12. 투자 참고용 데이터 수집#
이번 장에서는 주식과 재무제표 같은 금융 데이터 외에 투자에 도움이 될 수 있는 기업의 공시내용 및 각종 투자 지표를 수집하는 방법에 대해 알아보도록 하겠다.
12.1. DART의 Open API를 이용한 데이터 수집하기#
DART(Data Analysis, Retrieval and Transfer System)는 금융감독원 전자공시시스템으로써, 상장법인 등이 공시서류를 인터넷으로 제출하고, 투자자 등 이용자는 제출 즉시 인터넷을 통해 조회할 수 있도록 하는 종합적 기업공시 시스템이다. 홈페이지에서도 각종 공시내역을 확인할 수 있지만, 해당 사이트에서 제공하는 API를 이용할 경우 더욱 쉽게 공시 내용을 수집할 수 있다.
12.1.1. API Key 발급 및 추가하기#
먼저 https://opendart.fss.or.kr/ 에서 회원가입을 한 후 [인증키 신청/관리] → [인증키 신청]을 통해 API Key를 발급받아야 한다.

Fig. 12.1 OpenAPI 인증키 신청#
계정을 생성하고 이메일을 통해 이용자 등록을 한 후 로그인을 한다. 그 후 [오픈API 이용현황]을 살펴보면 API Key 부분에 발급받은 Key가 있으며, 금일 몇번의 API를 요청했는지가 일일이용현황에 나온다. 하루 총 10,000번까지 데이터를 요청할 수 있다.
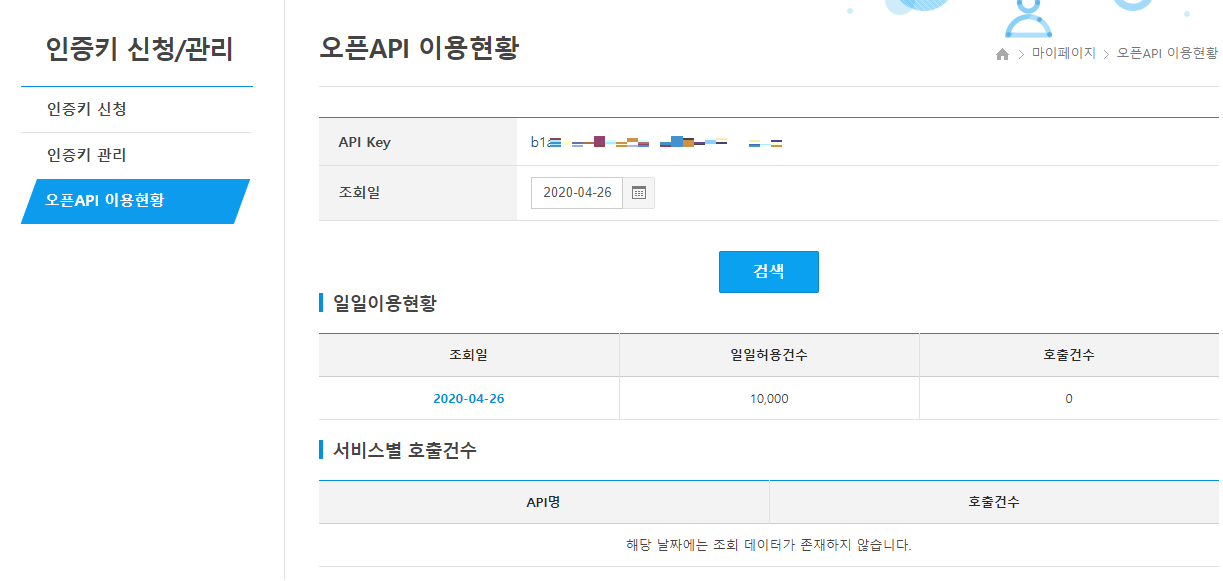
Fig. 12.2 OpenAPI 이용현황#
다음으로 발급받은 API Key를 keyring 패키지를 이용해 저장한다.
import keyring
keyring.set_password('dart_api_key', 'User Name', 'Password')
12.1.2. 고유번호 다운로드#
Open API에서 각 기업의 데이터를 받기 위해서는 종목에 해당하는 고유번호를 알아야한다. 이에 대한 자세한 내용은 홈페이지(https://opendart.fss.or.kr/)에서 [개발가이드 → 공시정보 → 고유번호] 화면에 설명되어 있다.
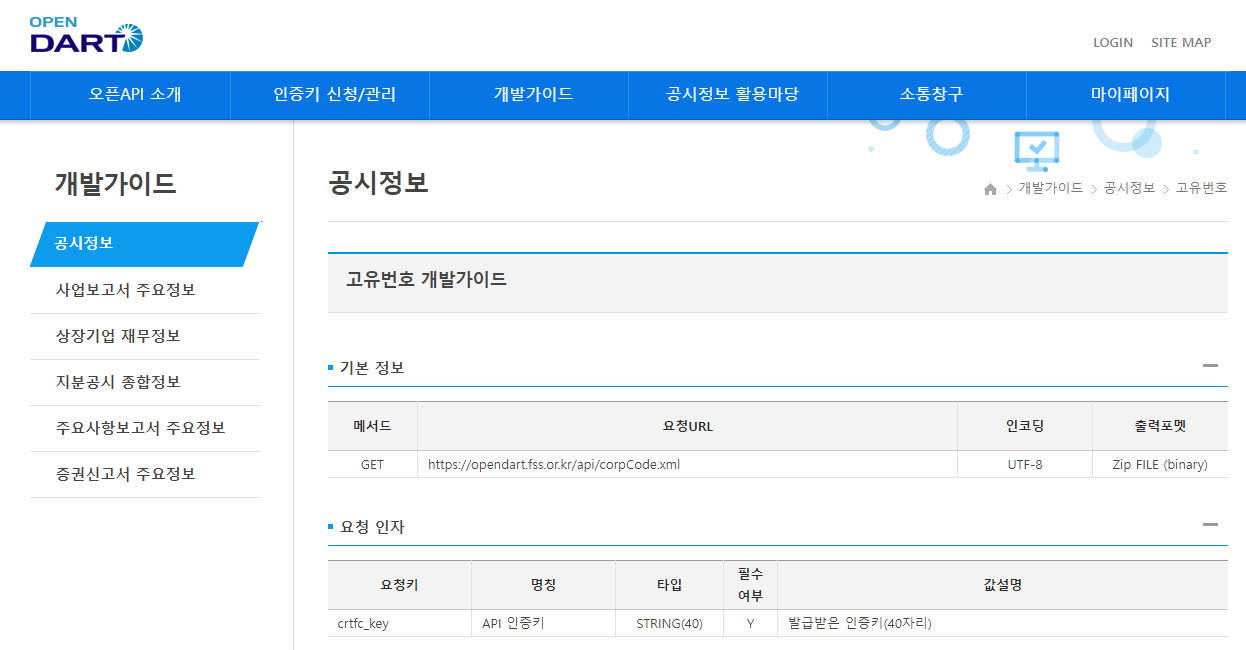
Fig. 12.3 OPEN API 개발가이드#
위 페이지의 내용을 코드로 나타내보도록 하자.
import keyring
import requests as rq
from io import BytesIO
import zipfile
api_key = keyring.get_password('dart_api_key', 'Henry')
codezip_url = f'''https://opendart.fss.or.kr/api/corpCode.xml?crtfc_key={api_key}'''
codezip_data = rq.get(codezip_url)
codezip_data.headers
{'Cache-Control': 'no-cache, no-store', 'Connection': 'keep-alive', 'Set-Cookie': 'WMONID=VFGuqP5ftuv; Expires=Tue, 11-Feb-2025 17:13:28 GMT; Path=/', 'Pragma': 'no-cache', 'Expires': '0', 'Content-Transfer-Encoding': 'binary', 'Content-Disposition': ': attachment; filename=CORPCODE.zip', 'Date': 'Mon, 12 Feb 2024 08:13:28 GMT', 'Content-Type': 'application/x-msdownload;charset=UTF-8', 'Content-Length': '1765078'}
get_password()함수를 통해 API Key를 불러온다.https://opendart.fss.or.kr/api/corpCode.xml?crtfc_key= 뒤에 본인의 API 키를 입력한다.
get()함수를 통해 해당 페이지 내용을 받는다.헤더를 확인해보면 ‘attachment; filename=CORPCODE.zip’, 즉 파일이 첨부되어 있다. 이에 대해 좀더 자세히 알아보도록 하자.
codezip_data.headers['Content-Disposition']
': attachment; filename=CORPCODE.zip'
headers의 ‘content-disposition’ 부분을 확인해보면 ‘CORPCODE.zip’ 파일이 첨부되어 있다. 해당 파일의 압축을 풀어 첨부된 내용을 확인해보자.
codezip_file = zipfile.ZipFile(BytesIO(codezip_data.content))
codezip_file.namelist()
['CORPCODE.xml']
BytesIO()를 통해 바이너리스트림 형태로 만든 후, ZipFile() 함수를 통해 압축을 풀어준다. namelist()를 통해 파일명을 확인해보면 ‘CORPCODE.xml’라는 파일이 존재하며, 이를 불러오도록 하자.
import xmltodict
import json
import pandas as pd
code_data = codezip_file.read('CORPCODE.xml').decode('utf-8')
data_odict = xmltodict.parse(code_data)
data_dict = json.loads(json.dumps(data_odict))
data = data_dict.get('result').get('list')
corp_list = pd.DataFrame(data)
corp_list.head()
| corp_code | corp_name | stock_code | modify_date | |
|---|---|---|---|---|
| 0 | 00434003 | 다코 | None | 20170630 |
| 1 | 00434456 | 일산약품 | None | 20170630 |
| 2 | 00430964 | 굿앤엘에스 | None | 20170630 |
| 3 | 00432403 | 한라판지 | None | 20170630 |
| 4 | 00388953 | 크레디피아제이십오차유동화전문회사 | None | 20170630 |
read()메서드를 통해 ‘CORPCODE.xml’ 파일을 불러온 후,decode()메서드를 통해 UTF-8 형태로 변경한다.xmltodict 패키지의
parse()함수를 이용해 딕셔너리 형태로 변경한다.위 데이터를
dumps()함수를 통해 JSON 형태로 바꿔준 후,loads()함수를 통해 불러온다.get()함수를 통해 result 내에서 list 부분만 불러온다.데이터프레임 형태로 변경해준다.
해당 데이터의 길이를 확인해보자.
len(corp_list)
104025
corp_list[corp_list['stock_code'].isin([None])].head()
| corp_code | corp_name | stock_code | modify_date | |
|---|---|---|---|---|
| 0 | 00434003 | 다코 | None | 20170630 |
| 1 | 00434456 | 일산약품 | None | 20170630 |
| 2 | 00430964 | 굿앤엘에스 | None | 20170630 |
| 3 | 00432403 | 한라판지 | None | 20170630 |
| 4 | 00388953 | 크레디피아제이십오차유동화전문회사 | None | 20170630 |
len() 함수를 통해 종목수를 확인해보면 거래소의 상장 종목수보다 훨씬 많으며, 이는 stock_code 열이 빈 종목, 즉 거래소에 상장되지 않은 종목도 포함되어 있기 때문이다. 따라서 해당 데이터는 삭제하여 거래소 상장 종목만을 남긴 후 DB에 저장한다.
import pymysql
from sqlalchemy import create_engine
corp_list = corp_list[~corp_list.stock_code.isin(
[None])].reset_index(drop=True)
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/stock_db')
corp_list.to_sql(name='dart_code', con=engine, index=True, if_exists='replace')
3697
Fig. 12.4 고유번호 테이블#
12.1.3. 공시 데이터#
12.1.3.1. 전체 종목의 공시 데이터 수집#
먼저 전체 종목의 공시를 수집하도록 하며, 개발가이드는 [개발가이드 → 공시정보 → 공시검색]에 나와있다. 각종 요청인자를 통해 URL을 생성 후 전송하여, 요청에 맞는 데이터를 받을 수 있다. 공시 검색에 해당하는 인자는 Fig. 12.5와 같다.
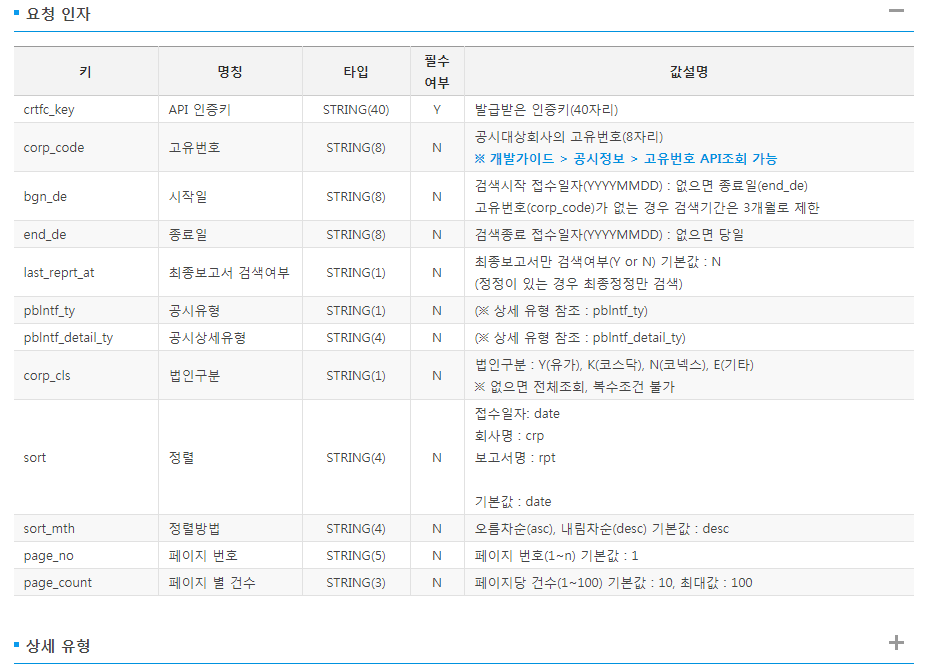
Fig. 12.5 OpenAPI 요청 인자 예시#
페이지 하단에서 인자를 입력 후 [검색]을 누르면 Fig. 12.6와 같이 각 인자에 맞게 생성된 URL과 그 결과를 볼 수 있다.
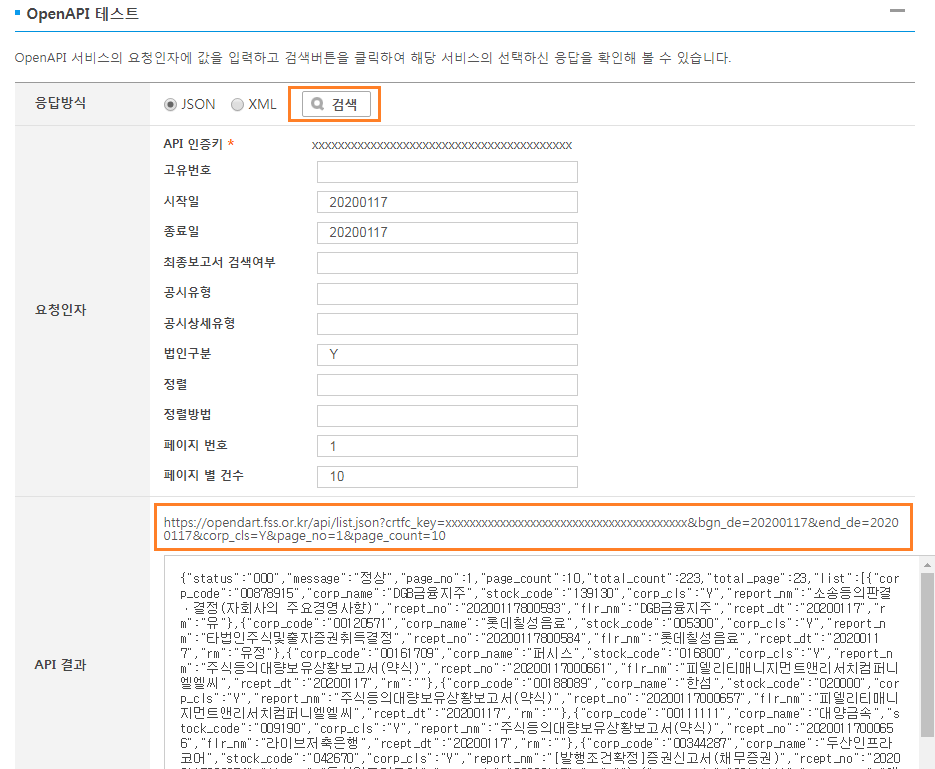
Fig. 12.6 OpenAPI 테스트 예시#
이를 참조하여 시작일과 종료일을 토대로 최근 공시 100건에 해당하는 URL을 생성한다.
from datetime import date
from dateutil.relativedelta import relativedelta
bgn_date = (date.today() + relativedelta(days=-7)).strftime("%Y%m%d")
end_date = (date.today()).strftime("%Y%m%d")
notice_url = f'''https://opendart.fss.or.kr/api/list.json?crtfc_key={api_key}
&bgn_de={bgn_date}&end_de={end_date}&page_no=1&page_count=100'''
notice_data = rq.get(notice_url)
notice_data_df = notice_data.json().get('list')
notice_data_df = pd.DataFrame(notice_data_df)
notice_data_df.tail()
| corp_code | corp_name | stock_code | corp_cls | report_nm | rcept_no | flr_nm | rcept_dt | rm | |
|---|---|---|---|---|---|---|---|---|---|
| 95 | 00372688 | 티사이언티픽 | 057680 | K | 증권발행결과(자율공시)(제3자배정 유상증자) | 20220805900490 | 티사이언티픽 | 20220805 | 코 |
| 96 | 00113465 | 하나증권 | E | 증권발행실적보고서 | 20220805000463 | 하나증권 | 20220805 | ||
| 97 | 00113465 | 하나증권 | E | 증권발행실적보고서 | 20220805000462 | 하나증권 | 20220805 | ||
| 98 | 00355548 | 한국테크놀로지 | 053590 | K | 주식등의대량보유상황보고서(일반) | 20220805000460 | 한국이노베이션 | 20220805 | |
| 99 | 00132868 | 성안 | 011300 | Y | 최대주주등소유주식변동신고서 | 20220805800507 | 성안 | 20220805 | 유 |
‘bgn_date’에는 현재로부터 일주일 전 날짜룰, ‘end_date’는 오늘 날짜를, 페이지별 건수에 해당하는 ‘page_count’에는 100을 입력한다.
홈페이지에 나와있는 예시에 맞게 URL을 작성해준다.
get()함수를 통해 해당 페이지 내용을 받는다.json()함수를 통해 JSON 데이터를 불러온 후, list 부분만을 선택한다.데이터프레임 형태로 변경한다.
데이터를 확인해보면 우리가 원하는 공시정보, 즉 일주일 전부터 오늘까지 전체 종목에 대한 100건의 공시 정보를 받을 수 있다.
12.1.3.2. 특정 기업의 공시 데이터 수집#
이번에는 고유번호를 추가하여 전체 종목이 아닌 원하는 기업의 공시만 받도록 한다. 예시로써 삼성전자의 공시 데이터를 수집하겠으며, 삼성전자의 고유번호는 ‘00126380’ 다.
corp_list[corp_list['corp_name'] == '삼성전자']
| corp_code | corp_name | stock_code | modify_date | |
|---|---|---|---|---|
| 2432 | 00126380 | 삼성전자 | 005930 | 20220509 |
bgn_date = (date.today() + relativedelta(days=-30)).strftime("%Y%m%d")
end_date = (date.today()).strftime("%Y%m%d")
corp_code = '00126380'
notice_url_ss = f'''https://opendart.fss.or.kr/api/list.json?crtfc_key={api_key}
&corp_code={corp_code}&bgn_de={bgn_date}&end_de={end_date}&page_no=1&page_count=100'''
notice_data_ss = rq.get(notice_url_ss)
notice_data_ss_df = notice_data_ss.json().get('list')
notice_data_ss_df = pd.DataFrame(notice_data_ss_df)
notice_data_ss_df.tail()
| corp_code | corp_name | stock_code | corp_cls | report_nm | rcept_no | flr_nm | rcept_dt | rm | |
|---|---|---|---|---|---|---|---|---|---|
| 18 | 00126380 | 삼성전자 | 005930 | Y | 임원ㆍ주요주주특정증권등소유상황보고서 | 20220707000377 | 김도형 | 20220707 | |
| 19 | 00126380 | 삼성전자 | 005930 | Y | 기업설명회(IR)개최(안내공시) | 20220707800073 | 삼성전자 | 20220707 | 유 |
| 20 | 00126380 | 삼성전자 | 005930 | Y | 연결재무제표기준영업(잠정)실적(공정공시) | 20220707800057 | 삼성전자 | 20220707 | 유정 |
| 21 | 00126380 | 삼성전자 | 005930 | Y | 임원ㆍ주요주주특정증권등소유상황보고서 | 20220706000249 | 박종만 | 20220706 | |
| 22 | 00126380 | 삼성전자 | 005930 | Y | 임원ㆍ주요주주특정증권등소유상황보고서 | 20220706000082 | 홍형선 | 20220706 |
시작일을 과거 30일로 수정하였으며, 기존 URL에 종목코드에 해당하는 ‘&corp_code=’ 부분을 추가한다.
그 이후 진행과정은 이전과 동일하다.
데이터 중 ‘rcept_no’는 공시번호에 해당하며, 해당 데이터를 이용해 공시에 해당하는 URL에 접속하여 내역을 확인할 수도 있다.
notice_url_exam = notice_data_ss_df.loc[0, 'rcept_no']
notice_dart_url = f'http://dart.fss.or.kr/dsaf001/main.do?rcpNo={notice_url_exam}'
print(notice_dart_url)
http://dart.fss.or.kr/dsaf001/main.do?rcpNo=20220803000274
dart 홈페이지의 공시에 해당하는 URL과 공시번호를 합쳐준다. 위 URL에 접속하여 해당 공시를 좀 더 자세하게 확인할 수 있다.

Fig. 12.7 공시 정보의 확인#
12.1.4. 사업보고서 주요 정보#
API를 이용하여 사업보고서의 주요 정보 역시 다운로드 받을 수 있으며, 제공하는 목록은 다음과 같다.
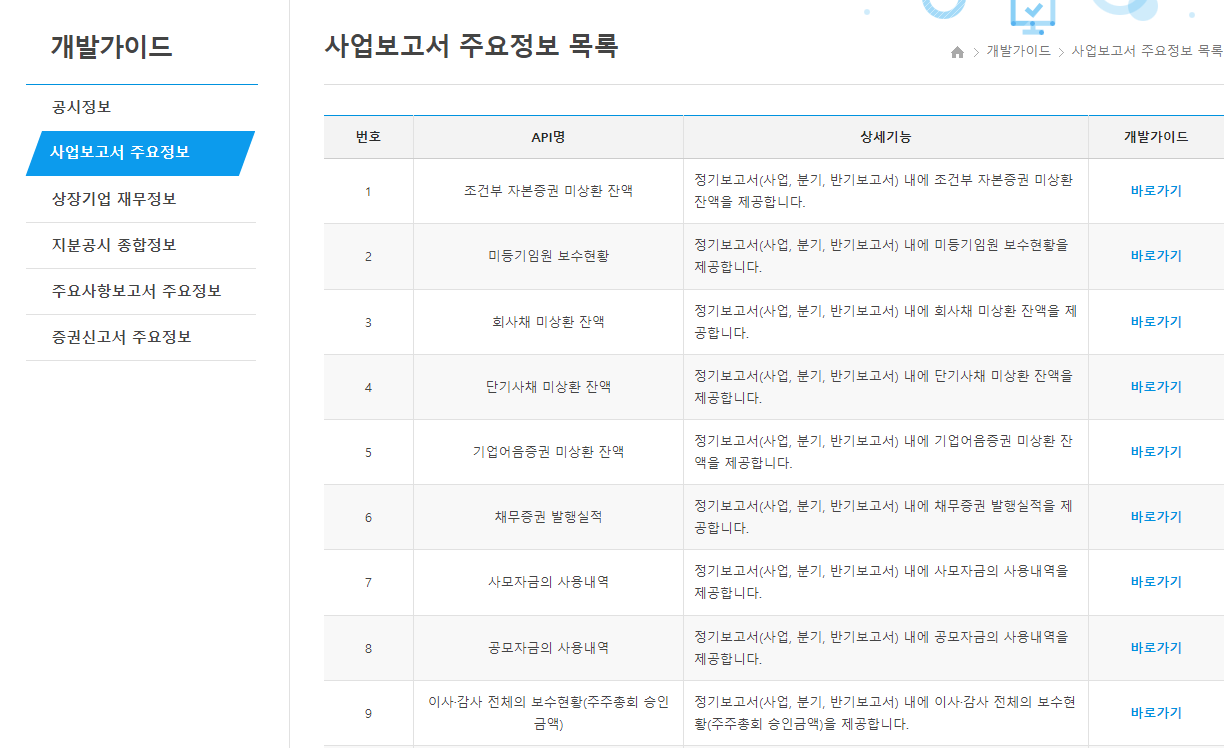
Fig. 12.8 사업보고서 주요정보 목록#
이 중 예시로써 [배당에 관한 사항]을 다운로드 받도록 하자. URL 생성에 필요한 요청 인자는 다음과 같다.
키 |
명칭 |
설명 |
|---|---|---|
crtfc_key |
API 인증키 |
발급받은 인증키 |
corp_code |
고유번호 |
공시대상회사의 고유번호(8자리) |
bsns_year |
사업년도 |
사업연도(4자리) |
reprt_code |
보고서 코드 |
1분기보고서 : 11013 |
이를 바탕으로 삼성전자의 2021년 사업보고서를 통해 배당에 관한 사항을 살펴보도록 하자.
corp_code = '00126380'
bsns_year = '2021'
reprt_code = '11011'
url_div = f'''https://opendart.fss.or.kr/api/alotMatter.json?crtfc_key={api_key}
&corp_code={corp_code}&bsns_year={bsns_year}&reprt_code={reprt_code}'''
div_data_ss = rq.get(url_div)
div_data_ss_df = div_data_ss.json().get('list')
div_data_ss_df = pd.DataFrame(div_data_ss_df)
div_data_ss_df.head()
| rcept_no | corp_cls | corp_code | corp_name | se | thstrm | frmtrm | lwfr | stock_knd | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 20220308000798 | Y | 00126380 | 삼성전자 | 주당액면가액(원) | 100 | 100 | 100 | NaN |
| 1 | 20220308000798 | Y | 00126380 | 삼성전자 | (연결)당기순이익(백만원) | 39,243,791 | 26,090,846 | 21,505,054 | NaN |
| 2 | 20220308000798 | Y | 00126380 | 삼성전자 | (별도)당기순이익(백만원) | 30,970,954 | 15,615,018 | 15,353,323 | NaN |
| 3 | 20220308000798 | Y | 00126380 | 삼성전자 | (연결)주당순이익(원) | 5,777 | 3,841 | 3,166 | NaN |
| 4 | 20220308000798 | Y | 00126380 | 삼성전자 | 현금배당금총액(백만원) | 9,809,438 | 20,338,075 | 9,619,243 | NaN |
API 인증키, 고유번호, 사업년도, 보고서 코드에 해당하는 데이터를 입력하여 URL을 생성하고, 앞에서 했던것과 동일한 방식으로 데이터를 불러온다. 데이터를 확인해보면, 사업보고서 중 배당에 관한 사항만이 나타나 있다. 위 URL의 ‘alotMatter’ 부분을 각 사업보고서에 해당하는 값으로 변경해주면 다른 정보 역시 동일한 방법으로 수집이 가능하다.
12.2. FRED 데이터 다운로드#
미국 연방준비은행에서 관리하는 Federal Reserve Economic Data(FRED)는 미국 및 각국의 중요 경제지표 데이터를 살펴볼 때 가장 많이 참조되는 곳 중 하나이다. 509,000여 개의 방대한 데이터를 API 형태로 제공하고 있으며, pandas_datareader 패키지의 DataReader() 함수를 이용하면 이곳에서 제공하는 여러 데이터를 쉽게 받을 수 있다.
12.2.1. 장단기 금리차#
장기로 돈을 빌리는 것이 단기로 빌리는 것보다 위험하므로 금리 역시 높아야 하는 것이 당연하며, 이러한 장기금리와 단기금리간의 차이를 기간 프리미엄(Term Premium)이라고 한다. 그러나 가끔씩 장기금리가 단기금리보다 낮아지는 현상이 발생하며, 이는 주요 금융시장 및 경제지표 가운데 경기침체에 대한 예측력이 가장 정확한 것으로 알려져 있다. 실제로 미국에서는 1960년 이후 발생한 모든 경기침체에 앞서 장단기 금리가 역전되어 음수가 되었다.
FRED에서 각 항목별 코드를 찾는 방법은 매우 간단하다. 먼저 FRED 웹사이트(https://fred.stlouisfed.org/) 에서 원하는 데이터를 검색한다. 만일 ‘10년-2년 장단기 금리차’에 해당하는 코드를 찾고자 한다면 [10-Year Treasury Constant Maturity Minus 2-Year Treasury Constant Maturity]를 검색하여 해당 페이지로 이동한다. 이 중 Fig. 12.9에서 네모로 표시한 [T10Y2Y]가 10년 금리와 2년 금리차의 코드에 해당한다. 동일한 방법으로 10년 금리와 3개월 금리 차이에 해당하는 [10-Year Treasury Constant Maturity Minus 3-Month Treasury Constant Maturity]를 검색해보면 해당 코드가 [T10Y3M]임을 알 수 있다.
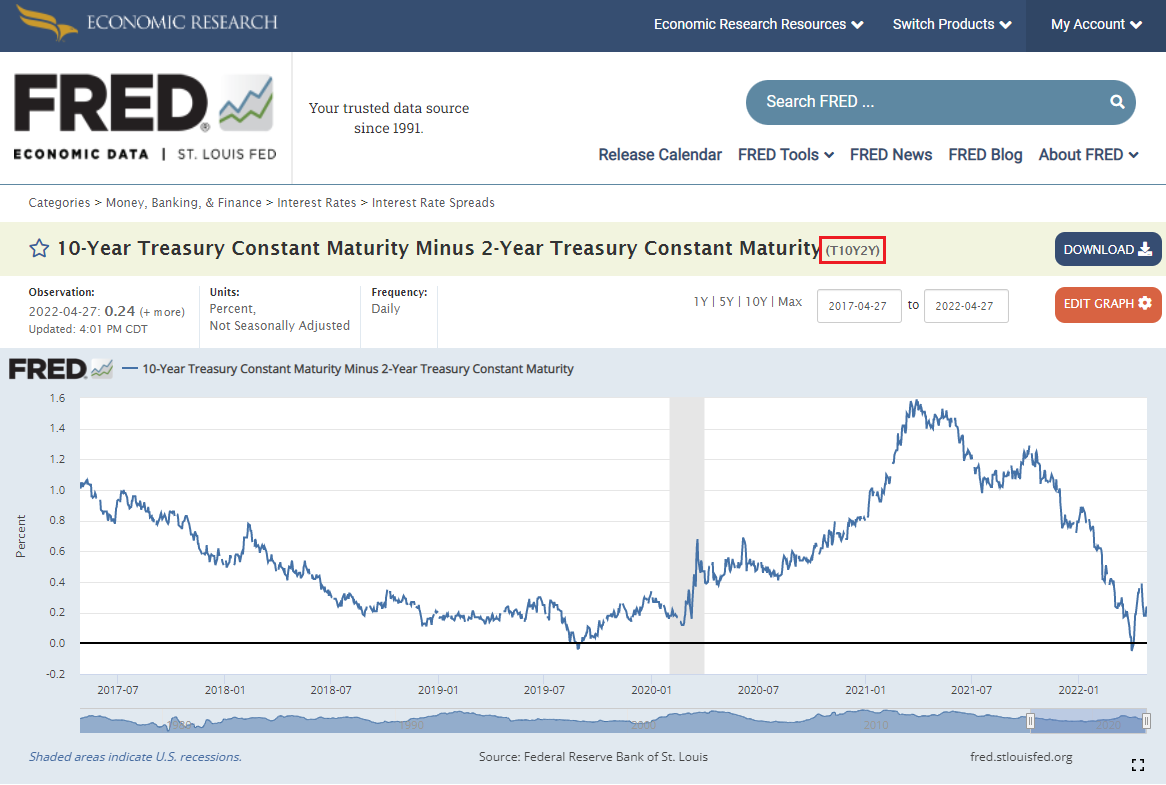
Fig. 12.9 FRED 코드 확인#
해당 데이터를 다운로드 받아보자.
import pandas_datareader as web
import pandas as pd
t10y2y = web.DataReader('T10Y2Y', 'fred', start='1990-01-01')
t10y3m = web.DataReader('T10Y3M', 'fred', start='1990-01-01')
rate_diff = pd.concat([t10y2y, t10y3m], axis=1)
rate_diff.columns = ['10Y - 2Y', '10Y - 3M']
rate_diff.tail()
| 10Y - 2Y | 10Y - 3M | |
|---|---|---|
| DATE | ||
| 2022-07-29 | -0.22 | 0.26 |
| 2022-08-01 | -0.30 | 0.04 |
| 2022-08-02 | -0.31 | 0.19 |
| 2022-08-03 | -0.37 | 0.21 |
| 2022-08-04 | -0.35 | 0.18 |
데이터 출처에 해당하는 부분에 ‘fred’를 입력하면 FRED의 API를 통해 데이터를 받아올 수 있다. 장단기 금리차를 주가 지수와 비교해 그려보도록 하자.
import matplotlib.pyplot as plt
import numpy as np
# 주가지수 다운로드
sp = web.DataReader('^GSPC', 'yahoo', start='1990-01-01')
plt.rc('font', family='Malgun Gothic')
plt.rc('axes', unicode_minus=False)
fig, ax1 = plt.subplots(figsize=(10, 6))
ax1.plot(t10y2y, color = 'black', linewidth = 0.5, label = '10Y-2Y')
ax1.plot(t10y3m, color = 'gray', linewidth = 0.5, label = '10Y-3M')
ax1.axhline(y=0, color='r', linestyle='dashed')
ax1.set_ylabel('장단기 금리차')
ax1.legend(loc = 'lower right')
ax2 = ax1.twinx()
ax2.plot(np.log(sp['Close']), label = 'S&P500')
ax2.set_ylabel('S&P500 지수(로그)')
ax2.legend(loc = 'upper right')
plt.show()
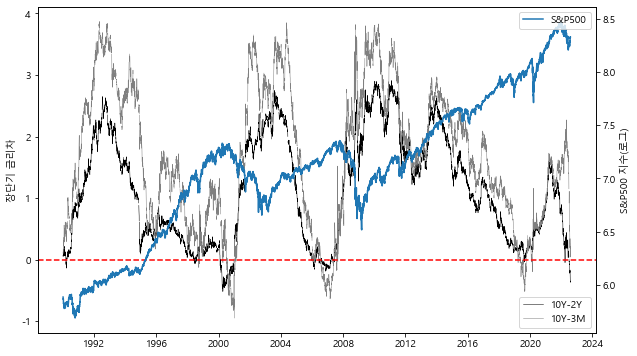
2000년 IT 버블, 20008년 금융위기, 2020년 코로나로 인한 하락 직전에는 항상 장단기 금리차가 음수를 기록했다.
12.2.2. 기대 인플레이션#
기대 인플레이션이란 현재 정보를 바탕으로 미래에 예상되는 인플레이션이다. 이는 다음과 같이 계산된다.
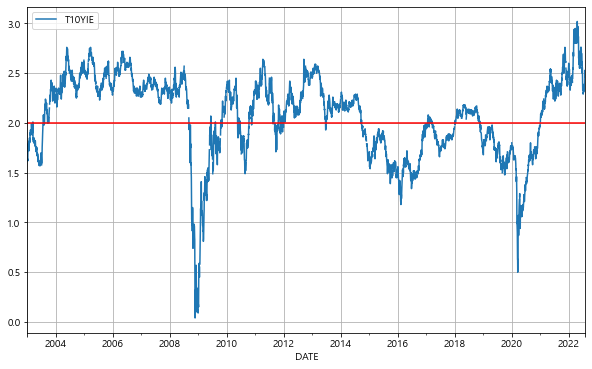
만일 향후 인플레이션이 올 것이라고 사람들이 전망한다면, 물가연동국채를 매수하므로 물가연동국채의 가격이 상승하고 해당 금리는 하락하게 될 것이다. 따라서 물가연동국채의 금리가 하락할 수록 기대 인플레이션은 상승한다. 기대 인플레이션 역시 자산의 가격에 매우 크게 영향을 미치는 요소이며, FED의 목표 중 하나가 인플레이션을 2%로 유지하는 것이므로, 해당 지표의 위치를 통해 FED의 향후 움직임 및 자산 가격의 변동을 예측할 수 있다. FRED에서 기대 인플레이션에 해당하는 코드는 [T10YIE] 이다. 해당 데이터를 받아보자.
import pandas_datareader as web
import pandas as pd
bei = web.DataReader('T10YIE', 'fred', start='1990-01-01')
bei.tail()
| T10YIE | |
|---|---|
| DATE | |
| 2022-07-29 | 2.53 |
| 2022-08-01 | 2.51 |
| 2022-08-02 | 2.48 |
| 2022-08-03 | 2.50 |
| 2022-08-04 | 2.46 |
이번에는 그래프로 나타내보도록 하자.
import matplotlib.pyplot as plt
bei.plot(figsize=(10, 6), grid=True)
plt.axhline(y=2, color='r', linestyle='-')
plt.show()
12.2.3. Fear & Greed Index#
CNN에서는 발표하는 Fear & Greed Index(공포와 탐욕 지수)는 투자 심리를 반영하는 대표적인 지수다. 해당 지수는 총 7개 지표를 이용해 계산된다.
주가의 강도
시장의 모멘텀
주가의 확산정도
시장 변동성
안전 자산에 대한 수요
풋옵션과 콜옵션 비율
투기 등급에 대한 수요
위 7개 지표를 합산하여 0점에서 100점 사이의 점수를 구하며, 점수가 낮을 수록 시장이 공포에 휩싸여 있음을, 점수가 높을 수록 시장이 탐욕에 물들어 있음을 나타낸다.
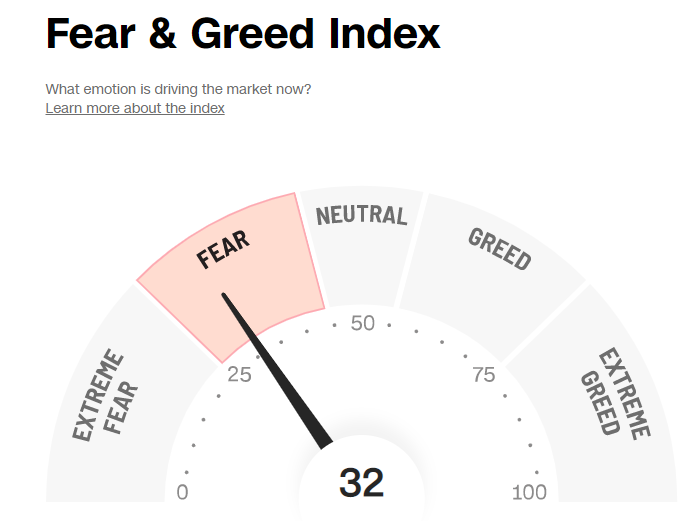
Fig. 12.10 Fear & Greed Index#
해당 지표는 아래 사이트에서 확인할 수 있다.
https://money.cnn.com/data/fear-and-greed/
개발자도구 화면을 통해 현재 점수가 위치하는 곳을 찾아보면, 클래스 이름이 [market-fng-gauge__dial-number-value]이며, 내용이 동적으로 계속 변하기에 정적 크롤링이 아닌 동적 크롤링을 이용해야 한다. 셀레니움을 사용해 해당 지표를 크롤링 해보자.
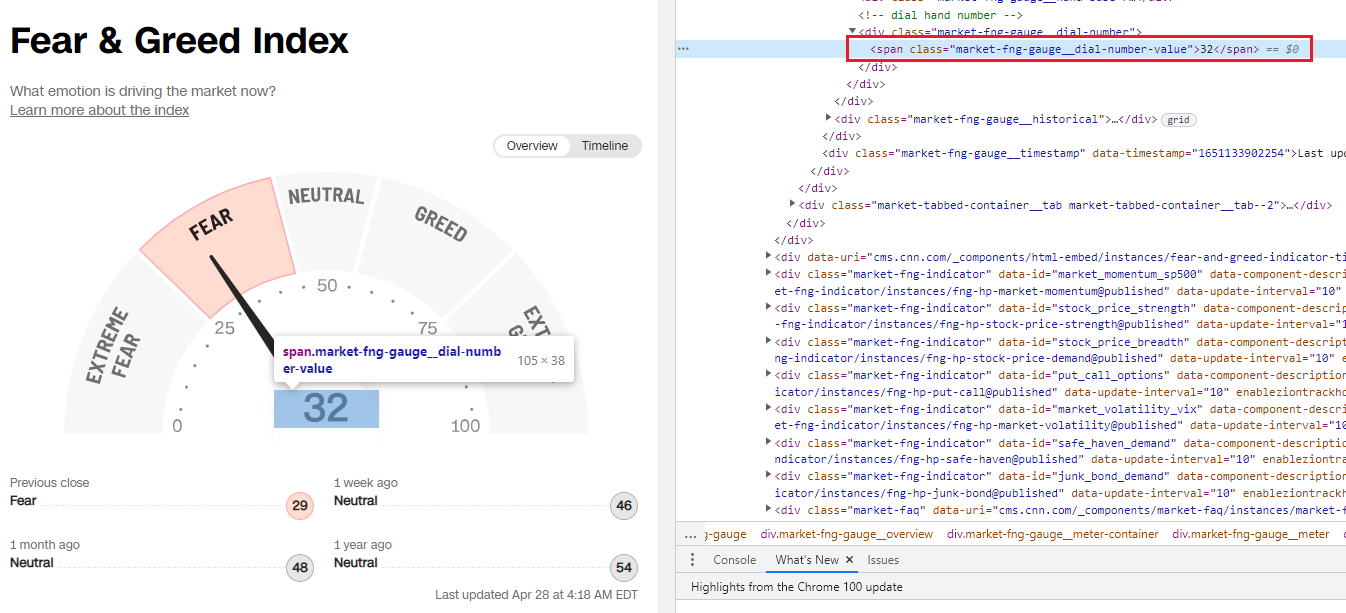
Fig. 12.11 해당 지표의 태그 확인#
import selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(url='https://edition.cnn.com/markets/fear-and-greed')
idx = driver.find_element(By.CLASS_NAME,
value='market-fng-gauge__dial-number-value').text
driver.close()
idx = int(idx)
print(idx)
47
크롬 드라이버를 로드한다.
해당 URL을 브라우저에 띄운다.
클래스명이 ‘market-fng-gauge__dial-number-value’인 곳을 찾은 후, 텍스트를 추출한다.
브라우저를 닫는다.
지표가 문자형이므로 정수형으로 변경한다.
해당 지표를 통해 투자 심리를 객관적으로 판단할 수 있다. ‘공포에 사서 탐욕에 팔아라’ 라는 투자 격언이 있듯이, 지표가 지나치게 낮은 공포 구간에서는 오히려 매수를, 지표가 지나치게 높은 탐욕 구간에서는 투자 비중을 줄이는 선택을 할 수 있다.