10. 국내 주식 데이터 수집#
이번 장에서는 극내 주식 데이터 중 주식티커와 섹터별 구성종목 및 퀀트 투자를 위한 핵심 데이터인 수정주가, 재무제표, 가치지표를 크롤링하는 방법을 알아보겠다.
10.1. 최근 영업일 기준 데이터 받기#
POST 방식으로 금융 데이터를 제공하는 일부 사이트에서는 쿼리 항목에 특정 날짜를 입력하면(예:20221230) 해당일의 데이터를 다운로드 할 수 있으며, 최근 영업일 날짜를 입력하면 가장 최근의 데이터를 받을 수 있다. 따라서 최근 영업일에 해당하는 항목을 매번 수기로 입력하기 보다는 자동으로 반영되게 할 필요가 있다.
네이버 금융의 [국내증시 → 증시자금동향]에는 이전 2영업일에 해당하는 날짜가 있으며, 자동으로 날짜가 업데이트된다. 따라서 해당 부분을 크롤링 한후 날짜에 해당하는 쿼리 항목에 사용하면 된다.
https://finance.naver.com/sise/sise_deposit.nhn
Fig. 10.1 최근 영업일 부분#
개발자도구 화면을 이용해 해당 데이터가 있는 부분을 확인해보면 [클래스가 subtop_sise_graph2인 div 태그 → 클래스가 subtop_chart_note인 ul 태그 → li 태그 → 클래스가 tah인 span 태그]에 위치해 있다는 걸 알 수 있다. 이를 이용해 해당 데이터를 크롤링한다.
import requests as rq
from bs4 import BeautifulSoup
url = 'https://finance.naver.com/sise/sise_deposit.nhn'
data = rq.get(url)
data_html = BeautifulSoup(data.content)
parse_day = data_html.select_one(
'div.subtop_sise_graph2 > ul.subtop_chart_note > li > span.tah').text
print(parse_day)
| 2022.08.03
페이지 주소를 입력한다.
get()함수를 통해 해당 페이지 내용을 받아온다.BeautifulSoup()함수를 이용해 해당 페이지의 HTML 내용을 BeautifulSoup 객체로 만든다.select_one()메서드를 통해 해당 태그의 데이터를 추출하며,text메서드를 이용해 텍스트 데이터만을 추출한다.
위 과정을 통해 | yyyy.mm.dd 형식의 데이터가 선택된다. 이 중 숫자 부분만을 뽑아 yyyymmdd 형태로 만들어주도록 한다.
import re
biz_day = re.findall('[0-9]+', parse_day)
biz_day = ''.join(biz_day)
print(biz_day)
20220803
findall()메서드 내에 정규 표현식을 이용해 숫자에 해당하는 부분만을 추출한다. ‘[0-9]+’ 는 모든 숫자를 의미하는 표현식이다.join()함수를 통해 숫자를 합쳐준다.
이를 통해 우리가 원하는 yyyymmdd 형태의 날짜가 만들어졌다. 해당 데이터를 최근 영업일이 필요한 곳에 사용하면 된다.
10.2. 한국거래소의 업종분류 현황 및 개별지표 크롤링#
주식 관련 데이터를 구하기 위해 가장 먼저 해야하는 일은 어떠한 종목들이 상장되어 있는가에 대한 정보를 구하는 것이다. 한국거래소에서 제공하는 업종분류 현황과 개별종목 지표 데이터를 이용하면 매우 간단하게 해당 정보를 수집할 수 있다.
KRX 정보데이터시스템 http://data.krx.co.kr/ 에서 [기본통계 → 주식 → 세부안내] 부분
[12025] 업종분류 현황: http://data.krx.co.kr/contents/MDC/MDI/mdiLoader/index.cmd?menuId=MDC0201020506
[12021] 개별종목: http://data.krx.co.kr/contents/MDC/MDI/mdiLoader/index.cmd?menuId=MDC0201020502
해당 데이터들을 크롤링이 아닌 [Excel] 버튼을 클릭해 엑셀 파일로 받을 수도 있다. 그러나 매번 엑셀 파일을 다운로드하고 이를 불러오는 작업은 상당히 비효율적이며, 크롤링을 이용한다면 해당 데이터를 파이썬에서 바로 불러올 수 있다.
10.2.1. 업종분류 현황 크롤링#
먼저 업종분류 현황에 해당하는 페이지에 접속하여 F12를 눌러 개발자도구 화면을 열고 [다운로드] 버튼을 클릭한 후 [CSV]를 누른다. 개발자도구 화면의 [Network] 탭에는 Fig. 10.2와 같이 generate.cmd와 download.cmd 두 가지 항목이 생긴다.
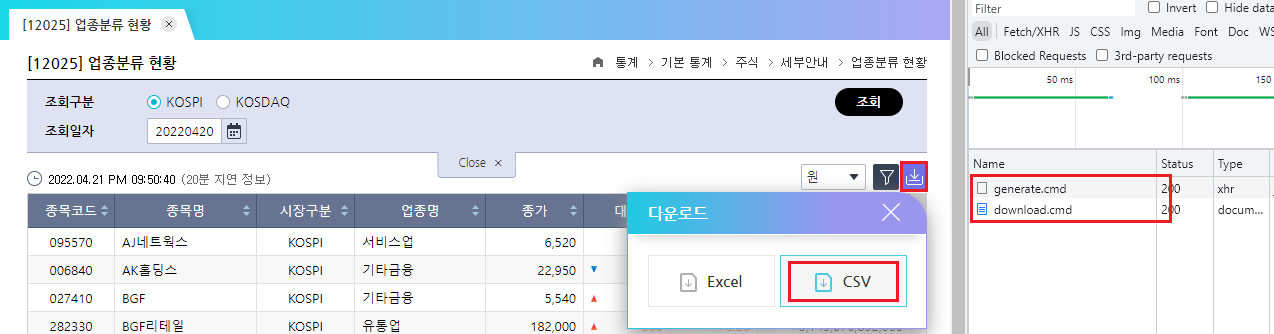
Fig. 10.2 CSV 다운로드 시 개발자도구 화면#
거래소에서 엑셀 혹은 CSV 데이터를 받는 과정은 다음과 같다.
http://data.krx.co.kr/comm/fileDn/download_excel/download.cmd 에 원하는 항목을 쿼리로 발송하면 해당 쿼리에 해당하는 OTP(generate.cmd)를 받는다.
부여받은 OTP를 http://data.krx.co.kr/ 에 제출하면 이에 해당하는 데이터(download.cmd)를 다운로드한다.
먼저 1번 단계를 살펴보자. [Headers] 탭의 ‘General’ 항목 중 ‘Request URL’ 부분이 원하는 항목을 제출할 주소다. [Payload] 탭의 Form Data에는 우리가 원하는 항목들이 적혀 있다. 이를 통해 POST 방식으로 데이터를 요청하면 OTP를 받음을 알 수 있다.
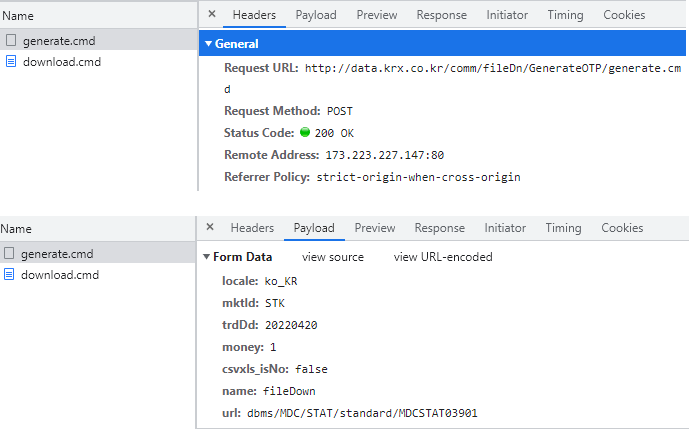
Fig. 10.3 OTP 생성 부분#
다음으로 2번 단계를 살펴보자. ‘General’ 항목의 ‘Request URL’은 OTP를 제출할 주소다. ‘Form Data’의 OTP는 1번 단계를 통해 부여받은 OTP에 해당한다. 이 역시 POST 방식으로 데이터를 요청하며 이를 통해 CSV 파일을 받아온다.
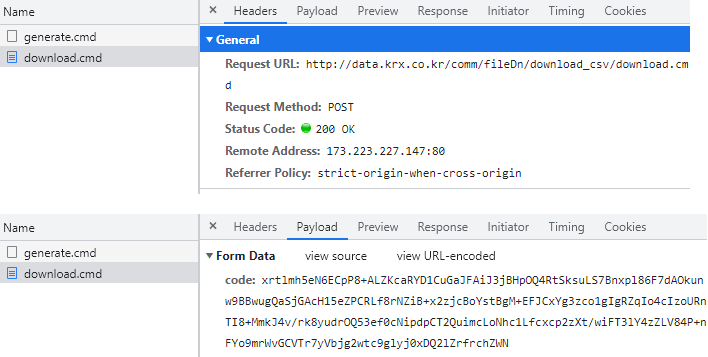
Fig. 10.4 OTP 제출 부분#
위 과정 중 OTP를 받아오는 과정을 코드로 나타내면 다음과 같다
import requests as rq
from io import BytesIO
import pandas as pd
gen_otp_url = 'http://data.krx.co.kr/comm/fileDn/GenerateOTP/generate.cmd'
gen_otp_stk = {
'mktId': 'STK',
'trdDd': biz_day,
'money': '1',
'csvxls_isNo': 'false',
'name': 'fileDown',
'url': 'dbms/MDC/STAT/standard/MDCSTAT03901'
}
headers = {'Referer': 'http://data.krx.co.kr/contents/MDC/MDI/mdiLoader'}
otp_stk = rq.post(gen_otp_url, gen_otp_stk, headers=headers).text
print(otp_stk)
SkqvmXXK0SrilAazghYQaJj7CaiJA9Ue1WbAAO7jNzsRtSksuLS7Bnxpl86F7dAOkunw9BBwugQaSjGAcH15eSN3vF4ZiabecDu8sGdUJ+0tBgM+EFJCxYg3zco1gIgRZqIo4cIzoURnTI8+MmkJ4m8vFLhSKmM794gFu+ThsO31lY4woqehX8j6OlXFDcfHdV4NbYo4+D2Rwcfj24VnU3Zpq3ik/Dyw3FdyOXhJkBI=
gen_otp_url 에 원하는 항목을 제출할 URL을 입력한다.
개발자도구 화면에 있는 쿼리 내용들을 딕셔너리 형태로 입력한다. 이 중 mktId의 ‘STK’는 코스피에 해당하며, 코스닥 데이터를 받고자 할 경우 ‘KSQ’를 입력하면 된다.
영업일을 뜻하는 trdDd에는 위에서 구한 최근 영업일 데이터를 입력한다.
헤더 부분에 리퍼러(Referer)를 추가한다. 리퍼러란 링크를 통해서 각각의 웹사이트로 방문할 때 남는 흔적이다. 거래소 데이터를 다운로드하는 과정을 살펴보면 첫 번째 URL에서 OTP를 부여받고, 이를 다시 두번째 URL에 제출했다. 그런데 이러한 과정의 흔적이 없이 OTP를 바로 두번째 URL에 제출하면 서버는 이를 로봇으로 인식해 데이터를 주지 않는다. 따라서 헤더 부분에 우리가 거쳐온 과정을 흔적으로 남겨야 데이터를 받을 수 있다. 이러한 리퍼러 주소는 개발자도구 화면에서도 확인할 수 있다(Fig. 10.5).
post()함수를 통해 해당 URL에 쿼리를 전송하면 이에 해당하는 데이터를 받으며, 이 중 텍스트에 해당하는 내용만 불러온다.
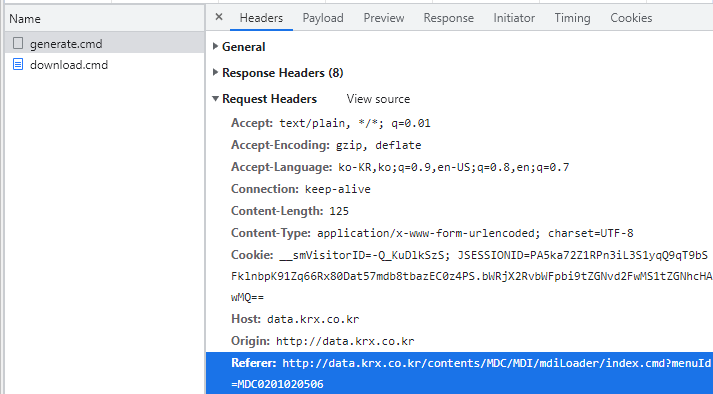
Fig. 10.5 리퍼러 주소의 확인#
위의 과정을 거쳐 생성된 OTP를 제출하면, 우리가 원하는 데이터를 다운로드할 수 있다.
down_url = 'http://data.krx.co.kr/comm/fileDn/download_csv/download.cmd'
down_sector_stk = rq.post(down_url, {'code': otp_stk}, headers=headers)
sector_stk = pd.read_csv(BytesIO(down_sector_stk.content), encoding='EUC-KR')
sector_stk.head()
| 종목코드 | 종목명 | 시장구분 | 업종명 | 종가 | 대비 | 등락률 | 시가총액 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 095570 | AJ네트웍스 | KOSPI | 서비스업 | 7970 | -10 | -0.13 | 373173691150 |
| 1 | 006840 | AK홀딩스 | KOSPI | 기타금융 | 16450 | 300 | 1.86 | 217922378450 |
| 2 | 027410 | BGF | KOSPI | 기타금융 | 4215 | 30 | 0.72 | 403446274065 |
| 3 | 282330 | BGF리테일 | KOSPI | 유통업 | 184500 | 1000 | 0.54 | 3188880657000 |
| 4 | 138930 | BNK금융지주 | KOSPI | 기타금융 | 6640 | 0 | 0.00 | 2164210033440 |
OTP를 제출할 URL을 down_url에 입력한다.
post()함수를 통해 위에서 부여받은 OTP 코드를 해당 URL에 제출한다.받은 데이터의 content 부분을
BytesIO()를 이용해 바이너리스트림 형태로 만든 후,read_csv()함수를 통해 데이터를 읽어온다. 해당 데이터는 EUC-KR 형태로 인코딩 되어 있으므로 이를 선언해준다.
위 과정을 통해 sector_stk 변수에는 코스피 종목의 산업별 현황 데이터가 저장되었다. 코스닥 시장의 데이터도 동일한 과정을 통해 다운로드 받도록 한다.
gen_otp_ksq = {
'mktId': 'KSQ', # 코스닥 입력
'trdDd': biz_day,
'money': '1',
'csvxls_isNo': 'false',
'name': 'fileDown',
'url': 'dbms/MDC/STAT/standard/MDCSTAT03901'
}
otp_ksq = rq.post(gen_otp_url, gen_otp_ksq, headers=headers).text
down_sector_ksq = rq.post(down_url, {'code': otp_ksq}, headers=headers)
sector_ksq = pd.read_csv(BytesIO(down_sector_ksq.content), encoding='EUC-KR')
sector_ksq.head()
| 종목코드 | 종목명 | 시장구분 | 업종명 | 종가 | 대비 | 등락률 | 시가총액 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 060310 | 3S | KOSDAQ | 기계·장비 | 2995 | -5 | -0.17 | 138583181435 |
| 1 | 054620 | APS홀딩스 | KOSDAQ | 금융 | 11450 | 700 | 6.51 | 233513830450 |
| 2 | 265520 | AP시스템 | KOSDAQ | 반도체 | 17600 | 100 | 0.57 | 268953009600 |
| 3 | 211270 | AP위성 | KOSDAQ | 통신장비 | 12250 | -150 | -1.21 | 184758224000 |
| 4 | 032790 | BNGT | KOSDAQ | 정보기기 | 4075 | 0 | 0.00 | 120352455875 |
코스피 데이터와 코스닥 데이터를 하나로 합친다.
krx_sector = pd.concat([sector_stk, sector_ksq]).reset_index(drop=True)
krx_sector['종목명'] = krx_sector['종목명'].str.strip()
krx_sector['기준일'] = biz_day
krx_sector.head()
| 종목코드 | 종목명 | 시장구분 | 업종명 | 종가 | 대비 | 등락률 | 시가총액 | 기준일 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 095570 | AJ네트웍스 | KOSPI | 서비스업 | 7970 | -10 | -0.13 | 373173691150 | 20220803 |
| 1 | 006840 | AK홀딩스 | KOSPI | 기타금융 | 16450 | 300 | 1.86 | 217922378450 | 20220803 |
| 2 | 027410 | BGF | KOSPI | 기타금융 | 4215 | 30 | 0.72 | 403446274065 | 20220803 |
| 3 | 282330 | BGF리테일 | KOSPI | 유통업 | 184500 | 1000 | 0.54 | 3188880657000 | 20220803 |
| 4 | 138930 | BNK금융지주 | KOSPI | 기타금융 | 6640 | 0 | 0.00 | 2164210033440 | 20220803 |
concat()함수를 통해 두 데이터를 합쳐주며,reset_index()메서드를 통해 인덱스를 리셋시킨다. 또한drop=True를 통해 인덱스로 셋팅한 열을 삭제한다.종목명에 공백에 있는 경우가 있으므로
strip()메서드를 이용해 이를 제거해준다.데이터의 기준일에 해당하는 [기준일] 열을 추가한다.
10.2.2. 개별종목 지표 크롤링#
개별종목 데이터를 크롤링하는 방법은 위와 매우 유사하며, 요청하는 쿼리 값에만 차이가 있다. 개발자도구 화면을 열고 [CSV] 버튼을 클릭해 어떠한 쿼리를 요청하는지 확인해보자.
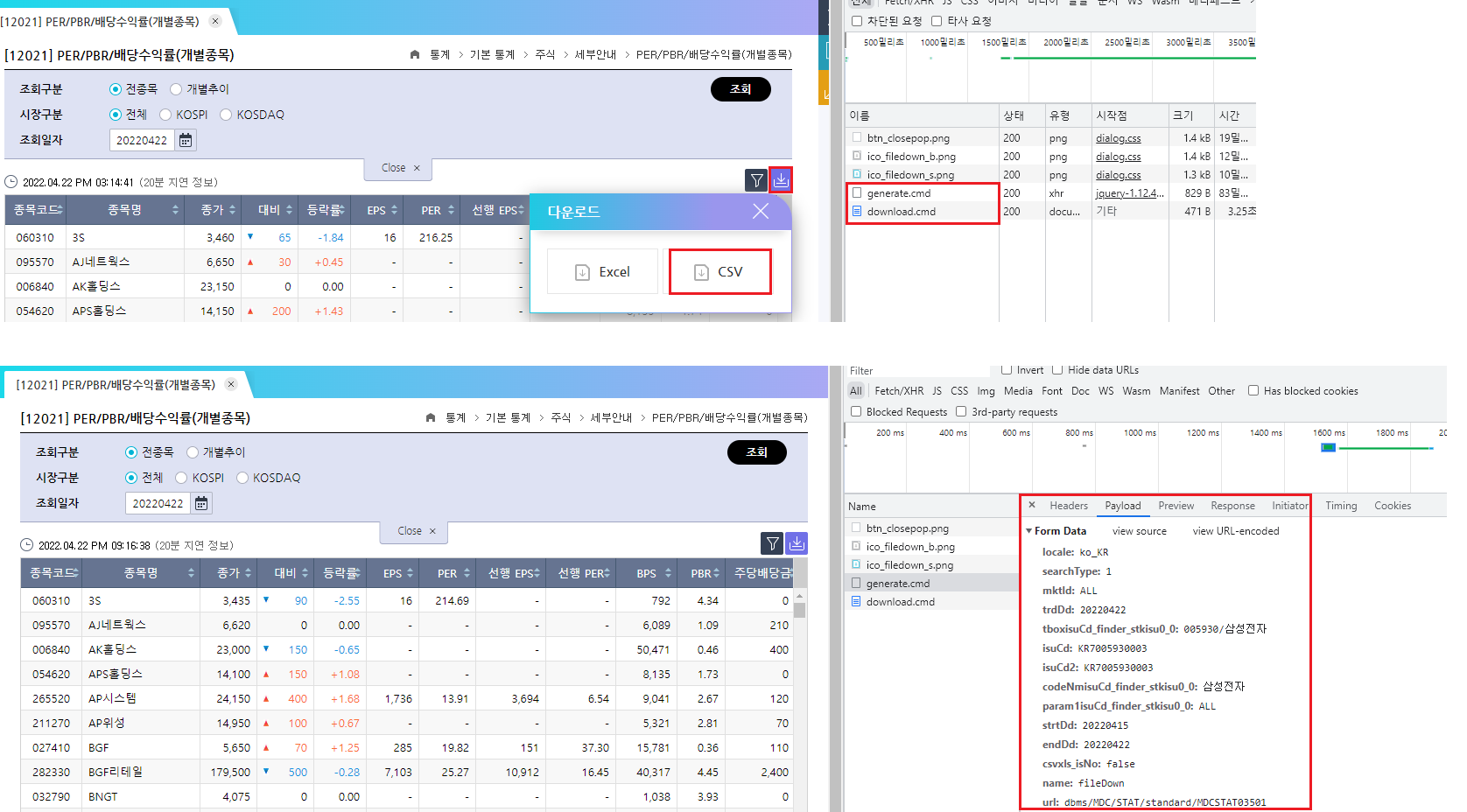
Fig. 10.6 개별지표 OTP 생성 부분#
OTP를 생성하는 부분인 [generate.cmd]를 확인해보면 [Payload] 탭의 ‘tboxisuCd_finder_stkisu0_6’, ‘isu_Cd’, ‘isu_Cd2’ 등의 항목은 조회 구분의 개별추이 탭에 해당하는 부분이므로 우리가 원하는 전체 데이터를 받을 때는 필요하지 않은 요청값다. 이를 제외한 요청값을 산업별 현황 예제에 적용하면 해당 데이터 역시 손쉽게 다운로드할 수 있다.
import requests as rq
from io import BytesIO
import pandas as pd
gen_otp_url = 'http://data.krx.co.kr/comm/fileDn/GenerateOTP/generate.cmd'
gen_otp_data = {
'searchType': '1',
'mktId': 'ALL',
'trdDd': biz_day,
'csvxls_isNo': 'false',
'name': 'fileDown',
'url': 'dbms/MDC/STAT/standard/MDCSTAT03501'
}
headers = {'Referer': 'http://data.krx.co.kr/contents/MDC/MDI/mdiLoader'}
otp = rq.post(gen_otp_url, gen_otp_data, headers=headers).text
down_url = 'http://data.krx.co.kr/comm/fileDn/download_csv/download.cmd'
krx_ind = rq.post(down_url, {'code': otp}, headers=headers)
krx_ind = pd.read_csv(BytesIO(krx_ind.content), encoding='EUC-KR')
krx_ind['종목명'] = krx_ind['종목명'].str.strip()
krx_ind['기준일'] = biz_day
krx_ind.head()
| 종목코드 | 종목명 | 종가 | 대비 | 등락률 | EPS | PER | 선행 EPS | 선행 PER | BPS | PBR | 주당배당금 | 배당수익률 | 기준일 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 060310 | 3S | 2995 | -5 | -0.17 | 16.0 | 187.19 | NaN | NaN | 792.0 | 3.78 | 0 | 0.00 | 20220803 |
| 1 | 095570 | AJ네트웍스 | 7970 | -10 | -0.13 | 1707.0 | 4.67 | 988.0 | 8.07 | 8075.0 | 0.99 | 270 | 3.39 | 20220803 |
| 2 | 006840 | AK홀딩스 | 16450 | 300 | 1.86 | NaN | NaN | NaN | NaN | 45961.0 | 0.36 | 200 | 1.22 | 20220803 |
| 3 | 054620 | APS홀딩스 | 11450 | 700 | 6.51 | 1179.0 | 9.71 | NaN | NaN | 10088.0 | 1.14 | 100 | 0.87 | 20220803 |
| 4 | 265520 | AP시스템 | 17600 | 100 | 0.57 | 3932.0 | 4.48 | 3562.0 | 4.94 | 12713.0 | 1.38 | 240 | 1.36 | 20220803 |
10.2.3. 데이터 정리하기#
먼저 두 데이터에 공통으로 존재하지 않는 종목, 즉 하나의 데이터에만 존재하는 종목을 살펴보도록 하자.
diff = list(set(krx_sector['종목명']).symmetric_difference(set(krx_ind['종목명'])))
print(diff)
['글로벌에스엠', '한국패러랠', '이지스밸류리츠', 'NH올원리츠', 'JTC', '맵스리얼티1', 'SK리츠', '엑세스바이오', '엘브이엠씨홀딩스', '에이리츠', '컬러레이', 'ESR켄달스퀘어리츠', '디앤디플랫폼리츠', 'SBI핀테크솔루션즈', '케이탑리츠', '크리스탈신소재', '코오롱티슈진', '로스웰', '모두투어리츠', '미투젠', '코람코더원리츠', '롯데리츠', '신한알파리츠', '네오이뮨텍', '프레스티지바이오파마', '골든센츄리', '미래에셋글로벌리츠', '이리츠코크렙', '제이알글로벌리츠', '신한서부티엔디리츠', 'NH프라임리츠', '미래에셋맵스리츠', '베트남개발1', '코람코에너지리츠', '윙입푸드', '마스턴프리미어리츠', '애머릿지', '오가닉티코스메틱', '한국ANKOR유전', '잉글우드랩', '바다로19호', '이스트아시아홀딩스', '씨케이에이치', '맥쿼리인프라', 'GRT', '헝셩그룹', '소마젠', '이지스레지던스리츠']
두 데이터의 종목명 열을 세트 형태로 변경한 후 symmetric_difference() 메서드를 통해 하나의 데이터에만 있는 종목을 살펴보면 위와 같다. 해당 종목들은 선박펀드, 광물펀드, 해외종목 등 일반적이지 않은 종목들이다. 다음으로 두 데이터를 합쳐준다.
kor_ticker = pd.merge(krx_sector,
krx_ind,
on=krx_sector.columns.intersection(
krx_ind.columns).tolist(),
how='outer')
kor_ticker.head()
| 종목코드 | 종목명 | 시장구분 | 업종명 | 종가 | 대비 | 등락률 | 시가총액 | 기준일 | EPS | PER | 선행 EPS | 선행 PER | BPS | PBR | 주당배당금 | 배당수익률 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 095570 | AJ네트웍스 | KOSPI | 서비스업 | 7970 | -10 | -0.13 | 373173691150 | 20220803 | 1707.0 | 4.67 | 988.0 | 8.07 | 8075.0 | 0.99 | 270.0 | 3.39 |
| 1 | 006840 | AK홀딩스 | KOSPI | 기타금융 | 16450 | 300 | 1.86 | 217922378450 | 20220803 | NaN | NaN | NaN | NaN | 45961.0 | 0.36 | 200.0 | 1.22 |
| 2 | 027410 | BGF | KOSPI | 기타금융 | 4215 | 30 | 0.72 | 403446274065 | 20220803 | 684.0 | 6.16 | 115.0 | 36.68 | 16393.0 | 0.26 | 110.0 | 2.61 |
| 3 | 282330 | BGF리테일 | KOSPI | 유통업 | 184500 | 1000 | 0.54 | 3188880657000 | 20220803 | 8547.0 | 21.59 | 12336.0 | 14.96 | 46849.0 | 3.94 | 3000.0 | 1.63 |
| 4 | 138930 | BNK금융지주 | KOSPI | 기타금융 | 6640 | 0 | 0.00 | 2164210033440 | 20220803 | 2341.0 | 2.84 | 2778.0 | 2.39 | 28745.0 | 0.23 | 560.0 | 8.43 |
merge() 함수는 on 조건을 기준으로 두 데이터를 하나로 합치며, intersection() 메서드를 이용해 공통으로 존재하는 [종목코드, 종목명, 종가, 대비, 등락률] 열을 기준으로 입력해준다. 또한 방법(how)에는 outer를 입력한다.
마지막으로 일반적인 종목과 스팩, 우선주, 리츠, 기타 주식을 구분해주도록 한다.
Note
스팩(SPAC)이란 Special Purpose Acquisition Company의 약자로 기업인수를 목적으로 하는 페이퍼컴퍼니를 뜻한다. 대부분 증권사 주관으로 설립되며, 스팩이 먼저 투자자들의 자금을 모아 주식 시장에 상장이 되고 나면, 그 이후에 괜찮은 비상장기업을 찾아 합병하는 방식으로 최종 기업 인수가 이루어진다.
print(kor_ticker[kor_ticker['종목명'].str.contains('스팩|제[0-9]+호')]['종목명'].values)
['엔에이치스팩19호' 'DB금융스팩10호' 'DB금융스팩8호' 'DB금융스팩9호' 'IBKS제12호스팩' 'IBKS제13호스팩'
'IBKS제16호스팩' 'IBKS제17호스팩' 'IBKS제18호스팩' 'SK5호스팩' 'SK6호스팩' '교보10호스팩'
'교보11호스팩' '교보12호스팩' '교보9호스팩' '대신밸런스제10호스팩' '대신밸런스제11호스팩' '대신밸런스제12호스팩'
'미래에셋대우스팩 5호' '미래에셋대우스팩3호' '미래에셋비전스팩1호' '삼성머스트스팩5호' '삼성스팩4호' '삼성스팩6호'
'상상인제3호스팩' '신영스팩6호' '신영스팩7호' '신한제10호스팩' '신한제6호스팩' '신한제7호스팩' '신한제8호스팩'
'신한제9호스팩' '에스케이증권7호스팩' '에이치엠씨제4호스팩' '에이치엠씨제5호스팩' '엔에이치스팩20호' '엔에이치스팩22호'
'엔에이치스팩23호' '유안타제7호스팩' '유안타제8호스팩' '유진스팩6호' '유진스팩7호' '유진스팩8호' '이베스트스팩5호'
'케이비제20호스팩' '케이비제21호스팩' '케이프이에스제4호' '키움제6호스팩' '하나금융14호스팩' '하나금융15호스팩'
'하나금융16호스팩' '하나금융19호스팩' '하나금융20호스팩' '하나금융21호스팩' '하나금융22호스팩' '하나머스트7호스팩'
'하이제6호스팩' '하이제7호스팩' '한국제10호스팩' '한화플러스제2호스팩']
print(kor_ticker[kor_ticker['종목코드'].str[-1:] != '0']['종목명'].values)
['BYC우' 'CJ4우(전환)' 'CJ씨푸드1우' 'CJ우' 'CJ제일제당 우' 'DB하이텍1우' 'DL우'
'DL이앤씨2우(전환)' 'DL이앤씨우' 'GS우' 'JW중외제약2우B' 'JW중외제약우' 'LG생활건강우' 'LG우'
'LG전자우' 'LG화학우' 'LX하우시스우' 'LX홀딩스1우' 'NH투자증권우' 'NPC우' 'S-Oil우' 'SK네트웍스우'
'SK디스커버리우' 'SK우' 'SK이노베이션우' 'SK증권우' 'SK케미칼우' '계양전기우' '금강공업우' '금호건설우'
'금호석유우' '깨끗한나라우' '남선알미우' '남양유업우' '넥센우' '넥센타이어1우B' '노루페인트우' '노루홀딩스우'
'녹십자홀딩스2우' '대교우B' '대덕1우' '대덕전자1우' '대상우' '대상홀딩스우' '대신증권2우B' '대신증권우'
'대원전선우' '대한제당우' '대한항공우' '덕성우' '동부건설우' '동양2우B' '동양우' '동원시스템즈우' '두산2우B'
'두산우' '두산퓨얼셀1우' '두산퓨얼셀2우B' '롯데지주우' '롯데칠성우' '미래에셋증권2우B' '미래에셋증권우' '부국증권우'
'삼성SDI우' '삼성물산우B' '삼성전기우' '삼성전자우' '삼성중공우' '삼성화재우' '삼양사우' '삼양홀딩스우' '서울식품우'
'성문전자우' '성신양회우' '세방우' '솔루스첨단소재1우' '솔루스첨단소재2우B' '신영증권우' '신풍제약우'
'아모레G3우(전환)' '아모레G우' '아모레퍼시픽우' '유안타증권우' '유유제약1우' '유유제약2우B' '유한양행우'
'유화증권우' '일양약품우' '진흥기업2우B' '진흥기업우B' '코리아써우' '코리아써키트2우B' '코오롱글로벌우' '코오롱우'
'코오롱인더우' '크라운제과우' '크라운해태홀딩스우' '태양금속우' '태영건설우' '티와이홀딩스우' '하이트진로2우B'
'하이트진로홀딩스우' '한국금융지주우' '한양증권우' '한진칼우' '한화3우B' '한화솔루션우' '한화우' '한화투자증권우'
'현대건설우' '현대비앤지스틸우' '현대차2우B' '현대차3우B' '현대차우' '호텔신라우' '흥국화재2우B' '흥국화재우'
'대호특수강우' '루트로닉3우C' '소프트센우' '해성산업1우']
print(kor_ticker[kor_ticker['종목명'].str.endswith('리츠')]['종목명'].values)
['ESR켄달스퀘어리츠' 'NH올원리츠' 'NH프라임리츠' 'SK리츠' '디앤디플랫폼리츠' '롯데리츠' '마스턴프리미어리츠'
'모두투어리츠' '미래에셋글로벌리츠' '미래에셋맵스리츠' '신한서부티엔디리츠' '신한알파리츠' '에이리츠' '이지스레지던스리츠'
'이지스밸류리츠' '제이알글로벌리츠' '케이탑리츠' '코람코더원리츠' '코람코에너지리츠']
스팩 종목은 종목명에 ‘스팩’ 혹은 ‘제n호’ 라는 단어가 들어간다. 따라서
contains()메서드를 통해 종목명에 ‘스팩’이 들어가거나 정규 표현식을 이용해 ‘제n호’라는 문자가 들어간 종목명을 찾는다.국내 종목 중 종목코드 끝이 0이 아닌 종목은 우선주에 해당한다.
리츠 종목은 종목명이 ‘리츠’로 끝난다. 따라서
endswith()메서드를 통해 이러한 종목을 찾는다. (메리츠화재 등의 종목도 중간에 리츠라는 단어가 들어가므로contains()함수를 이용하면 안된다.)
해당 종목들을 구분하여 표기해주도록 한다.
import numpy as np
kor_ticker['종목구분'] = np.where(kor_ticker['종목명'].str.contains('스팩|제[0-9]+호'), '스팩',
np.where(kor_ticker['종목코드'].str[-1:] != '0', '우선주',
np.where(kor_ticker['종목명'].str.endswith('리츠'), '리츠',
np.where(kor_ticker['종목명'].isin(diff), '기타',
'보통주'))))
kor_ticker = kor_ticker.reset_index(drop=True)
kor_ticker.columns = kor_ticker.columns.str.replace(' ', '')
kor_ticker = kor_ticker[['종목코드', '종목명', '시장구분', '종가',
'시가총액', '기준일', 'EPS', '선행EPS', 'BPS', '주당배당금', '종목구분']]
kor_ticker = kor_ticker.replace({np.nan: None})
kor_ticker['기준일'] = pd.to_datetime(kor_ticker['기준일'])
kor_ticker.head()
| 종목코드 | 종목명 | 시장구분 | 종가 | 시가총액 | 기준일 | EPS | 선행EPS | BPS | 주당배당금 | 종목구분 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 095570 | AJ네트웍스 | KOSPI | 7970 | 373173691150 | 2022-08-03 | 1707.0 | 988.0 | 8075.0 | 270.0 | 보통주 |
| 1 | 006840 | AK홀딩스 | KOSPI | 16450 | 217922378450 | 2022-08-03 | None | None | 45961.0 | 200.0 | 보통주 |
| 2 | 027410 | BGF | KOSPI | 4215 | 403446274065 | 2022-08-03 | 684.0 | 115.0 | 16393.0 | 110.0 | 보통주 |
| 3 | 282330 | BGF리테일 | KOSPI | 184500 | 3188880657000 | 2022-08-03 | 8547.0 | 12336.0 | 46849.0 | 3000.0 | 보통주 |
| 4 | 138930 | BNK금융지주 | KOSPI | 6640 | 2164210033440 | 2022-08-03 | 2341.0 | 2778.0 | 28745.0 | 560.0 | 보통주 |
numpy 패키지의
where()함수를 통해 각 조건에 맞는 종목구분을 입력한다. 종목명에 ‘스팩’ 혹은 ‘제n호’가 포함된 종목은 스팩으로, 종목코드 끝이 0이 아닌 종목은 ‘우선주’로, 종목명이 ‘리츠’로 끝나는 종목은 ‘리츠’로, 선박펀드, 광물펀드, 해외종목 등은 ‘기타’로, 나머지 종목들은 ‘보통주’로 구분한다.reset_index()메서드를 통해 인덱스를 초기화 한다.replace()메서드를 통해 열 이름의 공백을 삭제한다.필요한 열만 선택한다.
SQL에는 NaN이 입력되지 않으므로, None으로 변경한다.
기준일을
to_datetime()메서드를 이용해 yyyymmdd에서 yyyy-mm-dd 형태로 변경한다.
이제 해당 정보를 DB에 저장한다. 먼저 MySQL에서 아래의 쿼리를 입력해 데이터베이스(stock_db)를 만든 후, 국내 티커정보가 들어갈 테이블(kor_ticker)을 만들어준다.
create database stock_db;
use stock_db;
create table kor_ticker
(
종목코드 varchar(6) not null,
종목명 varchar(20),
시장구분 varchar(6),
종가 float,
시가총액 float,
기준일 date,
EPS float,
선행EPS float,
BPS float,
주당배당금 float,
종목구분 varchar(5),
primary key(종목코드, 기준일)
);

Fig. 10.7 국내 티커정보 테이블 생성#
파이썬에서 아래 코드를 실행하면 다운로드 받은 정보가 kor_ticker 테이블에 upsert 형태로 저장된다.
import pymysql
con = pymysql.connect(user='root',
passwd='1234',
host='127.0.0.1',
db='stock_db',
charset='utf8')
mycursor = con.cursor()
query = f"""
insert into kor_ticker (종목코드,종목명,시장구분,종가,시가총액,기준일,EPS,선행EPS,BPS,주당배당금,종목구분)
values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) as new
on duplicate key update
종목명=new.종목명,시장구분=new.시장구분,종가=new.종가,시가총액=new.시가총액,EPS=new.EPS,선행EPS=new.선행EPS,
BPS=new.BPS,주당배당금=new.주당배당금,종목구분 = new.종목구분;
"""
args = kor_ticker.values.tolist()
mycursor.executemany(query, args)
con.commit()
con.close()
Fig. 10.8 국내 티커정보 테이블#
10.3. WICS 기준 섹터정보 크롤링#
일반적으로 주식의 섹터를 나누는 기준은 MSCI와 S&P가 개발한 GICS를 가장 많이 사용한다. 국내 종목의 GICS 기준 정보 역시 한국거래소에서 제공하고 있으나, 이는 독점적 지적재산으로 명시했기에 사용하는데 무리가 있다. 그러나 지수제공업체인 FnGuide Index에서는 GICS와 비슷한 WICS 산업분류를 발표하고 있다. WICS를 크롤링하여 필요한 정보를 수집해보도록 하자.
http://www.wiseindex.com/Index
먼저 웹페이지에 접속해 왼쪽에서 [WISE SECTOR INDEX → WICS → 에너지]를 클릭한다. 그 후 [Components] 탭을 클릭하면 해당 섹터의 구성종목을 확인할 수 있다.
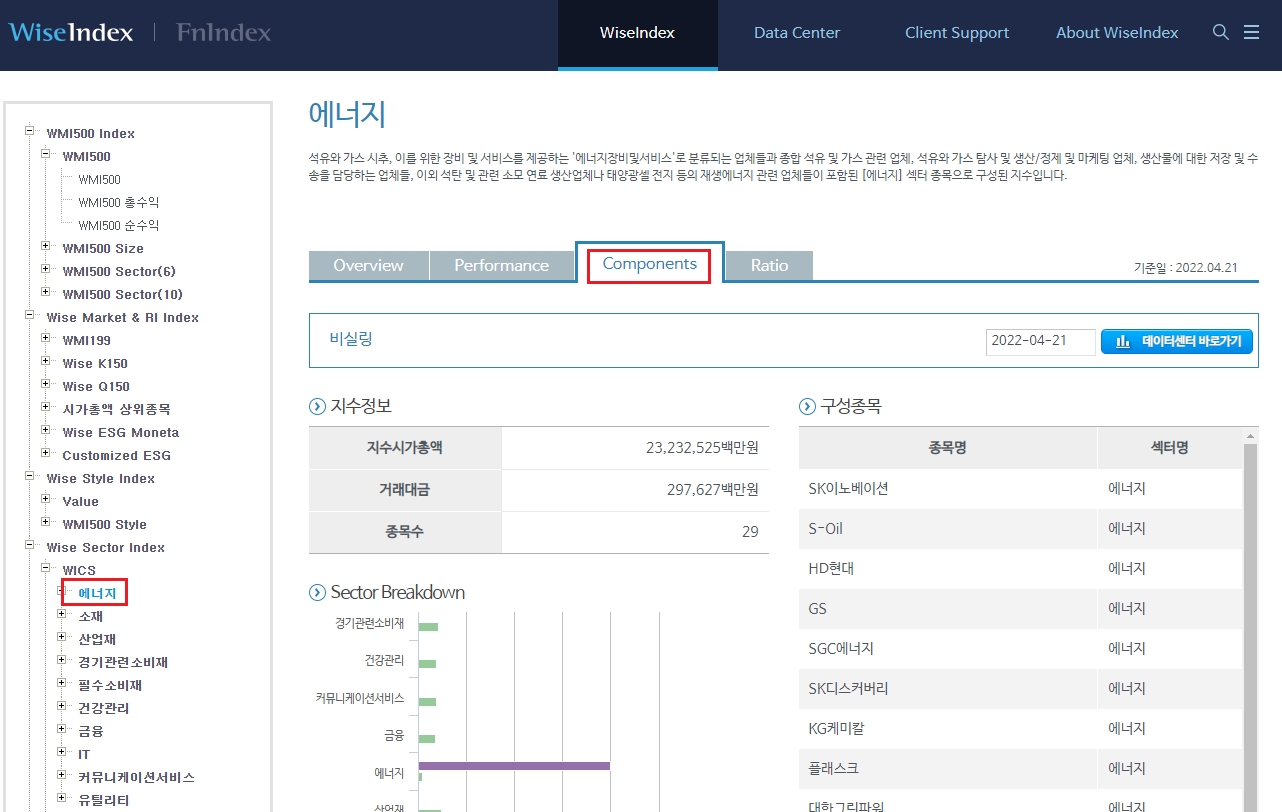
Fig. 10.9 WICS 기준 구성종목#
개발자도구 화면(Fig. 10.10)을 통해 해당 페이지의 데이터전송 과정을 살펴보자. 일자를 선택하면 [Network] 탭의 ‘GetIndexComponets’ 항목에 데이터 전송 과정이 나타난다. Request URL은 데이터를 가져오는 주소이며, 이를 분석하면 다음과 같다.
http://www.wiseindex.com/Index/GetIndexComponets?ceil_yn=0&dt=20210210&sec_cd=G10
http://www.wiseindex.com/Index/GetIndexComponets: 데이터를 요청하는 url이다.
ceil_yn = 0: 실링 여부를 나타내며, 0은 비실링을 의미한다.
dt=20220419: 조회일자를 나타낸다.
sec_cd=G10: 섹터 코드를 나타낸다.
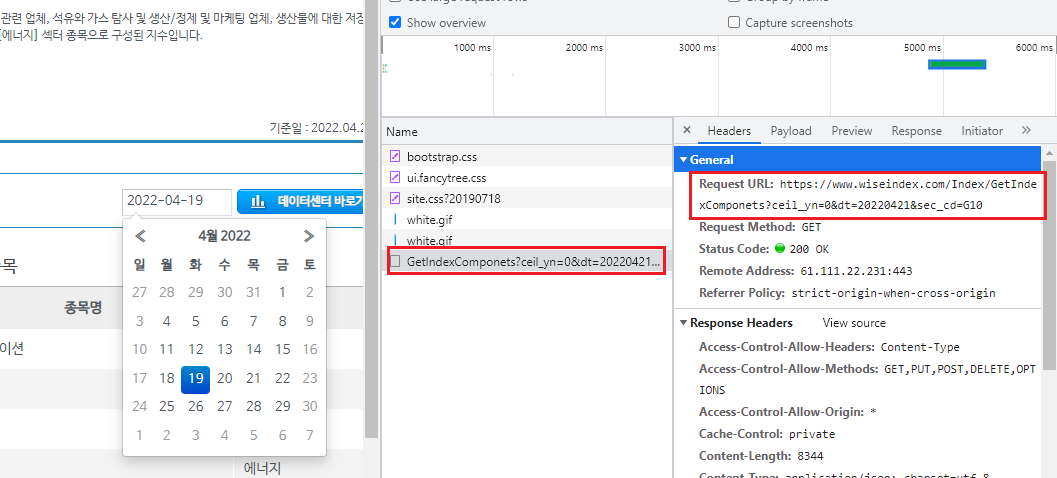
Fig. 10.10 WICS 페이지 개발자도구 화면#
이번에는 Request URL에 해당하는 페이지를 열어보자.

Fig. 10.11 WICS 데이터 페이지#
페이지에 출력된 글자들이 보이지만 매우 특이한 형태로 구성되어 있으며, 이는 JSON 형식의 데이터다. 기존에 우리가 살펴보았던 대부분의 웹페이지는 HTML 형식으로 표현되었다. HTML 형식은 문법이 복잡하고 표현 규칙이 엄격해 데이터의 용량이 커지는 단점이 있다. 반면 JSON 형식은 문법이 단순하고 데이터의 용량이 작아 빠른 속도로 데이터를 교환할 수 있다. 파이썬에서는 json 패키지를 사용해 매우 손쉽게 JSON 형식의 데이터를 크롤링할 수 있다.
import json
import requests as rq
import pandas as pd
url = f'''http://www.wiseindex.com/Index/GetIndexComponets?ceil_yn=0&dt={biz_day}&sec_cd=G10'''
data = rq.get(url).json()
type(data)
dict
f-string 포매팅을 이용해 dt 부분에는 위에서 구한 최근 영업일 데이터를 입력하여 URL을 생성한다.
get()함수를 통해 페이지의 내용을 받아오며,json()메서드를 통해 JSON 데이터만 불러올 수 있다.
파이썬에서는 JSON 데이터가 딕셔너리 형태로 변경된다. 어떠한 키가 있는지 확인해보자.
print(data.keys())
dict_keys(['info', 'list', 'sector', 'size'])
‘info’, ‘list’, ‘sector’, ‘size’ 중 list에는 해당 섹터의 구성종목 정보가, sector에는 각종 섹터의 코드 정보가 포함되어 있다. 하나씩 확인해보도록 하자.
data['list'][0]
{'IDX_CD': 'G10',
'IDX_NM_KOR': 'WICS 에너지',
'ALL_MKT_VAL': 22486171,
'CMP_CD': '096770',
'CMP_KOR': 'SK이노베이션',
'MKT_VAL': 9579432,
'WGT': 42.6,
'S_WGT': 42.6,
'CAL_WGT': 1.0,
'SEC_CD': 'G10',
'SEC_NM_KOR': '에너지',
'SEQ': 1,
'TOP60': 3,
'APT_SHR_CNT': 51780716}
data['sector']
[{'SEC_CD': 'G25', 'SEC_NM_KOR': '경기관련소비재', 'SEC_RATE': 10.89, 'IDX_RATE': 0},
{'SEC_CD': 'G35', 'SEC_NM_KOR': '건강관리', 'SEC_RATE': 10.47, 'IDX_RATE': 0},
{'SEC_CD': 'G50', 'SEC_NM_KOR': '커뮤니케이션서비스', 'SEC_RATE': 8.46, 'IDX_RATE': 0},
{'SEC_CD': 'G40', 'SEC_NM_KOR': '금융', 'SEC_RATE': 7.82, 'IDX_RATE': 0},
{'SEC_CD': 'G10', 'SEC_NM_KOR': '에너지', 'SEC_RATE': 1.99, 'IDX_RATE': 100.0},
{'SEC_CD': 'G20', 'SEC_NM_KOR': '산업재', 'SEC_RATE': 11.93, 'IDX_RATE': 0},
{'SEC_CD': 'G55', 'SEC_NM_KOR': '유틸리티', 'SEC_RATE': 1.26, 'IDX_RATE': 0},
{'SEC_CD': 'G30', 'SEC_NM_KOR': '필수소비재', 'SEC_RATE': 2.56, 'IDX_RATE': 0},
{'SEC_CD': 'G15', 'SEC_NM_KOR': '소재', 'SEC_RATE': 8.09, 'IDX_RATE': 0},
{'SEC_CD': 'G45', 'SEC_NM_KOR': 'IT', 'SEC_RATE': 36.53, 'IDX_RATE': 0}]
list 부분의 데이터를 데이터프레임 형태로 변경하도록 한다.
data_pd = pd.json_normalize(data['list'])
data_pd.head()
| IDX_CD | IDX_NM_KOR | ALL_MKT_VAL | CMP_CD | CMP_KOR | MKT_VAL | WGT | S_WGT | CAL_WGT | SEC_CD | SEC_NM_KOR | SEQ | TOP60 | APT_SHR_CNT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | G10 | WICS 에너지 | 22486171 | 096770 | SK이노베이션 | 9579432 | 42.60 | 42.60 | 1.0 | G10 | 에너지 | 1 | 3 | 51780716 |
| 1 | G10 | WICS 에너지 | 22486171 | 010950 | S-Oil | 3674027 | 16.34 | 58.94 | 1.0 | G10 | 에너지 | 2 | 3 | 41655633 |
| 2 | G10 | WICS 에너지 | 22486171 | 267250 | HD현대 | 2530306 | 11.25 | 70.19 | 1.0 | G10 | 에너지 | 3 | 3 | 44236128 |
| 3 | G10 | WICS 에너지 | 22486171 | 078930 | GS | 2011664 | 8.95 | 79.14 | 1.0 | G10 | 에너지 | 4 | 3 | 49245150 |
| 4 | G10 | WICS 에너지 | 22486171 | 112610 | 씨에스윈드 | 1360281 | 6.05 | 85.19 | 1.0 | G10 | 에너지 | 5 | 3 | 23615986 |
pandas 패키지의 json_normalize() 함수를 이용하면 JSON 형태의 데이터를 데이터프레임 형태로 매우 쉽게 변경할 수 있다. 이제 for문을 이용하여 URL의 sec_cd=에 해당하는 부분만 변경하면 모든 섹터의 구성종목을 매우 쉽게 얻을 수 있다.
import time
import json
import requests as rq
import pandas as pd
from tqdm import tqdm
sector_code = [
'G25', 'G35', 'G50', 'G40', 'G10', 'G20', 'G55', 'G30', 'G15', 'G45'
]
data_sector = []
for i in tqdm(sector_code):
url = f'''http://www.wiseindex.com/Index/GetIndexComponets?ceil_yn=0&dt={biz_day}&sec_cd={i}'''
data = rq.get(url).json()
data_pd = pd.json_normalize(data['list'])
data_sector.append(data_pd)
time.sleep(2)
kor_sector = pd.concat(data_sector, axis = 0)
kor_sector = kor_sector[['IDX_CD', 'CMP_CD', 'CMP_KOR', 'SEC_NM_KOR']]
kor_sector['기준일'] = biz_day
kor_sector['기준일'] = pd.to_datetime(kor_sector['기준일'])
섹터 정보가 들어갈 빈 리스트(data_sector)를 만든다.
for문의 i에 섹터 코드를 입력하여 모든 섹터의 구성종목을 다운로드 받은 후
append()메서드를 통해 리스트에 추가한다.tqdm()함수를 통해 진행상황을 출력한다.concat()함수를 이용해 리스트 내의 데이터프레임을 합친다.필요한 열(섹터 코드, 티커, 종목명, 섹터명)만 선택한다.
데이터의 기준일에 해당하는 [기준일] 열을 추가한 후 datetime 형태로 변경한다.
이제 SQL에 해당 정보가 들어갈 테이블을 만들어 준 후 저장을 해주도록 한다.
use stock_db;
create table kor_sector
(
IDX_CD varchar(3),
CMP_CD varchar(6),
CMP_KOR varchar(20),
SEC_NM_KOR varchar(10),
기준일 date,
primary key(CMP_CD, 기준일)
);
먼저 MySQL에서 국내 섹터정보가 들어갈 테이블(kor_sector)을 만들어준다.
import pymysql
con = pymysql.connect(user='root',
passwd='1234',
host='127.0.0.1',
db='stock_db',
charset='utf8')
mycursor = con.cursor()
query = f"""
insert into kor_sector (IDX_CD, CMP_CD, CMP_KOR, SEC_NM_KOR, 기준일)
values (%s,%s,%s,%s,%s) as new
on duplicate key update
IDX_CD = new.IDX_CD, CMP_KOR = new.CMP_KOR, SEC_NM_KOR = new.SEC_NM_KOR
"""
args = kor_sector.values.tolist()
mycursor.executemany(query, args)
con.commit()
con.close()
파이썬에서 위 코드를 실행하면 다운로드 받은 정보가 kor_sector 테이블에 upsert 형태로 저장된다.
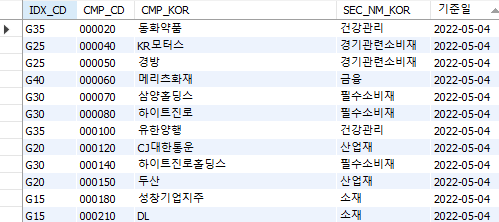
Fig. 10.12 섹터 테이블#
10.4. 수정주가 크롤링#
주가 데이터는 투자를 함에 있어 반드시 필요한 데이터이며, 인터넷에서 주가를 수집할 수 있는 방법은 매우 많다. 그러나 일반적인 주가를 구할 수 있는 방법은 많지만, 퀀트 투자를 위한 백테스트나 종목선정을 위해서는 수정주가가 필요하다. 수정주가가 필요한 이유를 알아보기 위해 실제 사례를 살펴보도록 하자. 삼성전자는 2018년 5월 기존의 1주를 50주로 나누는 액면분할을 실시했고, 265만 원이던 주가는 다음날 50분의 1인 5만 3000원으로 거래되었다. 이러한 이벤트를 고려하지 않고 주가만 살펴본다면 마치 -98% 수익률을 기록한 것 같지만, 투자자 입장에서는 1주이던 주식이 50주로 늘어났기 때문에 자산에는 아무런 변화가 없다. 이를 고려하는 방법은 액면분할 전 모든 주가를 50으로 나누어 연속성을 갖게 만드는 것이며, 이를 ‘수정주가’라고 한다. 따라서 백테스트 혹은 퀀트 지표 계산에는 수정주가가 사용되어야 하며, 네이버 금융에서 제공하는 정보를 통해 모든 종목의 수정주가를 손쉽게 구할 수 있다.
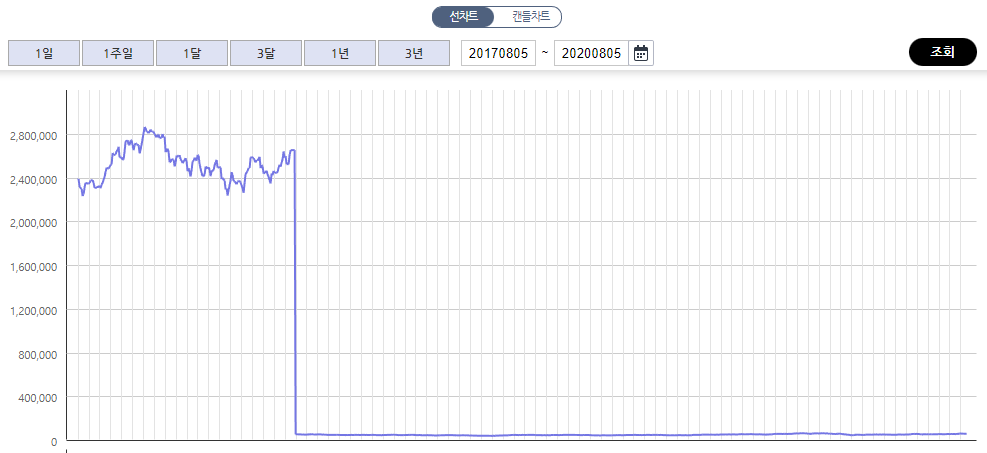
Fig. 10.13 액면분할을 반영하지 않은 삼성전자의 주가 그래프#
10.4.1. 개별종목 주가 크롤링#
먼저 네이버 금융에서 특정종목(예: 삼성전자)의 [차트]탭을 선택한다.
https://finance.naver.com/item/fchart.nhn?code=005930
해당 차트는 주가 데이터를 받아와 화면에 그래프를 그려주는 형태다. 따라서 데이터가 어디에서 오는지 알기 위해 개발자도구 화면을 이용한다. 화면을 연 상태에서 [일]을 선택하면 나오는 항목 중 가장 상단 항목 [siseJson.naver?symbol=..]의 Request URL이 주가 데이터를 요청하는 주소다.
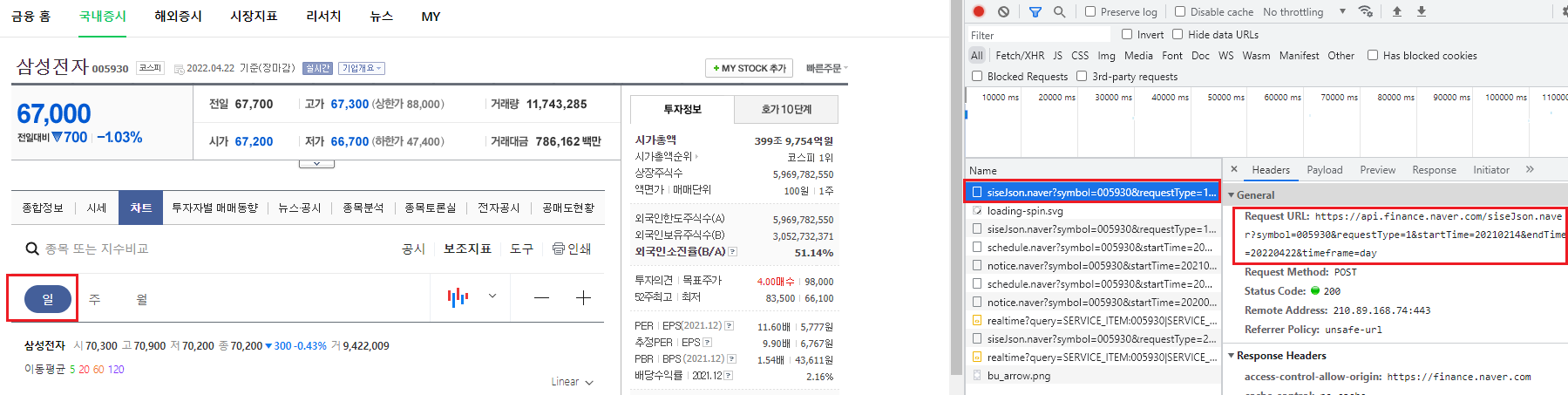
Fig. 10.14 네이버 금융 차트의 통신기록#
URL은 다음과 같다.
https://api.finance.naver.com/siseJson.naver?symbol=005930&requestType=1&startTime=20200214&endTime=20220422&timeframe=day
위 페이지에 접속하면 Fig. 10.15와 같이 날짜별로 시가, 고가, 저가, 종가, 거래량, 외국인소진율이 있으며, 주가는 모두 수정주가 기준이다. URL에서 ‘symbol=’ 뒤에 6자리 티커만 변경하면 해당 종목의 주가 데이터가 있는 페이지로 이동할 수 있으며, 이를 통해 우리가 원하는 모든 종목의 수정주가 데이터를 크롤링할 수 있다. 또한 ‘startTime=’ 에는 시작일자를, ‘endTime=’ 에는 종료일자를 입력하여 원하는 기간 만큼의 데이터를 받을 수도 있다.

Fig. 10.15 주가 데이터 페이지#
본격적인 주가 데이터 수집을 위해 먼저 DB에서 티커 데이터를 불러오도록 하자.
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/stock_db')
query = """
select * from kor_ticker
where 기준일 = (select max(기준일) from kor_ticker)
and 종목구분 = '보통주';
"""
ticker_list = pd.read_sql(query, con=engine)
engine.dispose()
ticker_list.head()
| 종목코드 | 종목명 | 시장구분 | 종가 | 시가총액 | 기준일 | EPS | 선행EPS | BPS | 주당배당금 | 종목구분 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 000020 | 동화약품 | KOSPI | 10600.0 | 2.960740e+11 | 2022-08-03 | 647.0 | NaN | 12534.0 | 180.0 | 보통주 |
| 1 | 000040 | KR모터스 | KOSPI | 703.0 | 6.758530e+10 | 2022-08-03 | NaN | NaN | 385.0 | 0.0 | 보통주 |
| 2 | 000050 | 경방 | KOSPI | 12850.0 | 3.522860e+11 | 2022-08-03 | 872.0 | NaN | 30033.0 | 125.0 | 보통주 |
| 3 | 000060 | 메리츠화재 | KOSPI | 36150.0 | 4.222390e+12 | 2022-08-03 | 5768.0 | 6211.0 | 22086.0 | 620.0 | 보통주 |
| 4 | 000070 | 삼양홀딩스 | KOSPI | 72500.0 | 6.209100e+11 | 2022-08-03 | 30711.0 | NaN | 226314.0 | 3000.0 | 보통주 |
create_engine()함수를 통해 데이터베이스에 접속하기 위한 엔진을 만든다.티커 데이터를 불러오는 쿼리를 작성하며, 가장 최근일자에 해당하는 내용을 불러오기 위해 서브쿼리에
select max(기준일) from kor_ticker을 입력한다. 또한 종목구분에서 보통주에 해당하는 종목만 선택한다.read_sql()함수를 통해 해당 쿼리를 보낸 후 데이터를 받아온다.접속을 종료한다.
이제 위에서 살펴본 주가 데이터 페이지를 크롤링 하도록 하겠다.
from dateutil.relativedelta import relativedelta
import requests as rq
from io import BytesIO
from datetime import date
i = 0
ticker = ticker_list['종목코드'][i]
fr = (date.today() + relativedelta(years=-5)).strftime("%Y%m%d")
to = (date.today()).strftime("%Y%m%d")
url = f'''https://fchart.stock.naver.com/siseJson.nhn?symbol={ticker}&requestType=1
&startTime={fr}&endTime={to}&timeframe=day'''
data = rq.get(url).content
data_price = pd.read_csv(BytesIO(data))
data_price.head()
| [['날짜' | '시가' | '고가' | '저가' | '종가' | '거래량' | '외국인소진율'] | Unnamed: 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | ["20170807" | 8330.0 | 8410.0 | 8320.0 | 8380.0 | 35043.0 | 7.84] | NaN |
| 1 | ["20170808" | 8380.0 | 8380.0 | 8290.0 | 8330.0 | 28242.0 | 7.82] | NaN |
| 2 | ["20170809" | 8330.0 | 8330.0 | 8150.0 | 8150.0 | 93844.0 | 7.76] | NaN |
| 3 | ["20170810" | 8150.0 | 8280.0 | 8120.0 | 8200.0 | 54760.0 | 7.77] | NaN |
| 4 | ["20170811" | 8150.0 | 8250.0 | 7980.0 | 8130.0 | 128133.0 | 7.73] | NaN |
먼저 i = 0을 입력한다. 향후 for문을 통해 i 값만 변경하면 모든 종목의 주가를 다운로드할 수 있다.
ticker_list['종목코드'][i]를 통해 원하는 종목의 티커를 선택한다.시작일(fr)과 종료일(to)에 해당하는 날짜를 만들어준다.
today()메서드를 이용해 오늘 날짜를 불러온 후, 시작일은relativedelta()클래스를 이용해 5년을 빼준다. (본인이 원하는 기간 만큼을 빼주면 된다.) 그 후strftime()메서드를 통해 ‘yyyymmdd’ 형식을 만들어 준다. 종료일은 오늘 날짜를 그대로 사용한다.티커, 시작일, 종료일을 이용해 주가 데이터가 있는 URL을 생성한다.
get()함수를 통해 페이지의 데이터를 불러온 후, content 부분을 추출한다.BytesIO()를 이용해 바이너리스트림 형태로 만든 후,read_csv()함수를 통해 데이터를 읽어온다.
결과를 확인해보면 날짜 및 주가, 거래량, 외국인소진율 데이터가 추출된다. 추가적으로 클렌징 작업을 해주도록 하겠다.
import re
price = data_price.iloc[:, 0:6]
price.columns = ['날짜', '시가', '고가', '저가', '종가', '거래량']
price = price.dropna()
price['날짜'] = price['날짜'].str.extract('(\d+)')
price['날짜'] = pd.to_datetime(price['날짜'])
price['종목코드'] = ticker
price.head()
| 날짜 | 시가 | 고가 | 저가 | 종가 | 거래량 | 종목코드 | |
|---|---|---|---|---|---|---|---|
| 0 | 2017-08-07 | 8330.0 | 8410.0 | 8320.0 | 8380.0 | 35043.0 | 000020 |
| 1 | 2017-08-08 | 8380.0 | 8380.0 | 8290.0 | 8330.0 | 28242.0 | 000020 |
| 2 | 2017-08-09 | 8330.0 | 8330.0 | 8150.0 | 8150.0 | 93844.0 | 000020 |
| 3 | 2017-08-10 | 8150.0 | 8280.0 | 8120.0 | 8200.0 | 54760.0 | 000020 |
| 4 | 2017-08-11 | 8150.0 | 8250.0 | 7980.0 | 8130.0 | 128133.0 | 000020 |
iloc()인덱서를 통해 날짜와 가격(시가, 고가, 저가, 종가), 거래량에 해당하는 데이터만을 선택한다.열 이름을 변경한다.
dropna()함수를 통해 NA 데이터를 삭제한다.extract()메서드 내에 정규 표현식을 이용해 날짜 열에서 숫자만을 추출한다.‘날짜’열을 datetime 형태로 변경한다.
‘종목코드’열에 티커를 입력한다.
데이터를 확인해보면 우리에게 필요한 형태로 정리되었다.
10.4.2. 전 종목 주가 크롤링#
위 과정을 응용해 모든 종목의 주가를 크롤링한 후 DB에 저장하는 과정을 살펴보도록 하겠다. 먼저 SQL에서 주가가 저장될 테이블(kor_price)을 만들어준다.
use stock_db;
create table kor_price
(
날짜 date,
시가 double,
고가 double,
저가 double,
종가 double,
거래량 double,
종목코드 varchar(6),
primary key(날짜, 종목코드)
);
이제 파이썬에서 아래 코드를 실행하면 for문을 통해 전종목 주가가 DB에 저장된다.
# 패키지 불러오기
import pymysql
from sqlalchemy import create_engine
import pandas as pd
from datetime import date
from dateutil.relativedelta import relativedelta
import requests as rq
import time
from tqdm import tqdm
from io import BytesIO
# DB 연결
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/stock_db')
con = pymysql.connect(user='root',
passwd='1234',
host='127.0.0.1',
db='stock_db',
charset='utf8')
mycursor = con.cursor()
# 티커리스트 불러오기
ticker_list = pd.read_sql("""
select * from kor_ticker
where 기준일 = (select max(기준일) from kor_ticker)
and 종목구분 = '보통주';
""", con=engine)
# DB 저장 쿼리
query = """
insert into kor_price (날짜, 시가, 고가, 저가, 종가, 거래량, 종목코드)
values (%s,%s,%s,%s,%s,%s,%s) as new
on duplicate key update
시가 = new.시가, 고가 = new.고가, 저가 = new.저가,
종가 = new.종가, 거래량 = new.거래량;
"""
# 오류 발생시 저장할 리스트 생성
error_list = []
# 전종목 주가 다운로드 및 저장
for i in tqdm(range(0, len(ticker_list))):
# 티커 선택
ticker = ticker_list['종목코드'][i]
# 시작일과 종료일
fr = (date.today() + relativedelta(years=-5)).strftime("%Y%m%d")
to = (date.today()).strftime("%Y%m%d")
# 오류 발생 시 이를 무시하고 다음 루프로 진행
try:
# url 생성
url = f'''https://fchart.stock.naver.com/siseJson.nhn?symbol={ticker}&requestType=1
&startTime={fr}&endTime={to}&timeframe=day'''
# 데이터 다운로드
data = rq.get(url).content
data_price = pd.read_csv(BytesIO(data))
# 데이터 클렌징
price = data_price.iloc[:, 0:6]
price.columns = ['날짜', '시가', '고가', '저가', '종가', '거래량']
price = price.dropna()
price['날짜'] = price['날짜'].str.extract('(\d+)')
price['날짜'] = pd.to_datetime(price['날짜'])
price['종목코드'] = ticker
# 주가 데이터를 DB에 저장
args = price.values.tolist()
mycursor.executemany(query, args)
con.commit()
except:
# 오류 발생시 error_list에 티커 저장하고 넘어가기
print(ticker)
error_list.append(ticker)
# 타임슬립 적용
time.sleep(2)
# DB 연결 종료
engine.dispose()
con.close()
DB에 연결한다.
기준일이 최대, 즉 최근일 기준 보통주에 해당하는 티커 리스트(ticker_list)만 불러온다.
DB에 저장할 쿼리(query)를 입력한다.
오류 발생시 저장할 리스트(error_list)를 만든다.
for문을 통해 전종목 주가를 다운로드 받으며, 진행상황을 알기위해
tqdm()함수를 이용한다.URL 생성, 데이터 다운로드 및 데이터 클렌징 및 DB에 저장은 위와 동일하며, try except문을 통해 오류가 발생시 티커를 출력 후 error_list에 저장한다.
무한 크롤링을 방지하기 위해 한 번의 루프가 끝날 때마다 타임슬립을 적용한다.
모든 작업이 끝나면 DB와의 연결을 종료한다.
작업이 끝난 후 SQL의 kor_price 테이블을 확인해보면 전 종목 주가가 저장되어 있다. 시간이 지나 위 코드를 다시 실행하면 upsert 형식을 통해 수정된 주가는 update를, 새로 입력된 주가는 insert를 한다.
Fig. 10.16 주가 테이블#
10.5. 재무제표 크롤링#
주가와 더불어 재무제표와 가치지표 역시 투자에 있어 핵심이 되는 데이터다. 해당 데이터는 여러 웹사이트에서 구할 수 있으며, 국내 데이터 제공업체인 FnGuide에서 운영하는 Company Guide 웹사이트에서 손쉽게 구할 수 있다.
http://comp.fnguide.com/
10.5.1. 재무제표 다운로드#
먼저 웹사이트에서 개별종목의 재무제표를 탭을 선택하면 포괄손익계산서, 재무상태표, 현금흐름표 항목이 있으며, 티커에 해당하는 A005930 뒤의 주소는 불필요한 내용이므로, 이를 제거한 주소로 접속한다. A 뒤의 6자리 티커만 변경한다면 해당 종목의 재무제표 페이지로 이동하게 된다.
http://comp.fnguide.com/SVO2/ASP/SVD_Finance.asp?pGB=1&gicode=A005930
Fig. 10.17 Company Guide 화면#
우리가 원하는 재무제표 항목들은 모두 테이블 형태로 제공되고 있으므로 pandas 패키지의 read_html() 함수를 이용해 쉽게 추출할 수 있다. 먼저 삼성전자 종목의 페이지 내용을 불러오자.
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/stock_db')
query = """
select * from kor_ticker
where 기준일 = (select max(기준일) from kor_ticker)
and 종목구분 = '보통주';
"""
ticker_list = pd.read_sql(query, con=engine)
engine.dispose()
i = 0
ticker = ticker_list['종목코드'][i]
url = f'http://comp.fnguide.com/SVO2/ASP/SVD_Finance.asp?pGB=1&gicode=A{ticker}'
data = pd.read_html(url, displayed_only=False)
[item.head(3) for item in data]
[ IFRS(연결) 2019/12 2020/12 2021/12 2022/03 전년동기 전년동기(%)
0 매출액 3072.0 2721.0 2930.0 853.0 718.0 18.7
1 매출원가 1856.0 1334.0 1437.0 406.0 360.0 12.9
2 매출총이익 1216.0 1387.0 1493.0 447.0 358.0 24.6,
IFRS(연결) 2021/06 2021/09 2021/12 2022/03 전년동기 전년동기(%)
0 매출액 758.0 691.0 763.0 853.0 718.0 18.7
1 매출원가 374.0 348.0 355.0 406.0 360.0 12.9
2 매출총이익 384.0 343.0 408.0 447.0 358.0 24.6,
IFRS(연결) 2019/12 2020/12 2021/12 2022/03
0 자산 3764.0 4338.0 4478.0 4600.0
1 유동자산계산에 참여한 계정 펼치기 2355.0 2227.0 2202.0 2287.0
2 재고자산 334.0 395.0 362.0 357.0,
IFRS(연결) 2021/06 2021/09 2021/12 2022/03
0 자산 4471.0 4479.0 4478.0 4600.0
1 유동자산계산에 참여한 계정 펼치기 2274.0 2180.0 2202.0 2287.0
2 재고자산 431.0 420.0 362.0 357.0,
IFRS(연결) 2019/12 2020/12 2021/12 2022/03
0 영업활동으로인한현금흐름 133.0 522.0 360.0 166.0
1 당기순손익 91.0 287.0 196.0 58.0
2 법인세비용차감전계속사업이익 NaN NaN NaN NaN,
IFRS(연결) 2021/06 2021/09 2021/12 2022/03
0 영업활동으로인한현금흐름 63.0 48.0 161.0 166.0
1 당기순손익 70.0 8.0 62.0 58.0
2 법인세비용차감전계속사업이익 NaN NaN NaN NaN]
티커 리스트를 불러와 첫번째 티커를 선택한다.
재무제표 페이지에 해당하는 URL을 생성한다.
read_html()함수를 통해 테이블 데이터만을 가져온다. 페이지를 살펴보면 [+] 버튼을 눌러야만 표시가 되는 항목도 있으므로,displayed_only = False를 통해 해당 항목들도 모두 가져온다.
위의 과정을 거치면 총 6개의 테이블이 들어오게 되며, 그 내용은 Table 10.1와 같다.
순서 |
내용 |
|---|---|
0 |
포괄손익계산서 (연간) |
1 |
포괄손익계산서 (분기) |
2 |
재무상태표 (연간) |
3 |
재무상태표 (분기) |
4 |
현금흐름표 (연간) |
5 |
현금흐름표 (분기) |
먼저 연간 기준 포괄손익계산서, 재무상태표, 현금흐름표의 열 이름을 살펴보자.
print(data[0].columns.tolist(), '\n',
data[2].columns.tolist(), '\n',
data[4].columns.tolist()
)
['IFRS(연결)', '2019/12', '2020/12', '2021/12', '2022/03', '전년동기', '전년동기(%)']
['IFRS(연결)', '2019/12', '2020/12', '2021/12', '2022/03']
['IFRS(연결)', '2019/12', '2020/12', '2021/12', '2022/03']
포괄손익계산서 테이블에는 ‘전년동기’, ‘전년동기(%)’ 열이 있으며, 이는 필요하지 않은 내용이므로 삭제해주어야 한다.
data_fs_y = pd.concat(
[data[0].iloc[:, ~data[0].columns.str.contains('전년동기')], data[2], data[4]])
data_fs_y = data_fs_y.rename(columns={data_fs_y.columns[0]: "계정"})
data_fs_y.head()
| 계정 | 2019/12 | 2020/12 | 2021/12 | 2022/03 | |
|---|---|---|---|---|---|
| 0 | 매출액 | 3072.0 | 2721.0 | 2930.0 | 853.0 |
| 1 | 매출원가 | 1856.0 | 1334.0 | 1437.0 | 406.0 |
| 2 | 매출총이익 | 1216.0 | 1387.0 | 1493.0 | 447.0 |
| 3 | 판매비와관리비계산에 참여한 계정 펼치기 | 1120.0 | 1155.0 | 1269.0 | 356.0 |
| 4 | 인건비 | 400.0 | 415.0 | 468.0 | 134.0 |
포괄손익계산서 중 ‘전년동기’라는 글자가 들어간 열을 제외한 데이터를 선택한다.
concat()함수를 이용해 포괄손익계산서, 재무상태표, 현금흐름표 세개 테이블을 하나로 묶는다.rename()메서드를 통해 첫번째 열 이름(IFRS 혹은 IFRS(연결)을 ‘계정’으로 변경한다.
결산마감 이전에 해당 페이지를 크롤링 할 경우 연간 재무제표 데이터에 분기 재무제표 데이터가 들어오기도 하므로, 연간 재무제표에 해당하는 열 만을 선택해야 한다. 각 종목 별 결산월은 해당 페이지의 상단에서 확인할 수 있다.

Fig. 10.18 종목 별 결산월#
이제 해당 데이터를 크롤링 해보도록 하겠다.
import requests as rq
from bs4 import BeautifulSoup
import re
page_data = rq.get(url)
page_data_html = BeautifulSoup(page_data.content, 'html.parser')
fiscal_data = page_data_html.select('div.corp_group1 > h2')
fiscal_data_text = fiscal_data[1].text
fiscal_data_text = re.findall('[0-9]+', fiscal_data_text)
print(fiscal_data_text)
['12']
get()함수를 통해 페이지의 데이터를 불러온 후, content 부분을 BeautifulSoup 객체로 만든다.결산월 항목운 [corp_group1 클래스의 div 태그 하부의 h2 태그]에 존재하므로,
select()함수를 이용해 추출한다.fiscal_data 중 첫번째는 종목코드에 해당하고, 두번째가 결산 데이터에 해당하므로 해당 부분을 선택해 텍스트만 추출한다.
‘n월 결산’ 형태로 텍스트가 구성되어 있으므로, 정규 표현식을 이용해 숫자에 해당하는 부분만 추출한다.
이를 통해 결산월에 해당하는 부분만이 선택된다. 이를 이용해 연간 재무제표에 해당하는 열만 선택해보도록 하자.
data_fs_y = data_fs_y.loc[:, (data_fs_y.columns == '계정') |
(data_fs_y.columns.str[-2:].isin(fiscal_data_text))]
data_fs_y.head()
| 계정 | 2019/12 | 2020/12 | 2021/12 | |
|---|---|---|---|---|
| 0 | 매출액 | 3072.0 | 2721.0 | 2930.0 |
| 1 | 매출원가 | 1856.0 | 1334.0 | 1437.0 |
| 2 | 매출총이익 | 1216.0 | 1387.0 | 1493.0 |
| 3 | 판매비와관리비계산에 참여한 계정 펼치기 | 1120.0 | 1155.0 | 1269.0 |
| 4 | 인건비 | 400.0 | 415.0 | 468.0 |
열 이름이 ‘계정’, 그리고 재무제표의 월이 결산월과 같은 부분만 선택한다. 이제 추가적으로 클렌징해야 하는 사항은 다음과 같다.
data_fs_y[data_fs_y.loc[:, ~data_fs_y.columns.isin(['계정'])].isna().all(
axis=1)].head()
| 계정 | 2019/12 | 2020/12 | 2021/12 | |
|---|---|---|---|---|
| 10 | 기타원가성비용 | NaN | NaN | NaN |
| 18 | 대손충당금환입액 | NaN | NaN | NaN |
| 19 | 매출채권처분이익 | NaN | NaN | NaN |
| 20 | 당기손익-공정가치측정 금융자산관련이익 | NaN | NaN | NaN |
| 23 | 금융자산손상차손환입 | NaN | NaN | NaN |
먼저 재무제표 값 중에서 모든 연도의 데이터가 NaN인 항목이 있다. 이는 재무제표 계정은 있으나 해당 종목들은 데이터가 없는 것들이므로 삭제해도 된다.
data_fs_y['계정'].value_counts(ascending=False).head()
기타 4
배당금수익 3
파생상품이익 3
이자수익 3
법인세납부(-) 3
Name: 계정, dtype: int64
또한 동일한 계정명이 여러번 반복된다. 이러한 계정은 대부분 중요하지 않은 것들이므로, 하나만 남겨두도록 한다. 이 외에도 클렌징이 필요한 내용들을 함수로 구성하면 다음과 같다.
def clean_fs(df, ticker, frequency):
df = df[~df.loc[:, ~df.columns.isin(['계정'])].isna().all(axis=1)]
df = df.drop_duplicates(['계정'], keep='first')
df = pd.melt(df, id_vars='계정', var_name='기준일', value_name='값')
df = df[~pd.isnull(df['값'])]
df['계정'] = df['계정'].replace({'계산에 참여한 계정 펼치기': ''}, regex=True)
df['기준일'] = pd.to_datetime(df['기준일'],
format='%Y-%m') + pd.tseries.offsets.MonthEnd()
df['종목코드'] = ticker
df['공시구분'] = frequency
return df
입력값으로는 데이터프레임, 티커, 공시구분(연간/분기)가 필요하다.
먼저 연도의 데이터가 NaN인 항목은 제외한다.
계정명이 중복되는 경우
drop_duplicates()함수를 이용해 첫번째에 위치하는 데이터만 남긴다.melt()함수를 이용해 열로 긴 데이터를 행으로 긴 데이터로 변경한다.계정값이 없는 항목은 제외한다.
[계산에 참여한 계정 펼치기]라는 글자는 페이지의 [+]에 해당하는 부분이므로
replace()메서드를 통해 제거한다.to_datetime()메서드를 통해 기준일을 ‘yyyy-mm’ 형태로 바꾼 후,MonthEnd()를 통해 월말에 해당하는 일을 붙인다.‘종목코드’ 열에는 티커를 입력한다.
‘공시구분’ 열에는 연간 혹은 분기에 해당하는 값을 입력한다.
연간 재무제표 항목에 위 함수를 적용하면 다음과 같은 결과를 확인할 수 있다.
data_fs_y_clean = clean_fs(data_fs_y, ticker, 'y')
data_fs_y_clean.head()
| 계정 | 기준일 | 값 | 종목코드 | 공시구분 | |
|---|---|---|---|---|---|
| 0 | 매출액 | 2019-12-31 | 3072.0 | 000020 | y |
| 1 | 매출원가 | 2019-12-31 | 1856.0 | 000020 | y |
| 2 | 매출총이익 | 2019-12-31 | 1216.0 | 000020 | y |
| 3 | 판매비와관리비 | 2019-12-31 | 1120.0 | 000020 | y |
| 4 | 인건비 | 2019-12-31 | 400.0 | 000020 | y |
클렌징 처리가 된 데이터가 세로로 긴 형태로 변경되었다. 이제 분기 재무제표도 클렌징 처리를 해보도록 하자.
# 분기 데이터
data_fs_q = pd.concat(
[data[1].iloc[:, ~data[1].columns.str.contains('전년동기')], data[3], data[5]])
data_fs_q = data_fs_q.rename(columns={data_fs_q.columns[0]: "계정"})
data_fs_q_clean = clean_fs(data_fs_q, ticker, 'q')
data_fs_q_clean.head()
| 계정 | 기준일 | 값 | 종목코드 | 공시구분 | |
|---|---|---|---|---|---|
| 0 | 매출액 | 2021-06-30 | 758.0 | 000020 | q |
| 1 | 매출원가 | 2021-06-30 | 374.0 | 000020 | q |
| 2 | 매출총이익 | 2021-06-30 | 384.0 | 000020 | q |
| 3 | 판매비와관리비 | 2021-06-30 | 312.0 | 000020 | q |
| 4 | 인건비 | 2021-06-30 | 116.0 | 000020 | q |
분기 데이터는 결산월에 해당하는 부분을 선택할 필요가 없으며, 이를 제외하고는 모든 과정이 연간 재무제표를 항목과 동일하다.
data_fs_bind = pd.concat([data_fs_y_clean, data_fs_q_clean])
concat() 함수를 통해 두 테이블을 하나로 묶어준다.
10.5.2. 전종목 재무제표 크롤링#
위 과정을 응용해 모든 종목의 재무제표를 크롤링한 후 DB에 저장하는 과정을 살펴보도록 하겠다. 먼저 SQL에서 재무제표가 저장될 테이블(kor_fs)을 만들어준다.
use stock_db;
create table kor_fs
(
계정 varchar(30),
기준일 date,
값 float,
종목코드 varchar(6),
공시구분 varchar(1),
primary key(계정, 기준일, 종목코드, 공시구분)
)
이제 파이썬에서 아래 코드를 실행하면 for문을 통해 전종목 재무제표가 DB에 저장된다.
# 패키지 불러오기
import pymysql
from sqlalchemy import create_engine
import pandas as pd
import requests as rq
from bs4 import BeautifulSoup
import re
from tqdm import tqdm
import time
# DB 연결
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/stock_db')
con = pymysql.connect(user='root',
passwd='1234',
host='127.0.0.1',
db='stock_db',
charset='utf8')
mycursor = con.cursor()
# 티커리스트 불러오기
ticker_list = pd.read_sql("""
select * from kor_ticker
where 기준일 = (select max(기준일) from kor_ticker)
and 종목구분 = '보통주';
""", con=engine)
# DB 저장 쿼리
query = """
insert into kor_fs (계정, 기준일, 값, 종목코드, 공시구분)
values (%s,%s,%s,%s,%s) as new
on duplicate key update
값=new.값
"""
# 오류 발생시 저장할 리스트 생성
error_list = []
# 재무제표 클렌징 함수
def clean_fs(df, ticker, frequency):
df = df[~df.loc[:, ~df.columns.isin(['계정'])].isna().all(axis=1)]
df = df.drop_duplicates(['계정'], keep='first')
df = pd.melt(df, id_vars='계정', var_name='기준일', value_name='값')
df = df[~pd.isnull(df['값'])]
df['계정'] = df['계정'].replace({'계산에 참여한 계정 펼치기': ''}, regex=True)
df['기준일'] = pd.to_datetime(df['기준일'],
format='%Y-%m') + pd.tseries.offsets.MonthEnd()
df['종목코드'] = ticker
df['공시구분'] = frequency
return df
# for loop
for i in tqdm(range(0, len(ticker_list))):
# 티커 선택
ticker = ticker_list['종목코드'][i]
# 오류 발생 시 이를 무시하고 다음 루프로 진행
try:
# url 생성
url = f'http://comp.fnguide.com/SVO2/ASP/SVD_Finance.asp?pGB=1&gicode=A{ticker}'
# 데이터 받아오기
data = pd.read_html(url, displayed_only=False)
# 연간 데이터
data_fs_y = pd.concat([
data[0].iloc[:, ~data[0].columns.str.contains('전년동기')], data[2],
data[4]
])
data_fs_y = data_fs_y.rename(columns={data_fs_y.columns[0]: "계정"})
# 결산년 찾기
page_data = rq.get(url)
page_data_html = BeautifulSoup(page_data.content, 'html.parser')
fiscal_data = page_data_html.select('div.corp_group1 > h2')
fiscal_data_text = fiscal_data[1].text
fiscal_data_text = re.findall('[0-9]+', fiscal_data_text)
# 결산년에 해당하는 계정만 남기기
data_fs_y = data_fs_y.loc[:, (data_fs_y.columns == '계정') | (
data_fs_y.columns.str[-2:].isin(fiscal_data_text))]
# 클렌징
data_fs_y_clean = clean_fs(data_fs_y, ticker, 'y')
# 분기 데이터
data_fs_q = pd.concat([
data[1].iloc[:, ~data[1].columns.str.contains('전년동기')], data[3],
data[5]
])
data_fs_q = data_fs_q.rename(columns={data_fs_q.columns[0]: "계정"})
data_fs_q_clean = clean_fs(data_fs_q, ticker, 'q')
# 두개 합치기
data_fs_bind = pd.concat([data_fs_y_clean, data_fs_q_clean])
# 재무제표 데이터를 DB에 저장
args = data_fs_bind.values.tolist()
mycursor.executemany(query, args)
con.commit()
except:
# 오류 발생시 해당 종목명을 저장하고 다음 루프로 이동
print(ticker)
error_list.append(ticker)
# 타임슬립 적용
time.sleep(2)
# DB 연결 종료
engine.dispose()
con.close()
DB에 연결한다.
기준일이 최대, 즉 최근일 기준 보통주에 해당하는 티커 리스트(ticker_list)만 불러온다.
DB에 저장할 쿼리(query)를 입력한다.
오류 발생시 저장할 리스트(error_list)를 만든다.
for문을 통해 전종목 재무제표를 다운로드 받으며, 진행상황을 알기위해
tqdm()함수를 이용한다.URL 생성, 데이터 다운로드 및 데이터 클렌징 및 DB에 저장은 위와 동일하며, try except문을 통해 오류가 발생시 티커를 출력 후 error_list에 저장한다.
무한 크롤링을 방지하기 위해 한 번의 루프가 끝날 때마다 타임슬립을 적용한다.
모든 작업이 끝나면 DB와의 연결을 종료한다.
작업이 끝난 후 SQL의 kor_fs 테이블을 확인해보면 전 종목의 재무제표가 저장되어 있다. 시간이 지나 위 코드를 다시 실행하면 upsert 형식을 통해 수정된 재무제표는 update를, 새로 입력된 재무제표는 insert를 한다.
Fig. 10.19 재무제표 테이블#
10.6. 가치지표 계산#
위에서 구한 재무제표 데이터를 이용해 가치지표를 계산할 수 있다. 흔히 가치지표로는 ‘PER’, ‘PBR’, ‘PCR’, ‘PSR’, ‘DY’가 사용된다.
지표 |
설명 |
필요한 재무제표 데이터 |
|---|---|---|
PER |
Price to Earnings Ratio |
Earnings (순이익) |
PBR |
Price to Book Ratio |
Book Value (순자산) |
PCR |
Price to Cash Flow Ratio |
Cash Flow (영업활동현금흐름) |
PSR |
Price to Sales Ratio |
Sales (매출액) |
DY |
Dividend Yield |
Dividened (배당) |
가치지표의 경우 연간 재무제표 기준으로 계산할 경우 다음 재무제표가 발표될 때까지 1년이나 기다려야 한다. 반면 분기 재무제표는 3개월 마다 발표되므로 최신 정보를 훨씬 빠르게 반영할 수 있다는 장점이 있으므로 일반적으로 최근 4분기 데이터를 이용해 계산하는 TTM(Trailing Twelve Months) 방법을 많이 사용한다. 먼저 예제로 삼성전자의 가치지표를 계산해보도록 하자.
# 패키지 불러오기
from sqlalchemy import create_engine
import pandas as pd
# DB 연결
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/stock_db')
# 티커 리스트
ticker_list = pd.read_sql("""
select * from kor_ticker
where 기준일 = (select max(기준일) from kor_ticker)
and 종목구분 = '보통주';
""", con=engine)
# 삼성전자 분기 재무제표
sample_fs = pd.read_sql("""
select * from kor_fs
where 공시구분 = 'q'
and 종목코드 = '005930'
and 계정 in ('당기순이익', '자본', '영업활동으로인한현금흐름', '매출액');
""", con=engine)
engine.dispose()
DB에 연결한다.
티커 리스트를 불러온다.
삼성전자의 분기공시 자료 중 가치지표 계산에 필요한 항목들만 불러온다.
DB와의 연결을 종료한다.
sample_fs = sample_fs.sort_values(['종목코드', '계정', '기준일'])
sample_fs.head()
| 계정 | 기준일 | 값 | 종목코드 | 공시구분 | |
|---|---|---|---|---|---|
| 0 | 당기순이익 | 2021-06-30 | 96345.0 | 005930 | q |
| 1 | 당기순이익 | 2021-09-30 | 122933.0 | 005930 | q |
| 2 | 당기순이익 | 2021-12-31 | 108379.0 | 005930 | q |
| 3 | 당기순이익 | 2022-03-31 | 113246.0 | 005930 | q |
| 4 | 매출액 | 2021-06-30 | 636716.0 | 005930 | q |
먼저 sort_values() 함수를 통해 재무제표 데이터를 종목코드, 계정, 기준일 순으로 정렬한다.
sample_fs['ttm'] = sample_fs.groupby(
['종목코드', '계정'], as_index=False)['값'].rolling(window=4,
min_periods=4).sum()['값']
sample_fs
| 계정 | 기준일 | 값 | 종목코드 | 공시구분 | ttm | |
|---|---|---|---|---|---|---|
| 0 | 당기순이익 | 2021-06-30 | 96345.0 | 005930 | q | NaN |
| 1 | 당기순이익 | 2021-09-30 | 122933.0 | 005930 | q | NaN |
| 2 | 당기순이익 | 2021-12-31 | 108379.0 | 005930 | q | NaN |
| 3 | 당기순이익 | 2022-03-31 | 113246.0 | 005930 | q | 440903.0 |
| 4 | 매출액 | 2021-06-30 | 636716.0 | 005930 | q | NaN |
| 5 | 매출액 | 2021-09-30 | 739792.0 | 005930 | q | NaN |
| 6 | 매출액 | 2021-12-31 | 765655.0 | 005930 | q | NaN |
| 7 | 매출액 | 2022-03-31 | 777815.0 | 005930 | q | 2919978.0 |
| 8 | 영업활동으로인한현금흐름 | 2021-06-30 | 120865.0 | 005930 | q | NaN |
| 9 | 영업활동으로인한현금흐름 | 2021-09-30 | 185815.0 | 005930 | q | NaN |
| 10 | 영업활동으로인한현금흐름 | 2021-12-31 | 206345.0 | 005930 | q | NaN |
| 11 | 영업활동으로인한현금흐름 | 2022-03-31 | 104531.0 | 005930 | q | 617556.0 |
| 12 | 자본 | 2021-06-30 | 2823240.0 | 005930 | q | NaN |
| 13 | 자본 | 2021-09-30 | 2967660.0 | 005930 | q | NaN |
| 14 | 자본 | 2021-12-31 | 3049000.0 | 005930 | q | NaN |
| 15 | 자본 | 2022-03-31 | 3152910.0 | 005930 | q | 11992810.0 |
종목코드와 계정을 기준으로
groupby()함수를 통해 그룹을 묶으며,as_index=False를 통해 그룹 라벨을 인덱스로 사용하지 않는다.rolling()메서드를 통해 4개 기간씩 합계를 구하며,min_periods인자를 통해 데이터가 최소 4개는 있을 경우에만 값을 구한다. 즉 4개 분기 데이터를 통해 TTM 값을 계산하며, 12개월치 데이터가 없을 경우는 계산을 하지 않는다.
import numpy as np
sample_fs['ttm'] = np.where(sample_fs['계정'] == '자본',
sample_fs['ttm'] / 4, sample_fs['ttm'])
sample_fs = sample_fs.groupby(['계정', '종목코드']).tail(1)
sample_fs.head()
| 계정 | 기준일 | 값 | 종목코드 | 공시구분 | ttm | |
|---|---|---|---|---|---|---|
| 3 | 당기순이익 | 2022-03-31 | 113246.0 | 005930 | q | 440903.0 |
| 7 | 매출액 | 2022-03-31 | 777815.0 | 005930 | q | 2919978.0 |
| 11 | 영업활동으로인한현금흐름 | 2022-03-31 | 104531.0 | 005930 | q | 617556.0 |
| 15 | 자본 | 2022-03-31 | 3152910.0 | 005930 | q | 2998202.5 |
‘자본’ 항목은 재무상태표에 해당하는 항목이므로 합이 아닌 4로 나누어 평균을 구하며, 타 헝목은 4분기 기준 합을 그대로 사용한다.
계정과 종목코드별 그룹을 나누 후
tail(1)함수를 통해 가장 최근 데이터만 선택한다.
가치지표 중 분모에 해당하는 재무제표 값들을 계산을 했으며, 분자에 해당하는 시가총액은 티커 리스트에서 구할 수 있다.
sample_fs_merge = sample_fs[['계정', '종목코드', 'ttm']].merge(
ticker_list[['종목코드', '시가총액', '기준일']], on='종목코드')
sample_fs_merge['시가총액'] = sample_fs_merge['시가총액']/100000000
sample_fs_merge.head()
| 계정 | 종목코드 | ttm | 시가총액 | 기준일 | |
|---|---|---|---|---|---|
| 0 | 당기순이익 | 005930 | 440903.0 | 3659480.0 | 2022-08-03 |
| 1 | 매출액 | 005930 | 2919978.0 | 3659480.0 | 2022-08-03 |
| 2 | 영업활동으로인한현금흐름 | 005930 | 617556.0 | 3659480.0 | 2022-08-03 |
| 3 | 자본 | 005930 | 2998202.5 | 3659480.0 | 2022-08-03 |
위에서 계산한 테이블과 티커 리스트 중 필요한 열만 선택해 테이블을 합친다. 재무제표 데이터의 경우 단위가 억원인 반면 시가총액은 원이므로, 시가총액을 억으로 나눠 단위를 맞춰준다.
sample_fs_merge['value'] = sample_fs_merge['시가총액'] / sample_fs_merge['ttm']
sample_fs_merge['지표'] = np.where(
sample_fs_merge['계정'] == '매출액', 'PSR',
np.where(
sample_fs_merge['계정'] == '영업활동으로인한현금흐름', 'PCR',
np.where(sample_fs_merge['계정'] == '자본', 'PBR',
np.where(sample_fs_merge['계정'] == '당기순이익', 'PER', None))))
sample_fs_merge
| 계정 | 종목코드 | ttm | 시가총액 | 기준일 | value | 지표 | |
|---|---|---|---|---|---|---|---|
| 0 | 당기순이익 | 005930 | 440903.0 | 3659480.0 | 2022-08-03 | 8.299966 | PER |
| 1 | 매출액 | 005930 | 2919978.0 | 3659480.0 | 2022-08-03 | 1.253256 | PSR |
| 2 | 영업활동으로인한현금흐름 | 005930 | 617556.0 | 3659480.0 | 2022-08-03 | 5.925746 | PCR |
| 3 | 자본 | 005930 | 2998202.5 | 3659480.0 | 2022-08-03 | 1.220558 | PBR |
분자(시가총액)를 분모(TTM 기준 재무제표 데이터)로 나누어 가치지표를 계산한 후, 각 지표명을 입력한다.
마지막으로 배당수익률의 경우 티커리스트의 데이터를 통해 계산할 수 있다.
ticker_list_sample = ticker_list[ticker_list['종목코드'] == '005930'].copy()
ticker_list_sample['DY'] = ticker_list_sample['주당배당금'] / ticker_list_sample['종가']
ticker_list_sample.head()
| 종목코드 | 종목명 | 시장구분 | 종가 | 시가총액 | 기준일 | EPS | 선행EPS | BPS | 주당배당금 | 종목구분 | DY | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 260 | 005930 | 삼성전자 | KOSPI | 61300.0 | 3.659480e+14 | 2022-08-03 | 5777.0 | 5900.0 | 43611.0 | 1444.0 | 보통주 | 0.023556 |
티커 리스트의 각종 데이터 중 주당배당금을 종가로 나누면 현재시점 기준 배당수익률을 쉽게 계산할 수 있다.
10.6.1. 전 종목 가치지표 계산#
위 코드를 응용해 전 종목 가치지표를 계산해보도록 하자. 먼저 SQL에서 가치지표가 저장될 테이블(kor_value)을 만들어준다.
use stock_db;
create table kor_value
(
종목코드 varchar(6),
기준일 date,
지표 varchar(3),
값 double,
primary key (종목코드, 기준일, 지표)
);
이제 파이썬에서 재무 데이터를 이용해 가치지표를 계산한다.
# 패키지 불러오기
import pymysql
from sqlalchemy import create_engine
import pandas as pd
import numpy as np
# DB 연결
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/stock_db')
con = pymysql.connect(user='root',
passwd='1234',
host='127.0.0.1',
db='stock_db',
charset='utf8')
mycursor = con.cursor()
# 분기 재무제표 불러오기
kor_fs = pd.read_sql("""
select * from kor_fs
where 공시구분 = 'q'
and 계정 in ('당기순이익', '자본', '영업활동으로인한현금흐름', '매출액');
""", con=engine)
# 티커 리스트 불러오기
ticker_list = pd.read_sql("""
select * from kor_ticker
where 기준일 = (select max(기준일) from kor_ticker)
and 종목구분 = '보통주';
""", con=engine)
engine.dispose()
DB에 연결한다.
분기 재무제표와 티커 리스트를 불러온다.
# TTM 구하기
kor_fs = kor_fs.sort_values(['종목코드', '계정', '기준일'])
kor_fs['ttm'] = kor_fs.groupby(['종목코드', '계정'], as_index=False)['값'].rolling(
window=4, min_periods=4).sum()['값']
# 자본은 평균 구하기
kor_fs['ttm'] = np.where(kor_fs['계정'] == '자본', kor_fs['ttm'] / 4,
kor_fs['ttm'])
kor_fs = kor_fs.groupby(['계정', '종목코드']).tail(1)
sort_values()함수를 통해 종목코드, 계정, 기준일 순으로 정렬을 한다.종목코드와 계정 별 그룹을 묶은 후, 롤링 합을 통해 TTM 값을 구한다.
‘자본’ 항목은 재무상태표에 해당하는 항목이므로 합이 아닌 평균을 구하며, 타 항목은 4분기 기준 합을 그대로 사용한다.
tail(1)을 통해 최근 데이터를 선택한다.
이제 티커리스트의 시가총액 데이터를 이용해 가치지표를 계산해주도록 한다.
kor_fs_merge = kor_fs[['계정', '종목코드',
'ttm']].merge(ticker_list[['종목코드', '시가총액', '기준일']],
on='종목코드')
kor_fs_merge['시가총액'] = kor_fs_merge['시가총액'] / 100000000
kor_fs_merge['value'] = kor_fs_merge['시가총액'] / kor_fs_merge['ttm']
kor_fs_merge['value'] = kor_fs_merge['value'].round(4)
kor_fs_merge['지표'] = np.where(
kor_fs_merge['계정'] == '매출액', 'PSR',
np.where(
kor_fs_merge['계정'] == '영업활동으로인한현금흐름', 'PCR',
np.where(kor_fs_merge['계정'] == '자본', 'PBR',
np.where(kor_fs_merge['계정'] == '당기순이익', 'PER', None))))
kor_fs_merge.rename(columns={'value': '값'}, inplace=True)
kor_fs_merge = kor_fs_merge[['종목코드', '기준일', '지표', '값']]
kor_fs_merge = kor_fs_merge.replace([np.inf, -np.inf, np.nan], None)
kor_fs_merge.head(4)
| 종목코드 | 기준일 | 지표 | 값 | |
|---|---|---|---|---|
| 0 | 000020 | 2022-08-03 | PER | 14.9532 |
| 1 | 000020 | 2022-08-03 | PSR | 0.9660 |
| 2 | 000020 | 2022-08-03 | PCR | 6.7597 |
| 3 | 000020 | 2022-08-03 | PBR | 0.8314 |
TTM 기준으로 계산된 재무제표 테이블과 티커리스트 테이블을 합친다.
시가총액을 억원으로 나눈다.
시가총액을 재무데이터 값으로 나누어 가치지표를 계산한 후, 반올림을 한다.
각 계정에 맞게 계정명(PSR, PCR, PER, PBR)을 적는다.
rename()메서드를 통해 ‘value’라는 열 이름을 ‘값’으로 변경한다.필요한 열만 선택한 후,
replace()메서드를 통해 inf와 nan를 None으로 변경한다.
계산된 가치지표를 데이터베이스에 저장하자.
query = """
insert into kor_value (종목코드, 기준일, 지표, 값)
values (%s,%s,%s,%s) as new
on duplicate key update
값=new.값
"""
args_fs = kor_fs_merge.values.tolist()
mycursor.executemany(query, args_fs)
con.commit()
가치지표를 kor_value 테이블에 upsert 방식으로 저장한다. 마지막으로 배당수익률의 경우 티커리스트를 통해 한번에 계산할 수 있다.
ticker_list['값'] = ticker_list['주당배당금'] / ticker_list['종가']
ticker_list['값'] = ticker_list['값'].round(4)
ticker_list['지표'] = 'DY'
dy_list = ticker_list[['종목코드', '기준일', '지표', '값']]
dy_list = dy_list.replace([np.inf, -np.inf, np.nan], None)
dy_list = dy_list[dy_list['값'] != 0]
dy_list.head()
| 종목코드 | 기준일 | 지표 | 값 | |
|---|---|---|---|---|
| 0 | 000020 | 2022-08-03 | DY | 0.0170 |
| 2 | 000050 | 2022-08-03 | DY | 0.0097 |
| 3 | 000060 | 2022-08-03 | DY | 0.0172 |
| 4 | 000070 | 2022-08-03 | DY | 0.0414 |
| 5 | 000080 | 2022-08-03 | DY | 0.0256 |
주당배당금을 종가로 나누어 배당수익률을 계산한 후, 반올림을 한다.
‘지표’열에 ‘DY’라는 글자를 입력한다.
원하는 열만 선택한다.
inf와 nan은 None으로 변경한다.
주당배당금이 0원인 종목은 값이 0으로 계산되므로, 이를 제외한 종목만 선택한다.
args_dy = dy_list.values.tolist()
mycursor.executemany(query, args_dy)
con.commit()
engine.dispose()
con.close()
배당수익률 역시 kor_value 테이블에 upsert 방식으로 저장한 후, DB와의 연결을 종료한다.
Fig. 10.20 가치지표 테이블#