[실행 for 변수 in 리스트(또는 튜플, 문자열)]
이는 기존의 for문에서 위아래를 변경한 후, 리스트 내에 넣어 표현한 것이다. 실제 코드로 나타내면 다음과 같다.
result = [i**2 for i in a]
print(result)
[1, 4, 9]
리스트 내포를 사용할 경우 기존의 for문에 비해 훨씬 간단하게 표현할 수 있다.
2.3.4. 오류에 대한 예외처리#
for문을 실행하던 중 오류가 발생하면 작업이 끊겨 루프를 처음부터 다시 실행해야 한다. 대상이 얼마되지 않는다면 큰 문제가 되지 않겠지만, 수십분 혹은 몇시간이 걸리는 작업을 하던 중 오류가 발생해 작업을 처음부터 다시 해야하는 것은 매우 비효율적이다. try-except문을 이용하면 예외처리, 즉 오류가 발생할 경우 이를 무시하고 넘어갈 수 있다.
try-except문의 구조는 다음과 같다.
try:
expr
except:
error-handler-code
else:
running-code
finally:
cleanup-code
try 내의
expr는 실행하고자 하는 코드를 의미한다.except 내의
error-handler-code는 오류 발생 시 실행할 코드를 의미한다.else 내의
running-code는 expr 코드가 문제가 없을 경우 실행되는 코드, finally 내의cleanup-code코드는 오류 여부와 관계 없이 무조건 수행할 구문을 의미하며, 이 둘은 생략할 수도 있다.
예제를 통해 살펴보도록 하자.
number = [1, 2, 3, "4", 5]
먼저 number 변수에는 1에서 5까지 값이 입력되어 있으며, 다른 값들은 형태가 숫자인 반면 4는 문자 형태다.
for i in number:
print(i ** 2)
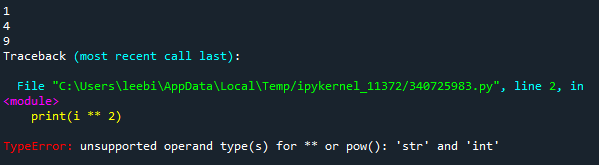
for문을 통해 순서대로 값들의 제곱을 출력하는 명령어를 실행하면 ‘문자 4’는 제곱을 할 수 없어 오류가 발생한다. try-except문을 사용하면 이처럼 오류가 발생하는 루프를 무시하고 다음 루프로 넘어갈 수 있다.
for i in number:
try:
print(i ** 2)
except:
print('Error at: ' + i)
1
4
9
Error at: 4
25
expr 부분은 print(i ** 2)이며, error-handler-code 부분은 오류가 발생한 i를 출력한다. 해당 코드를 실행하면 문자 4에서 오류가 발생함을 알려준 후 루프가 멈추지 않고 다음으로 진행된다.
2.3.5. tqdm() 함수를 이용한 진행 단계 확인하기#
for문의 시간이 오래 걸리는 작업의 경우 어느정도 진행되었는지 궁금할 때가 있다. 파이썬에서는 tqdm 패키지를 통해 진행 정도를 손쉽게 확인할 수 있다.
import time
from tqdm import tqdm
for i in tqdm(range(10)):
time.sleep(0.1)
100%|██████████████████████████████████████████████████████████████████████████████████| 10/10 [00:01<00:00, 9.87it/s]
tqdm 패키지에서 tqdm() 함수를 불러온 뒤, for문의 loop에 해당하는 부분을 tqdm() 로 감싸주면, 진행 정도를 확인할 수 있다.
2.4. 함수#
중고등학교 수학시간에 우리는 함수라는 개념을 배웠다. \(y=f(x)\)라는 수식이 있을 때 \(x\)라는 값을 \(f()\)라는 함수에 입력하면 \(y\)라는 결과값이 나온다. 예를 들어 다음과 같은 함수가 있다고 생각해보자.
만일 \(x\)에 1을 넣으면 결과는 \(2×1 + 1 = 3\) 이며, \(x\)에 2를 넣으면 결과는 \(2×2 + 1 = 5\) 이다.
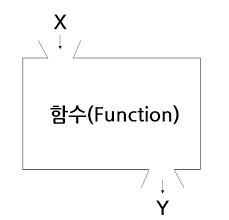
Fig. 2.2 함수#
프로그래밍에서의 함수도 이와 비슷하다. 어떠한 입력값을 함수에 넣으면 이를 토대로 코드가 돌아가고, 그 결과를 반환한다. 함수를 사용하는 이유는 중복된 코드를 계속해서 작성하지 않기 위해서다. 만일 반복적으로 사용하는 코드가 있다면 이를 매번 적기 보다는 함수로 만들어두고, 필요할 때마다 함수를 사용하는 것이 효과적이다.
우리는 앞서 print()와 같이 수많은 함수를 이미 사용했다. 이처럼 가장 이상적인 방법은 기존에 누군가 작성한 패키지 혹은 함수를 찾아 이용하는 것이지만, 그렇지 못할 경우에도 나만의 함수를 쉽게 만들어 사용할 수 있다. 파이썬에서 함수를 만드는 법은 다음과 같다.
def f(x):
statement
return y
def 키워드를 통해 함수임을 선언한다.
f는 함수명을 뜻한다.
x는 함수에 들어가는 매개변수(Parameter)를 뜻한다.
줄을 바꾼 후 들여쓰기를 한다.
statement에 해당하는 코드가 실행된다.
return 뒤에 적은 y가 반환되며, 함수가 종료된다.
예시로 제곱근을 계산하는 함수를 만들어보자.
def sqrt(x):
res = x**(1 / 2)
return res
sqrt(4)
2.0
sqrt(9)
3.0
def를 통해 함수를 선언하며, 함수명은 sqrt로 한다.
매개변수는 x 하나가 사용된다.
x ** (1/2)은 \(x^{\frac{1}{2}}\)를 뜻하며, 즉 제곱근을 구한다. 이를 res라는 변수에 저장한다.
최종적으로 res를 반환한다.
만들어진 함수에 4와 9라는 숫자를 넣으면 각각의 제곱근인 2와 3을 출력된다. 참고로 함수에 입력한 4와 9처럼 함수를 호출할 때 전달하는 입력값은 인자(Argument) 혹은 인수라 한다.
이번에는 매개변수가 여러개인 함수를 만들어보도록 하자.
def multiply(x, y):
res = x**y
return res
multiply(x = 3, y = 4)
81
multiply(5, 2)
25
매개변수로 x와 y 두개가 사용되었으며, \(x^y\)를 구하는 함수인 multiply()를 만들었다. multiply(x = 3, y = 4)와 같이 각 매개변수에 대응되는 인자를 직접 지정할 수도 있지만, multiply(5, 2)와 같이 인자만 입력하면 함수에서 정의한 순서에 따라 x에는 5, y에는 2가 대입되어 계산이 된다.
def divide(x, n=2):
res = x / n
return (res)
divide(3)
1.5
divide(6, 3)
2.0
이번에는 매개변수 부분에 n = 2를 통해 디폴트 값을 설정하였다. 즉 n에 해당하는 부분에 값을 입력하지 않을 경우 n에는 2라는 값이 자동으로 입력된다.
위 함수에서는 매개변수가 ‘x’, ‘n’ 2개가 필요함에도 불구하고 divide(3)은 1.5라는 값이 계산되었다. 즉 x에는 3이라는 값이 입력되었지만, n에는 값이 입력되지 않아 디폴트 값인 2가 들어갔으며, 3/2의 결과인 1.5가 계산된다. 반면 divide(6, 3)의 경우 n에 3이라는 값을 입력하였으므로 6/3의 결과인 2가 계산되었다.
2.4.1. 람다 함수#
if문이나 for문을 한 줄로 간단하게 나타냈던 것과 같이, 람다(lambda)를 이용하면 간단하게 함수를 만들 수 있다. 람다의 사용법은 다음과 같다.
함수명 = lambda 매개변수1, 매개변수2, ...: statement
예제로 나눗셈을 하는 함수를 람다를 통해 만들어보도록 하자.
divide_lam = lambda x, n: x / n
divide_lam(6, 3)
2.0
위에서 def를 통해 만든 함수 divide()와 결과가 동일하다. 또한 람다를 통해 만든 함수는 return 명령어가 없어도 결괏값을 반환한다.
2.5. 패키지 사용하기#
패키지(package)는 기능이 비슷한 여러 함수들이 모여있는 꾸러미라고 볼 수 있으며, 파이썬이 사랑받는 이유 중 하나는 오픈 소스 생태계로 인해 다양한 패키지가 있다는 점도 크다. 전 세계의 사람들이 패키지를 만들어 온라인에 공개하고 있으며, 누구든지 이를 쉽게 다운로드 받아 사용할 수 있다. 파이썬 패키지를 공유하는 소프트웨어 저장소 PyPI(pypi.org)에는 39만개가 넘는 패키지가 공개되어 있다(2022년 8월 기준). 즉 복잡하게 코드를 짜지 않아도 기존의 패키지를 잘만 이용하면 매우 쉽게 개발 혹은 데이터 분석을 할 수 있다.
아나콘다에는 사람들이 자주 쓰는 주요 패키지가 대부분 들어있으므로(2022년 8월 기준 678개), 해당 패키지들의 경우 별도의 설치 과정이 없이 바로 사용할 수 있다. 아나콘다에 들어 있는 패키지 목록은 아래 페이지에서 확인할 수 있다.
https://docs.anaconda.com/anaconda/packages/py3.9_win-64/
패키지에 있는 함수를 사용하기 위해서는 [패키지 설치 → 패키지 불러오기 → 함수 사용] 의 단계를 거친다. 패키지는 한 번만 설치하면 되지만, 불러오는 작업은 파이썬을 새로 열때마다 반복해야 한다.
아나콘다에 포함되지 않은 패키지를 사용하기 위해서는 먼저 패키지를 설치해야 한다. 예로써 동적 크롤링에 사용되는 selenium 패키지를 설치해보도록 하자. 패키지를 설치하기 위해서는 아나콘다 프롬프트를 이용하면 된다. 윈도우의 경우 시작 메뉴를 클릭한 후 [Anaconda Prompt]를 검색한 후 실행한다.
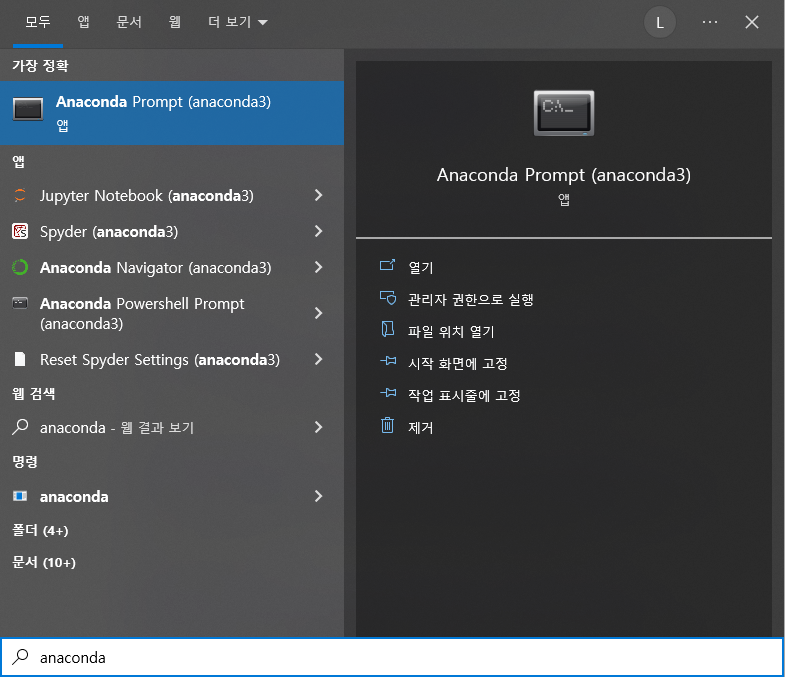
Fig. 2.3 아나콘다 프롬프트 검색 및 실행#
프롬프트에서 pip install 패키지명을 입력하면 패키지를 설치한다.
pip install selenium
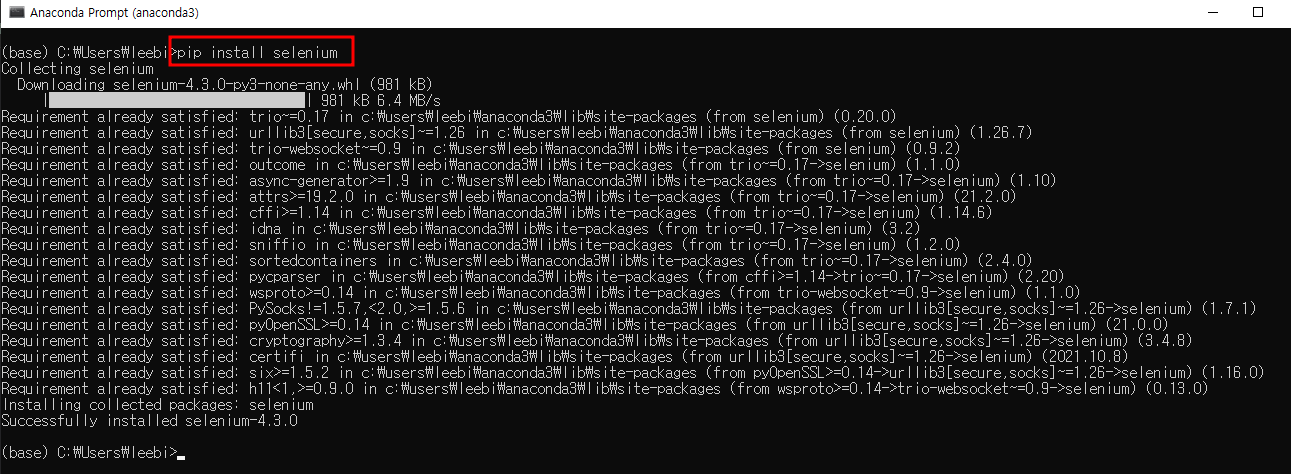
Fig. 2.4 selenium 패키지 다운로드#
코드를 실행하면 파이썬 패키지 저장소 PyPI(pypi.org)에서 패키지 관련 파일을 다운로드해 하드디스크에 설치하는 과정이 프롬프트에 출력된다. 만일 패키지 설치 중 ‘Proceed (y/n)?’ 라는 메시지가 나오면 ‘y’를 입력하고 엔터를 누르면 된다
아나콘다에 포함되어있는 패키지 외에 본 책의 이해를 위해 추가적으로 설치해야 하는 패키지는 다음과 같다.
selenium
webdriver_manager
tiingo
yahoo_fin
xmltodict
pandas_datareader
riskfolio-lib
bt
schedule
yfinance
yahooquery
pandas_ta
다운로드 받은 패키지를 사용하기 위해서는 이를 불러와야 한다. 패키지는 파이썬 스크립트에서 import 패키지이름을 통해 불러올 수 있다. 예를 들어 pandas 패키지를 불러오는 방법은 다음과 같다.
Note
riskfolio-lib 패키지 설치 방법은 14장에서 다시 설명하므로 이를 참조하기 바란다.
import pandas
패키지 이름은 해당 패키지 내의 함수들을 사용할 때 계속해서 사용된다. 만일 패키지 이름이 너무 길면 이를 매번 입력하는것이 불편하기 때문에 import 패키지이름 as 패키지별명 형태로 불러올 수 있다. pandas 패키지는 일반적으로 pd로 별명을 지정한다.
import pandas as pd
불러온 패키지 안의 내용을 살펴볼 때는 dir(패키지이름) 혹은 dir(패키지별명)을 입력한다.
import selenium
dir(selenium)
['__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__',
'__version__']
많은 패키지들은 하위 패키지를 가지고 있다. 하위 패키지 중에는 상위 패키지를 불러올 때 자동으로 불러오지만 것이 있지만 그렇지 않는 것도 있다. 자동으로 불러오지 않는 하위 패키지는 다음처럼 수동으로 불러와야 한다.
import selenium.webdriver
dir(selenium.webdriver)[1:20]
['Chrome',
'ChromeOptions',
'ChromeService',
'ChromiumEdge',
'DesiredCapabilities',
'Edge',
'EdgeOptions',
'EdgeService',
'Firefox',
'FirefoxOptions',
'FirefoxProfile',
'FirefoxService',
'Ie',
'IeOptions',
'IeService',
'Keys',
'Proxy',
'Remote',
'Safari']
패키지의 함수를 사용하기 위해서는 패키지이름.함수() 혹은 패키지별명.함수()를 입력한다.
import seaborn as sns
iris = sns.load_dataset('iris')
iris
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
150 rows × 5 columns
먼저 seaborn 패키지를 sns라는 별명으로 불러온 후, 데이터셋을 불러오는 함수인 load_dataset()을 이용해 ‘iris’ 데이터셋을 불러왔다.
패키지를 불러올때 모든 함수를 불러오는 것이 아닌 특정 함수만 선택해서 불러올 수도 있다. 이는 from 패키지이름 import 함수 혹은 from 패키지이름 import 함수1, 함수2, 함수3 형태로 불러온다.
from seaborn import load_dataset
load_dataset('iris')
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
150 rows × 5 columns
이번에는 seaborn 패키지에서 load_dataset() 함수만 불러왔다. 이처럼 특정 함수만 불러온 경우, 함수명 앞에 패키지이름을 붙여주지 않아도 함수가 작동한다. 만일 한번에 모든 함수를 불러오고 싶을 때는 from 패키지이름 import * 를 입력하면 된다.
2.5.1. 함수와 메서드의 차이#
파이썬 관련 책을 살펴보면 똑같이 something() 형태로 생겼지만 어떤 것은 함수, 어떤 것은 메서드라 불린다. 먼저 함수는 특정 기능을 수행하는 역할을 하며, 각 함수마다 나름의 기능을 가지고 있다. 예를 들어 파이썬의 내장 함수인 sum()은 합계를 구한다.
sum([1, 2])
3
특정 패키지에서 제공하는 함수도 있다. pandas의 DataFrame() 함수는 데이터프레임을 만드는 역할을 한다.
import pandas as pd
df = pd.DataFrame({'x' : [1,2,3]})
df
| x | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
반면 메서드는 클래스 및 객체와 연관되어 있는 함수다. info() 메서드는 위에서 만든 데이터프레임 객체의 정보를 보여준다.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 3 non-null int64
dtypes: int64(1)
memory usage: 156.0 bytes
각 객체 혹은 자료 구조에 따라 사용할 수 있는 메서드가 다르다. info() 메서드는 데이터프레임에는 사용할 수 있지만, 리스트 객체에는 사용할 수 없다.
lst = [1,2,3]
lst.info()
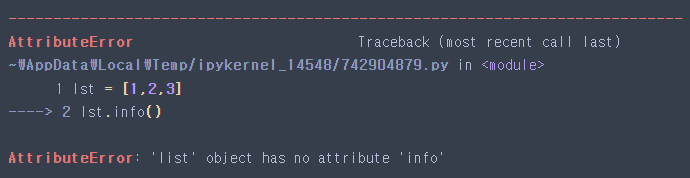
위 코드를 실행하면 AttributeError: ‘list’ object has no attribute ‘info’ 라는 에러가 뜬다. list 객체는 info() 매서드를 보유하고 있지 않아 에러가 발생하는 것이다. 즉 함수는 sum(), pd.DataFrame()과 같이 독립적으로 사용되는 반면, 메서드는 a라는 특정 객체가 존재할 때 a.head(), a.info()와 같은 형태로 사용된다.