9. 동적 크롤링과 정규 표현식#
이번 장에서는 좀 더 복잡한 형태의 데이터를 크롤링하기 위한 동적 크롤링 및 정규 표현식의 사용방법에 대해 알아보도록 하겠다.
9.1. 동적 크롤링이란?#
지난 장에서 크롤링을 통해 웹사이트의 데이터를 수집하는 방법에 대해 배웠다. 그러나 일반적인 크롤링으로는 정적 데이터, 즉 변하지 않는 데이터만을 수집할 수 있다. 한 페이지 안에서 원하는 정보가 모두 드러나는 것을 정적 데이터라 한다. 반면 입력, 클릭, 로그인 등을 통해 데이터가 바뀌는 것을 동적 데이터라 한다. 예를 들어 네이버 지도에서 매장을 검색을 한 후 좌측에서 원하는 선택할 때 마다 이에 해당하는 내용이 뜬다.
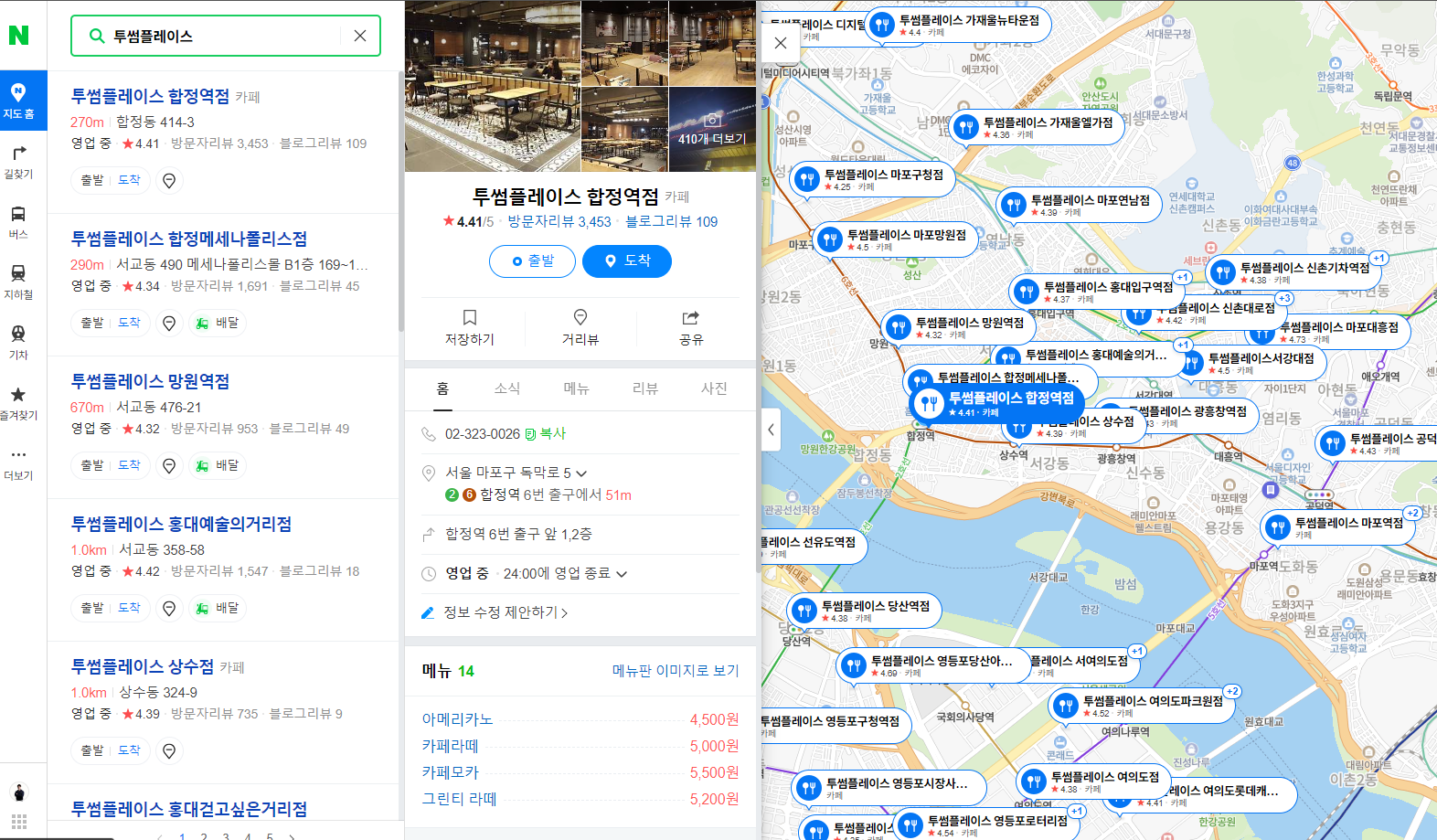
Fig. 9.1 동적 페이지#
이는 웹페이지에서 사용자가 클릭 등과 같은 조작을 하면 AJAX 호출이 발생하여 그 결과가 페이지의 일부분에만 반영되어 변경되기 때문이다. 즉 매장을 클릭하면 웹브라우저가 연결된 자바스크립트 코드를 실행하여 해당 매장의 상세 정보가 동일한 페이지에 동적으로 표시된다. Fig. 9.2은 정적 페이지와 동적 페이지의 작동 방식의 차이를 나타낸다.
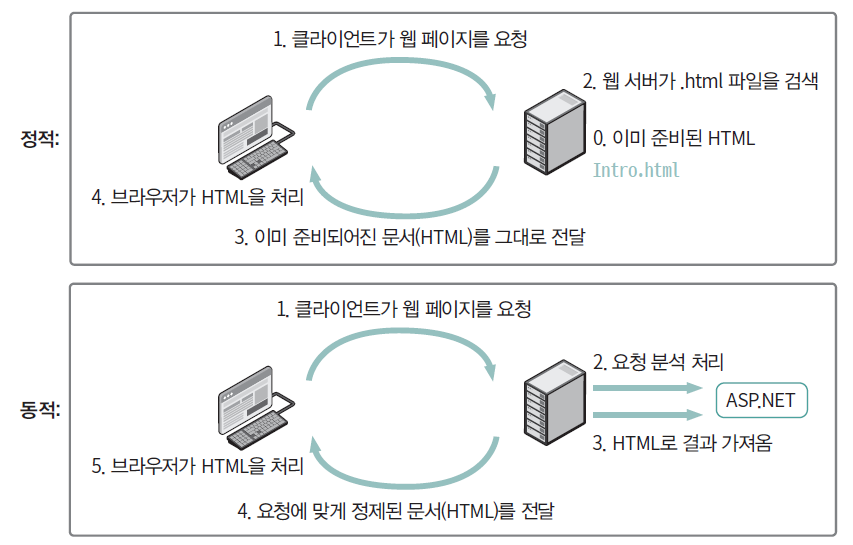
Fig. 9.2 정적 페이지와 동적 페이지의 차이#
셀레니움을 이용할 경우 정적 페이지와 동적 페이지를 모두 크롤링 할 수 있다는 강력함이 있지만, 상대적으로 속도가 느리다. 따라서 정적 페이지는 기존의 방법을 이용한 크롤링을, 동적 페이지는 셀레니움을 이용한 크롤링을 하는 것이 일반적이다.
구분 |
정적 크롤링 |
동적 크롤링 |
|---|---|---|
사용 패키지 |
requests |
selenium |
수집 커버리지 |
정적 페이지 |
정적/동적 페이지 |
수집 속도 |
빠름 (별도 페이지 조작 필요 X) |
상대적으로 느림 |
파싱 패키지 |
beautifulsoup |
beautifulsoup / selenium |
셀레니움이란 다양한 브라우저(인터넷 익스플로러, 크롬, 사파리 오페라 등) 및 플랫폼에서 웹 응용 프로그램을 테스트할 수 있게 해주는 라이브러리다. 즉 웹 자동화 테스트 용도로 개발이 되었기에 실제 브라우저를 사용하며, 페이지가 변화하는 것도 관찰이 가능하기에 동적 크롤링에 사용할 수 있다.
9.1.1. 셀레니움 실습하기#
이제 간단한 예제를 통해 셀레니움 사용법을 알아보도록 하자.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))

Fig. 9.3 셀레니움: 창 열기#
webdriver.Chrome(service=Service(ChromeDriverManager().install())) 코드를 실행하면 크롬 브라우저의 버전을 탐색한 다음, 버전에 맞는 웹드라이버를 다운로드하여 해당 경로를 셀레니움에 전달해준다. 또한 Fig. 9.3와 같이 크롬 창이 열리며, 좌측 상단에 ‘Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다.’라는 문구가 뜬다. 이제 파이썬 코드를 이용해 해당 페이지를 조작할 수 있다.
url = 'https://www.naver.com/'
driver.get(url)
driver.page_source[1:1000]
'html lang="ko" class="fzoom" data-dark="false"><head><script async="" src="https://ntm.pstatic.net/ex/nlog.js"></script><script async="" src="https://ntm.pstatic.net/scripts/ntm_27291e35193e.js"></script><script async="" type="text/javascript" src="https://ssl.pstatic.net/tveta/libs/ndpsdk/prod/ndp-core.js"></script> <meta charset="utf-8"> <meta name="Referrer" content="origin"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=1190"> <title>NAVER</title> <meta name="apple-mobile-web-app-title" content="NAVER"> <meta name="robots" content="index,nofollow"> <meta name="description" content="네이버 메인에서 다양한 정보와 유용한 컨텐츠를 만나 보세요"> <meta property="og:title" content="네이버"> <meta property="og:url" content="https://www.naver.com/"> <meta property="og:image" content="https://s.pstatic.net/static/www/mobile/edit/2016/0705/mobile_212852414260.png"> <meta property="og:description" content="네이버 메인에서 다양한 정보와 유용한 컨텐츠를 만나 보세요"> <meta name="twitter:card" content="'
Fig. 9.4 셀레니움을 이용한 네이버 접속#
driver.get() 내에 URL 주소를 입력하면 해당 주소로 이동한다. 또한 driver.page_source를 통해 열려있는 창의 HTML 코드를 확인할 수도 있다. 이제 네이버 메인에서 [뉴스]버튼을 누르는 동작을 실행해보자. 개발자도구 화면을 통해 확인해보면 [뉴스] 탭은 아래 HTML에 위치하고 있다.
<a href="https://news.naver.com/" class="link_service" target="_blank"><span class="service_icon type_news"></span><span class="service_name">뉴스</span></a>
위 정보를 통해 해당 부분을 클릭해보도록 하자.

Fig. 9.5 뉴스 탭의 HTML 확인#
driver.find_element(By.LINK_TEXT , value = '뉴스').click()
Fig. 9.6 뉴스 탭으로 이동#
새로운 탭이 열리면서 뉴스 화면이 열린다. 브라우저 상에서 보이는 버튼, 검색창, 사진, 테이블, 동영상 등을 엘레먼트(element, 요소)라고 한다. find_element()는 다양한 방법으로 엘레먼트에 접근하게 해주며, By.* 를 통해 어떠한 방법으로 엘레먼트에 접근할지 선언한다. LINK_TEXT의 경우 링크가 달려 있는 텍스트로 접근하며, value = '뉴스', 즉 뉴스라는 단어가 있는 엘레먼트로 접근한다. click() 함수는 마우스 클릭을 실행하며 결과 적으로 뉴스 탭을 클릭한 후 페이지가 이동되는 것을 확인할 수 있다. find_element() 내 접근방법 및 셀레니움의 각종 동작 제어 방법에 대해서는 나중에 다시 정리하도록 한다.
이제 해당 탭을 닫아보자.
driver.switch_to.window(driver.window_handles[1])
driver.close()
switch_to.window() 메서드는 인자로 전달된 창의 핸들로 드라이버의 컨트롤을 전환한다. 즉 driver.window_handles[1]를 통해 현재 열린 두번째 창으로 포커스를 이동한다. 이 후 close()를 통해 해당 페이지를 닫는다.
이제 특정 검색어를 검색하는 방법에 대해 알아보자. 먼저 검색창의 위치가 어디에 있는지 확인해보면 query라는 id와 search_input라는 class에 위치하고 있다.

Fig. 9.7 검색 창 위치 확인하기#
driver.switch_to.window(driver.window_handles[0])
driver.find_element(By.CLASS_NAME, value = 'search_input').send_keys('퀀트 투자 포트폴리오 만들기')

Fig. 9.8 검색어 입력하기#
먼저 driver.switch_to.window(driver.window_handles[0])를 통해 현재 탭으로 다시 포커스를 이동한다.
find_element() 내에 By.CLASS_NAME을 입력하면 클래스 명에 해당하는 엘레먼트에 접근하며, 여기서는 검색창에 접근한다. 그 후 send_keys() 내에 텍스트를 입력하면 해당 내용이 웹페이지에 입력된다. 이제 웹페이지에서 검색 버튼 해당하는 돋보기 모양을 클릭하거나 엔터키를 누르면 검색이 실행된다. 먼저 돋보기 모양의 위치를 확인해보면 btn_search 클래스에 위치하고 있다.
Fig. 9.9 검색 버튼의 위치 확인#
driver.find_element(By.CLASS_NAME, value = 'btn_search').send_keys(Keys.ENTER)
Fig. 9.10 엔터키 제어하기#
find_element(By.CLASS_NAME, value = 'btn_search')를 통해 검색 버튼에 접근한다. 그 후 send_keys(Keys.ENTER)를 입력하면 엔터키를 누르는 동작이 실행된다. 페이지를 확인해보면 검색이 실행된 후 결과를 확인할 수 있다.
이번에는 다른 단어를 검색해보도록 하자. 웹에서 기존 검색어 내용을 지운 후, 검색어를 입력하고, 버튼을 클릭해야 한다. 이를 위해 검색어 박스와 검색 버튼의 위치를 찾아보면 다음과 같다.
검색어 박스: nx_query id
검색 버튼: bt_search 클래스
Fig. 9.11 검색어 박스와 검색 버튼의 위치 확인#
driver.find_element(By.ID, value = 'nx_query').clear()
driver.find_element(By.ID, value = 'nx_query').send_keys('이현열 퀀트')
driver.find_element(By.CLASS_NAME, value = 'bt_search').click()
Fig. 9.12 새로운 단어 검색하기#
검색어 박스(nx_query)에 접근한 후,
clear()를 실행하면 모든 텍스트가 지워진다.send_keys('이현열 퀀트')를 실행하여 새로운 검색어를 입력한다.검색 버튼(bt_search)에 접근한 후,
click()을 실행하여 해당 버튼을 클릭한다.
이번에는 블로그에서 [최신순] 버튼을 클릭하는 동작을 실행해보도록 한다. 기존처럼 링크나 클래스명을 통해 엘레먼트에 접근할 수도 있지만, 이번에는 XPATH를 이용해 접근해보도록 하자. XPATH란 XML 중 특정 값의 태그나 속성을 찾기 쉽게 만든 주소다. 예를 들어 윈도우 탐색기에서는 특정 폴더의 위치가 ‘C:\Program Files’과 같이 주소처럼 보이며 이는 윈도우의 PATH 문법이다. XML 역시 이와 동일한 개념의 XPATH가 있다. 웹페이지에서 XPATH를 찾는 법은 다음과 같다.
개발자도구 화면에서 위치를 찾고 싶은 부분에서 마우스 우클릭을 한다.
[Copy → Copy Xpath]를 선택한다.
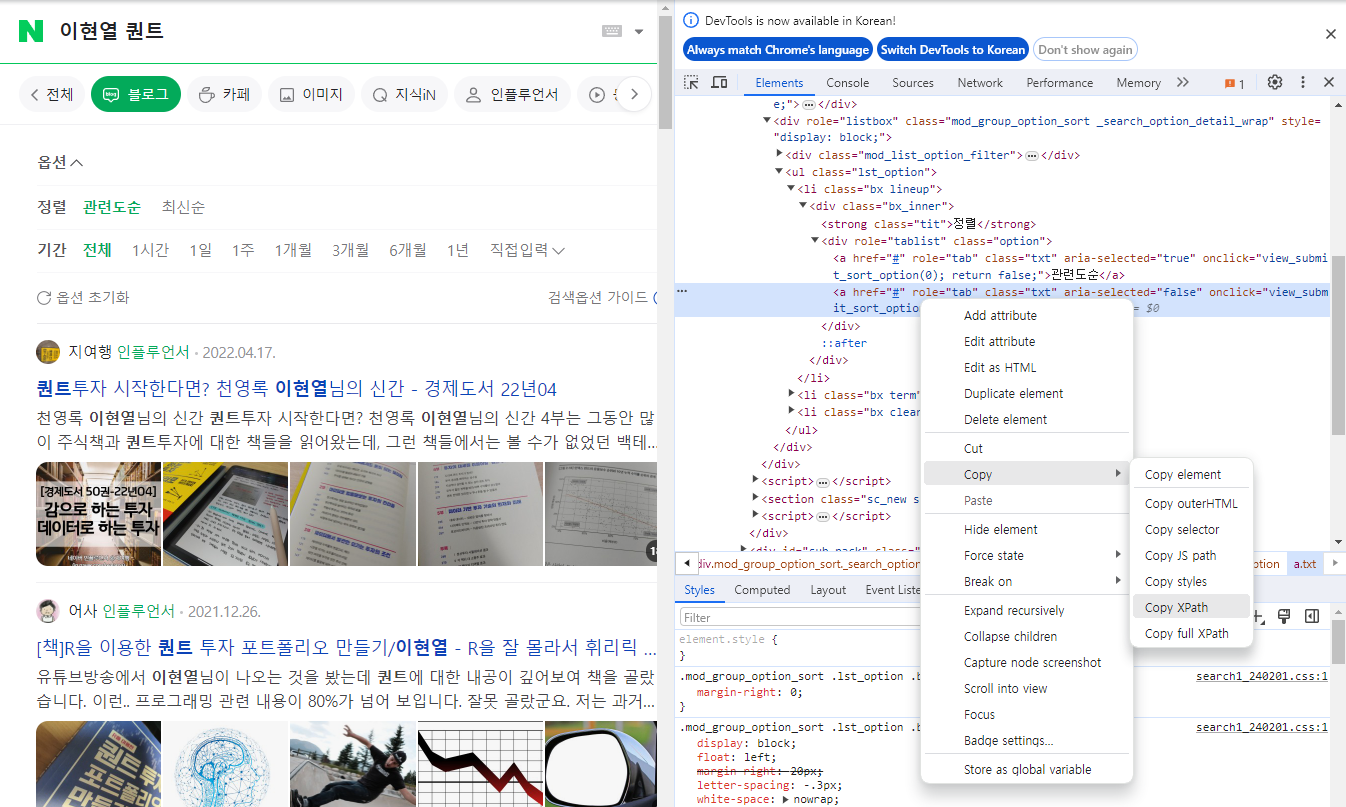
Fig. 9.13 XPATH 찾기 및 복사하기#
위 과정을 통해 XPATH가 복사된다. 메모장을 확인해보면 [최신순] 부분의 XPATH는 다음과 같다.
//*[@id="snb"]/div[2]/ul/li[1]/div/div/a[2]
이를 이용해 해당 부분을 클릭하는 동작을 실행해보자. 실행 순서는 [블로그 클릭 → 옵션 클릭 → 최신순 클릭] 순이다.
driver.find_element(By.XPATH, value = '//*[@id="lnb"]/div[1]/div/div[1]/div/div[1]/div[1]/a').click()
driver.find_element(By.XPATH, value = '//*[@id="snb"]/div[1]/div/div[2]/a').click()
driver.find_element(By.XPATH, value = '//*[@id="snb"]/div[2]/ul/li[1]/div/div/a[2]').click()
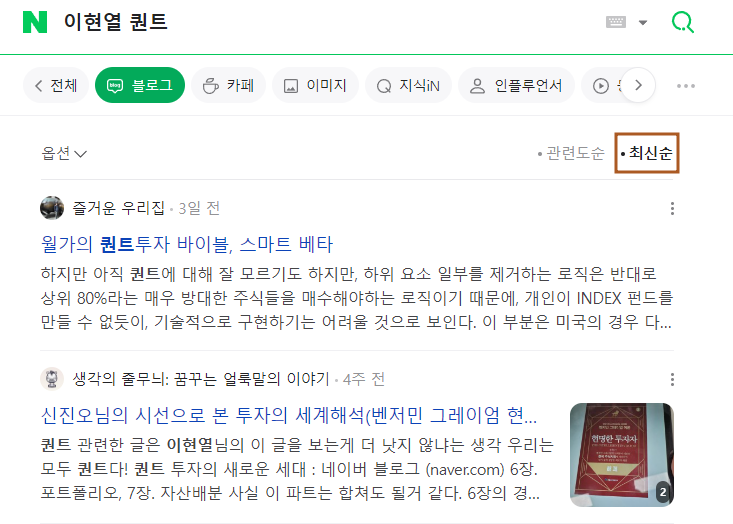
Fig. 9.14 최신순 정렬#
위의 순서대로 클릭하는 동작을 수행하여 검색어가 최신순으로 정렬되었다. 이제 page down 기능을 수행해보도록 하자.
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# driver.find_element(By.TAG_NAME, value = 'body').send_keys(Keys.PAGE_DOWN)
먼저 document.body.scrollHeight는 웹페이지의 높이를 나타내는 것으로써, window.scrollTo(0, document.body.scrollHeight);는 웹페이지의 가장 하단까지 스크롤을 내리라는 자바스크립트 명령어다. driver.execute_script()를 통해 해당 명령어를 실행하면 웹페이지가 아래로 스크롤이 이동된다. send_keys(Keys.PAGE_DOWN) 는 키보드의 페이지다운(PgDn) 버튼을 누르는 동작이며 이 역시 페이지가 아래로 이동시킨다.
그러나 결과를 살펴보면 스크롤이 끝까지 내려간 후 얼마간의 로딩이 있은 후에 새로운 데이터가 생성된다. 이처럼 유튜브나 인스타그램, 페이스북 등 많은 검색결과를 보여줘야 하는 경우 웹페이지 상에서 한 번에 모든 데이터를 보여주기 보다는 스크롤을 가장 아래로 위치하면 로딩을 거쳐 추가적인 결과를 보여준다. 따라서 스크롤을 한 번만 내리는 것이 아닌 모든 결과가 나올 때까지 내리는 동작을 실행해야 한다.
prev_height = driver.execute_script('return document.body.scrollHeight')
while True:
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
curr_height = driver.execute_script('return document.body.scrollHeight')
if curr_height == prev_height:
break
prev_height = curr_height
return document.body.scrollHeight은 현재의 창 높이는 반환하는 자바스크립트 명령어이며, 이를 prev_height에 저장한다.while문을 통해 반복문을 실행한다.
셀레니움을 통해 페이지의 최하단으로 스크롤을 내린다.
페이지가 로딩되는 시간을 기다리기 위해 2초간 슬립을 준다.
curr_height에 현재 창 높이를 저장한다.
curr_height와 prev_height가 동일하다는 의미는 페이지가 끝까지 내려왔다는 의미이다. 따라서 이 경우
break를 통해 while문을 멈추며, 그렇지 않을 경우 다시 스크롤을 내리는 동작을 반복한다.prev_height에 새로운 창 높이를 입력한다.
이제 모든 검색 결과가 나타났으면 이전 장에서 살펴보았던 정적 크롤링을 통해 데이터 수집이 가능하다. 제목 부분을 확인해보면 title_link 클래스에 위치하고 있으며, 이를 통해 모든 제목을 크롤링해보자.
html = BeautifulSoup(driver.page_source, 'lxml')
txt = html.find_all(class_ = 'title_link')
txt_list = [i.get_text() for i in txt]
txt_list[0:10]
['월가의 퀀트투자 바이블, 스마트 베타',
'신진오님의 시선으로 본 투자의 세계해석(벤저민 그레이엄 현명한 투자자 해석) - 현명한 투자자2 해제(신진오)',
'2019-1학기 금융공학회 기록',
'2023년 12월 주식 투자 결산',
'[독서기록 #34] 헤지펀드 열전 『금융시장에서 돈을 벌고 싶은데, 방법을 모르는 사람들은 꼭 읽어봐야... ',
'[책] 파이썬을 이용한 퀀트 투자 포트폴리오 만들기 (이현열)',
'[이런저런 공부] 포트폴리오 최적화의 예',
'20231122 멱(冪)파레토 독서법',
'[책] R을 이용한 퀀트 투자 포트폴리오 만들기 (이현열)',
'에드워드 소프의 생애에 관한 영상']
driver.page_source를 통해 현재 웹페이지의 HTML 정보를 가져올 수 있으며, 이를 BeautifulSoup 객체로 만들어준다.find_all()함수를 통해 제목 부분에 위치하는 데이터를 모두 불러온다.for문을 통해 텍스트만 추출한다.
이처럼 동적 페이지의 경우도 셀레니움을 통해 웹페이지를 제어한 후 BeautifulSoup 패키지를 사용해 원하는 부분을 추출하면 얼마든지 크롤링이 가능하다.
driver.quit()
driver.quit()을 실행하면 열려있던 페이지가 종료된다.
9.1.2. 셀레니움 명령어 정리#
마지막으로 셀레니움의 각종 명령어는 다음과 같다.
9.1.2.1. 브라우저 관련#
webdriver.Chrome(): 브라우저 열기driver.close(): 현재 탭 닫기driver.quit(): 브라우저 닫기driver.back(): 뒤로 가기driver.forward(): 앞으로 가기
9.1.2.2. 엘레먼트 접근#
driver.find_element(by = 'id', value = 'value') 중 by = ‘id’ 부분에 해당하는 방법에 따라 엘레먼트에 접근한다. 또한 find_element()는 해당하는 엘레먼트가 여러 개 있을 경우 첫 번째 요소 하나만을 반환하며, find_elements()는 여러 엘레먼트가 있을 경우 리스트로 반환한다.
By.ID: 태그의 ID 값으로 추출By.NAME: 태그의 NAME 값으로 추출By.XPATH: 태그의 XPATH 값으로 추출By.LINK_TEXT: 링크에 존재하는 텍스트로 추출By.TAG_NAME: 태그명으로 추출By.CLASS_NAME: 태그의 클래스명으로 추출By.CSS_SELECTOR: CSS 선택자로 추출
9.1.2.3. 동작#
엘레먼트에 접근한 후 각종 동작을 수행할 수 있다.
click(): 엘레먼트를 클릭clear(): 텍스트 삭제send_keys(text): 텍스트 입력send_keys(Keys.CONTROL + 'v'): 컨트롤 + v 누르기
9.1.2.4. 자바스크립트 코드 실행#
execute_script() 내에 자바스크립트 코드를 입력하여 여러가지 동작을 수행할 수 있다.
9.2. 정규 표현식#
정규 표현식(정규식)이란 프로그래밍에서 문자열을 다룰 때 문자열의 일정한 패턴을 표현하는 일종의 형식 언어를 말하며, 영어로는 regular expression를 줄여 일반적으로 regex라 표현한다. 정규 표현식은 파이썬만의 고유 문법이 아니라 문자열을 처리하는 모든 프로그래밍에서 사용되는 공통 문법이기에 한 번 알아두면 파이썬 뿐만 아니라 다른 언어에서도 쉽게 적용할 수 있다. 본 책의 내용은 아래 페이지의 내용을 참고하여 작성되었다.
https://docs.python.org/3.10/howto/regex.html
9.2.1. 정규 표현식을 알아야 하는 이유#
만약 우리가 크롤링한 결과물이 다음과 같다고 하자.
"동 기업의 매출액은 전년 대비 29.2% 늘어났습니다."
만일 이 중에서 [29.2%]에 해당하는 데이터만 추출하려면 어떻게 해야 할까? 얼핏 보기에도 꽤나 복잡한 방법을 통해 클렌징을 해야 한다. 그러나 정규 표현식을 이용할 경우 이는 매우 간단한 작업이다.
import re
data = '동 기업의 매출액은 전년 대비 29.2% 늘어났습니다.'
re.findall('\d+.\d+%', data)
['29.2%']
‘\d+.\d+%’라는 표현식은 ‘숫자.숫자%’의 형태를 나타내는 정규 표현식이며, re 모듈의 findall() 함수를 통해 텍스트에서 해당 표현식의 글자를 추출할 수 있다. 이제 정규 표현식의 종류에는 어떠한 것들이 있는지 알아보도록 하자.
9.2.2. 메타문자#
프로그래밍에서 메타 문자(Meta Characters)란 문자가 가진 원래의 의미가 아닌 특별한 용도로 사용되는 문자를 말한다. 정규 표현식에서 사용되는 메타 문자는 다음과 같다.
. ^ $ * + ? { } [ ] \ | ( )
정규 표현식에 메타 문자를 사용하면 특별한 기능을 갖는다.
9.2.2.1. 문자 클래스([ ])#
정규 표현식에서 대괄호([ ])는 대괄호 안에 포함된 문자들 중 하나와 매치를 뜻한다. 예를 들어 ‘apple’, ‘blueberry’, ‘coconut’이 정규표현식이 [ae]와 어떻게 매치되는지 살펴보자.
‘apple’에는 정규표현식 내의 a와 e가 모두 존재하므로 매치된다.
‘blueberry’에는 e가 존재하므로 매치된다.
‘coconut’에는 a와 e 중 어느 문자도 포함하고 있지 않으므로 매치되지 않는다.
만일 [ ] 안의 두 문자 사이에 하이픈(-)을 입력하면 두 문자 사이의 범위를 의미한다. 즉 [a-e]라는 정규 표현식은 [abcde]와 동일하며, [0-5]는 [012345]와 동일하다. 흔히 [a-z]는 알파벳 소문자를, [A-Z]는 알파벳 대문자를, [a-zA-Z]는 모든 알파벳을, [0-9]는 모든 숫자를 뜻한다. 또한 [ ]안의 ^는 반대를 뜻한다. 즉 [^0-9]는 숫자를 제외한 문자만 매치를, [^abc]는 a,b,c를 제외한 모든 문자와 매치를 뜻한다.
자주 사용하는 문자 클래스의 경우 별도의 표기법이 존재하여 훨씬 간단하게 표현할 수 있다.
문자 클래스 |
설명 |
|---|---|
\d |
숫자와 매치, [0-9]와 동일한 표현식 |
\D |
숫자가 아닌 것 매치, [^0-9]와 동일한 표현식 |
\s |
whitespace(공백) 문자와 매치, [ \t\n\r\f\v]와 동일한 표현식 |
\S |
whitespace 문자가 아닌 것과 매치, [^\t\n\r\f\v]와 동일한 표현식 |
\w |
문자+숫자(alphanumeric)와 매치, [a-zA-Z0-9]와 동일한 표현식 |
\W |
문자+숫자(alphanumeric)가 아닌 문자와 매치, [^a-zA-Z0-9]와 동일한 표현식 |
Table 9.2에서 알 수 있듯이 대문자로 표현된 문자 클래스는 소문자로 표현된 것의 반대를 의미한다.
9.2.2.2. 모든 문자(.)#
Dot(.) 메타 문자는 줄바꿈 문자인 \n을 제외한 모든 문자와 매치되며, Dot 하나당 임의의 한 문자를 나타낸다. 정규 표현식 a.e는 ‘a+모든문자+e’의 형태다. 즉 a와 e 문자 사이에는 어떤 문자가 들어가도 모두 매치가 된다. ‘abe’, ‘ace’, ‘abate’, ‘ae’의 경우 정규식 a.e와 어떻게 매치되는지 살펴보자.
‘abe’: a와 e 사이에 b라는 문자가 있으므로 정규식과 매치된다.
‘ace’: a와 e 사이에 c라는 문자가 있으므로 정규식과 매치된다.
‘abate’: a와 e 사이에 문자가 하나가 아닌 여러개가 있으므로 매치되지 않는다.
‘ae’: a와 e 사이에 문자가 없으므로 매치되지 않는다.
만일 정규식이 a[.]c의 형태일 경우는 ‘a.c’를 의미한다. 즉 a와 c사이의 dot(.)은 모든 문자를 의미하는 것이 아닌 문자 그대로인 .를 의미한다.
9.2.2.3. 반복문#
정규 표현식에는 반복을 의미하는 여러 메타문자가 존재한다. 먼저 *의 경우 * 바로 앞에 있는 문자가 0부터 무한대로 반복될 수 있다는 의미다. ca*t 이라는 정규식은 c 다음의 a가 0부터 무한대로 반복되고 t로 끝이난다는 의미로, ‘ct’, ‘cat’, ‘caat’, ‘caaaat’ 모두 정규식과 매치된다.
반면 메타문자 +는 최소 1번 이상 반복될 때 사용된다. ca+t 라는 정규식은 c 다음의 a가 1번 이상 반복된 후 t로 끝남을 의미하며, 위 예제에서 ct는 a가 없으므로 매치되지 않는다.
메타문자 { }를 사용하면 반복 횟수를 고정할 수 있다. 즉 {m, n}은 반복 횟수가 m부터 n까지 고정된다. m 혹은 n은 생략할 수도 있으며, {3, }의 경우 반복 횟수가 3 이상, {, 3}의 경우 반복 횟수가 3 이하를 의미한다.
메타문자 ?는 {0, 1}과 동일하다. 즉 ? 앞의 문자가 있어도 되고 없어도 된다는 의미다.
9.2.2.4. 기타 메타문자#
이 외에도 정규 표현식에는 다양한 메타문자가 존재한다.
|: or과 동일한 의미다. 즉expr1 | expr2라는 정규식은 expr1 혹은 expr2 라는 의미로써, 둘 중 하나의 형태만 만족해도 매치가 된다.^: 문자열의 맨 처음과 일치함을 의미한다. 즉^a정규식은 a로 시작하는 단어와 매치가 된다.$:^와 반대의 의미로써, 문자열의 끝과 매치함을 의미한다. 즉,a$는 a로 끝나는 단어와 매치가 된다.\: 메타문자의 성질을 없앨때 붙인다. 즉^이나$문자를 메타문자가 아닌 문자 그 자체로 매치하고 싶은 경우\^,\$의 형태로 사용한다.(): 괄호안의 문자열을 하나로 묶어 취급한다.
9.2.3. 정규식을 이용한 문자열 검색#
대략적인 정규 표현식을 익혔다면, 실제 예제를 통해 문자열을 검색하는 법을 알아보자. 파이썬에서는 re(regular expression) 모듈을 통해 정규 표현식을 사용할 수 있다. 정규 표현식과 관련된 메서드는 다음과 같다.
match(): 시작부분부터 일치하는 패턴을 찾는다.search(): 첫 번째 일치하는 패턴을 찾는다.findall(): 일치하는 모든 패턴을 찾는다.finditer():findall()과 동일하지만 그 결과로 반복 가능한 객체를 반환한다.
간단한 실습을 해보도록 하자.
9.2.3.1. match()#
import re
p = re.compile('[a-z]+')
type(p)
re.Pattern
파이썬에서는 re 모듈을 통해 정규 표현식을 사용할 수 있으며, re.compile()을 통해 정규 표현식을 컴파일하여 변수에 저장한 후 사용할 수 있다. [a-z]+는 알파벳 소문자가 1부터 여러개까지를 의미하는 표현식이다.
m = p.match('python')
print(m)
<re.Match object; span=(0, 6), match='python'>
match() 함수를 통해 처음부터 정규 표현식과 일치하는 패턴을 찾을 수 있다. python이라는 단어는 알파벳이 여러개가 있는 경우이므로 match 객체를 반환한다.
m.group()
'python'
match 객체 뒤에 group()을 입력하면 매치된 텍스트만 출력할 수 있다.
m = p.match('Use python')
print(m)
None
‘Use python 이라는 문자열은 맨 처음의 문자 ‘U’가 대문자로써, 소문자를 의미하는 정규 표현식 [a-z]+와는 매치되지 않아 None을 반환한다.
m = p.match('PYTHON')
print(m)
None
PYTHON이라는 단어는 대문자이므로 이 역시[a-z]+와는 매치되지 않는다. 이 경우 대문자에 해당하는 [A-Z]+ 표현식을 사용해야 매치가 된다.
p = re.compile('[가-힣]+')
m = p.match('파이썬')
print(m)
<re.Match object; span=(0, 3), match='파이썬'>
한글의 경우 알파벳이 아니므로 모든 한글을 뜻하는 [가-힣]+ 표현식을 사용하면 매치가 된다.
9.2.3.2. search()#
search() 함수는 첫 번째 일치하는 패턴을 찾는다.
p = re.compile('[a-z]+')
m = p.search('python')
print(m)
<re.Match object; span=(0, 6), match='python'>
‘python’이라는 문자에 search 메서드를 수행하면 match 메서드를 수행한 것과 결과가 동일하다.
m = p.search('Use python')
print(m)
<re.Match object; span=(1, 3), match='se'>
‘Use python’ 문자의 경우 첫번째 문자인 ‘U’는 대문자라 매치가 되지 않지만, 그 이후의 문자열 ‘se’는 소문자로 구성되어 있기에 매치가 된다. 이처럼 search()는 문자열의 처음부터 검색하는 것이 아니라 문자열 전체를 검색하며, 첫 번째로 일치하는 패턴을 찾기에 띄어쓰기 이후의 ‘python’은 매치되지 않는다.
9.2.3.3. findall()#
findall()은 하나가 아닌 일치하는 모든 패턴을 찾는다.
p = re.compile('[a-zA-Z]+')
m = p.findall('Life is too short, You need Python.')
print(m)
['Life', 'is', 'too', 'short', 'You', 'need', 'Python']
이번에는 대소문자 모든 알파벳을 뜻하는 [a-zA-Z]+ 표현식을 입력하였다. 그 후 ‘Life is too short, You need Python.’라는 문자에 finall() 메서드를 적용하면 정규 표현식과 매치되는 모든 단어를 리스트 형태도 반환한다.
9.2.3.4. finditer()#
마지막으로 findall()과 비슷한 finditer() 함수의 결과를 살펴보자.
p = re.compile('[a-zA-Z]+')
m = p.finditer('Life is too short, You need Python.')
print(m)
<callable_iterator object at 0x000001C26ED74BB0>
결과를 살펴보면 반복 가능한 객체(iterator object)를 반환한다. 이는 for문을 통해 출력할 수 있다.
for i in m:
print(i)
<re.Match object; span=(0, 4), match='Life'>
<re.Match object; span=(5, 7), match='is'>
<re.Match object; span=(8, 11), match='too'>
<re.Match object; span=(12, 17), match='short'>
<re.Match object; span=(19, 22), match='You'>
<re.Match object; span=(23, 27), match='need'>
<re.Match object; span=(28, 34), match='Python'>
9.2.4. 정규 표현식 연습해보기#
위에서 배운 것들을 토대로 실제 크롤링 결과물 중 정규 표현식을 사용해 원하는 부분만 찾는 연습을 해보도록 하자.
num = """r\n\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t15\r\n\t\t\t\t\t\t\t\t23\r\n\t\t\t\t\t\t\t\t29\r\n\t\t\t\t\t\t\t\t34\r\n\t\t\t\t\t\t\t\t40\r\n\t\t\t\t\t\t\t\t44\r\n\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t"""
위의 HTML 결과물에서 숫자에 해당하는 부분만 추츨해보도록 하자.
import re
p = re.compile('[0-9]+')
m = p.findall(num)
print(m)
['15', '23', '29', '34', '40', '44']
\n, \t와 같은 문자를 없애는 방법으로 클렌징을 할 수도 있지만, 숫자를 의미하는 ‘[0-9]+’ 정규 표현식을 사용하면 훨씬 간단하게 추출할 수 있다.
dt = '> 오늘의 날짜는 2022.12.31 입니다.'
이번에는 위의 문장에서 날짜에 해당하는 ‘2022.12.31’ 혹은 ‘20221231’ 만 추출해보도록 하자.
p = re.compile('[0-9]+.[0-9]+.[0-9]+')
p.findall(dt)
['2022.12.31']
정규 표현식 ‘[0-9]+.[0-9]+.[0-9]+’은 [숫자.숫자.숫자] 형태를 의미하며, 이를 통해 ‘2022.12.31’을 추출한다.
p = re.compile('[0-9]+')
m = p.findall(dt)
print(m)
['2022', '12', '31']
정규 표현식에 [0-9]+을 입력할 경우 숫자가 개별로 추출되므로, 추가적인 작업을 통해 ‘20221231’ 형태로 만들어주면 된다.
''.join(m)
'20221231'
join() 함수는 '구분자'.join(리스트) 형태이므로, 구분자에 ‘’를 입력하면 리스트 내의 모든 문자를 공백없이 합쳐서 반환한다.
Note
아래의 웹사이트에서 정규 표현식을 연습하고 테스트할 수 있다. 크롤링 후 내가 선택하고자 하는 문자를 한 번에 정규 표현식을 이용해 추출하는 것은 초보자 단계에서는 쉬운일이 아니므로, 아래 웹사이트에서 텍스트를 입력하고 이를 추출하는 정규 표현식을 알아낸 후, 이를 파이썬에 적용하는 것이 훨씬 효율성이 높다.