6. 파이썬에서 SQL 연결하기#
SQL을 통해 데이터베이스에서 필요한 데이터를 불러와 CSV 파일로 저장한 후 이를 다시 파이썬으로 불러오는 과정은 다소 비효율적이다. 파이썬에서는 SQL에 직접 연결이 가능하기에 이를 통해 훨씬 효율적으로 작업을 할 수 있다. 즉, 파이썬에서 SQL DB에 접속하여 데이터를 가공 후 불러오고, 이를 토대로 결과물을 얻거나 가공한 데이터를 다시 SQL DB에 저장하는 것이 가능하다.
6.1. 파이썬에서 SQL DB에 접속하기#
pymysql 패키지를 이용하면 파이썬에서 SQL DB에 접속 및 작업이 가능하다.
import pymysql
con = pymysql.connect(
user='root',
passwd='1234',
host='127.0.0.1',
db='shop',
charset='utf8'
)
mycursor = con.cursor()
먼저 connect() 메서드를 사용하여 MySQL에 접속하며, 입력값은 다음과 같다.
user: 사용자명
passwd: 비밀번호
host: 허용 접속 IP (일반적으로 localhost는 127.0.0.1 다).
db: 사용할 데이터베이스
charset: 인코딩 방법
그 후, cursor() 메서드를 통해 데이터베이스의 커서 객체를 가져온다. 화면에서 현재 사용자의 위치를 나타내며 깜빡거리는 막대기를 커서라고 부르듯이, 데이터베이스에서도 데이터 중에서 특정 위치, 특정 행을 가르킬 때 커서가 사용된다. 즉 현재 작업중인 레코드를 나타내는 객체다.
이제 shop 데이터베이스 중 goods 테이블을 가져와보도록 하자.
query = """
select * from goods;
"""
mycursor.execute(query)
data = mycursor.fetchall()
con.close()
display(data)
(('0001', '티셔츠', '의류', 1000, 500, datetime.date(2020, 9, 20)),
('0002', '펀칭기', '사무용품', 500, 320, datetime.date(2020, 9, 11)),
('0003', '와이셔츠', '의류', 4000, 2800, None),
('0004', '식칼', '주방용품', 3000, 2800, datetime.date(2020, 9, 20)),
('0005', '압력솥', '주방용품', 6800, 5000, datetime.date(2020, 1, 15)),
('0006', '포크', '주방용품', 500, None, datetime.date(2020, 9, 20)),
('0007', '도마', '주방용품', 880, 790, datetime.date(2020, 4, 28)),
('0008', '볼펜', '사무용품', 100, None, datetime.date(2020, 11, 11)))
실행하고자 쿼리를 입력하며, goods 테이블의 모든 데이터를 가져오는 쿼리를 입력한다.
execute()메서드를 사용하여 SQL 쿼리를 데이터베이스 서버에 보낸다.fetchall(),fetchone(),fetchmany()등의 메서드를 사용하여 서버로부터 데이터를 가져온다.fetchall(): 테이블 안의 모든 데이터를 추출fetchone():테이블 안의 데이터를 한 행씩 추출fetchmany(size=n): 테이블 안의 데이터 중 n개의 행을 추출
원하는 작업을 마친 후에는 반드시
close()메서드를 통해 데이터베이스와의 연결을 종료해야 한다.
데이터를 불러오는 것 뿐만 아니라 데이터를 입력, 수정, 삭제도 가능하다.
con = pymysql.connect(user='root',
passwd='1234',
host='127.0.0.1',
db='shop',
charset='utf8')
mycursor = con.cursor()
query = """
insert into goods (goods_id, goods_name, goods_classify, sell_price, buy_price, register_date)
values ('0009', '스테이플러', '사무용품', '2000', '1500', '2020-12-30');
"""
mycursor.execute(query)
con.commit()
con.close()
위와 과정은 거의 동일하며, 9번 id에 스테이플러에 관한 내용을 입력하는 쿼리를 작성한다. 삽입, 갱신, 삭제 등의 DML(Data Manipulation Language) 문장을 실행하는 경우, commit() 메서드를 사용하여 데이터의 확정 갱신하는 작업을 추가해준다. 실제로 MySQL에서 데이터를 확인해보면 테이블 내에 스테이플러에 대한 내용이 업데이트 되었다.
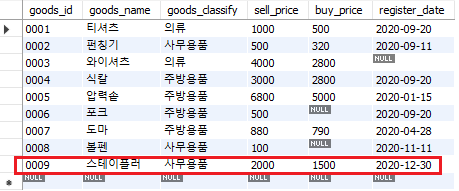
Fig. 6.1 테이블 내 데이터 업데이트#
이처럼 파이썬을 이용해 SQL 데이터베이스의 데이터를 불러오기 혹은 쓰기 작업이 가능하다.
6.2. pandas를 이용한 데이터 읽기 및 쓰기#
위 방법을 이용해 데이터를 불러오면 아쉬운 점이 있다. 먼저 열 이름이 보이지 않는다. 둘째, 데이터분석 작업을 하기 편한 데이터프레임 형태가 아니다. pandas 패키지에는 SQL 데이터베이스의 데이터를 불러오거나 저장할 수 있는 함수가 있으므로, 이에 대해 살펴보도록 하자.
import pandas as pd
from sqlalchemy import create_engine
# engine = create_engine('mysql+pymysql://[사용자명]:[비밀번호]@[호스트:포트]/[사용할 데이터베이스]')
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/shop')
query = """select * from Goods"""
goods = pd.read_sql(query, con=engine)
engine.dispose()
goods.head()
| goods_id | goods_name | goods_classify | sell_price | buy_price | register_date | |
|---|---|---|---|---|---|---|
| 0 | 0001 | 티셔츠 | 의류 | 1000 | 500.0 | 2020-09-20 |
| 1 | 0002 | 펀칭기 | 사무용품 | 500 | 320.0 | 2020-09-11 |
| 2 | 0003 | 와이셔츠 | 의류 | 4000 | 2800.0 | None |
| 3 | 0004 | 식칼 | 주방용품 | 3000 | 2800.0 | 2020-09-20 |
| 4 | 0005 | 압력솥 | 주방용품 | 6800 | 5000.0 | 2020-01-15 |
pandas에서 SQL에 연결할 때는 SQLalchemy ORM을 사용해야 한다. ORM(Object Relational Mapping)이란 어플리케이션과 데이터베이스를 연결할 때 SQL 언어가 아닌 어플리케이션 개발언어로 데이터베이스를 접근할 수 있게 해주는 툴이다. 쉽게 말해 파이썬 코드를 SQL 쿼리로 자동 변환하여, SQL 쿼리를 따로 작성할 필요가 없이 파이썬 코드를 작성하는 것 만으로 데이터베이스를 조작할 수 있게 해준다. 사용자명과 비밀번호, 호스트, 포트, 데이터베이스 명은 본인에게 해당하는 값을 입력하면 된다. (MySQL의 포트번호는 일반적으로 3306 이다.)
쿼리를 작성 후
read_sql()함수에 이를 입력한다.engine.dispose()를 통해 연결을 종료한다.
결과를 확인해보면 우리에게 친숙한 데이터프레임 형태로 데이터가 불러와진다. 이번에는 데이터프레임을 SQL 데이터베이스에 저장해보도록 하자.
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
예제로 seaborn 패키지의 iris 데이터를 사용한다. load_dataset() 함수를 통해 해당 데이터를 불러온다.
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/shop')
iris.to_sql(name = 'iris', con = engine, index = False, if_exists = 'replace')
engine.dispose()
create_engine()함수를 통해 데이터베이스에 접속하기 위한 엔진을 만든다.데이터프레임.to_sql()을 통해 데이터프레임을 데이터베이스에 저장할 수 있다. 테이블명은 iris로 하며, con에는 위에서 생성한 엔진을 입력한다. index = False를 통해 인덱스는 생성하지 않으며,if_exists = 'replace'를 입력하면 해당 테이블이 존재할 시 데이터를 덮어쓴다.engine.dispose()를 통해 연결을 종료한다.
MySQL에서 확인해보면, shop 데이터베이스 내에 iris라는 테이블이 생성되었다. 이처럼 to_sql() 함수를 사용하면 파이썬에서 데이터프레임을 작업한 후 곧바로 데이터베이스에 저장할 수 있다.
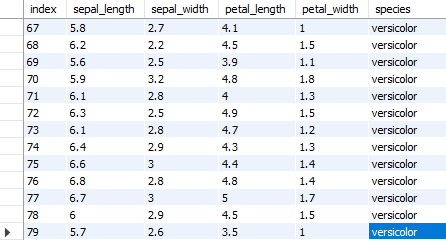
Fig. 6.2 iris 테이블#
6.3. upsert 기능 구현하기#
퀀트 투자에 사용할 시계열 데이터는 크게 두가지 특성을 가지고 있다.
insert: 시간이 지남에 따라 데이터가 추가된다.
update: 간혹 과거 데이터가 수정된다.
이처럼 입력하고자 하는 데이터가 기존 테이블에 값이 있는 경우 새로운 데이터로 업데이트(update) 하고, 값이 없는 경우 새로운 데이터를 추가(insert)하는 기능을 MySQL에서는 upsert 라고 한다. 예제를 통해 to_sql() 함수를 이용해 시계열 데이터를 저장할 경우 발생하는 문제 및 upsert 기능을 사용하는 방법에 대해 살펴보도록 하자.
먼저 create_database() 함수를 통해 ‘exam’이라는 데이터베이스를 만든다.
from sqlalchemy_utils import create_database
create_database('mysql+pymysql://root:1234@127.0.0.1:3306/exam')
다음으로 exam 데이터베이스에 저장할 샘플 시계열 데이터를 만든다.
price = pd.DataFrame({
"날짜": ['2021-01-02', '2021-01-03'],
"티커": ['000001', '000001'],
"종가": [1340, 1315],
"거래량": [1000, 2000]
})
price.head()
| 날짜 | 티커 | 종가 | 거래량 | |
|---|---|---|---|---|
| 0 | 2021-01-02 | 000001 | 1340 | 1000 |
| 1 | 2021-01-03 | 000001 | 1315 | 2000 |
위에서 생성한 데이터를 데이터베이스에 저장해보도록 하자.
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/exam')
price.to_sql('price', con=engine, if_exists='append', index=False)
data_sql = pd.read_sql('price', con=engine)
engine.dispose()
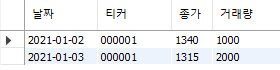
Fig. 6.3 exam 데이터베이스 내 price 테이블#
to_sql() 함수의 인자로 if_exists = ‘append’를 입력하면, 테이블이 존재할 경우 기존 테이블에 데이터를 추가한다. 이제 하루가 지나 시계열이 추가되었다고 가정하자.
new = pd.DataFrame({
"날짜": ['2021-01-04'],
"티커": ['000001'],
"종가": [1320],
"거래량": [1500]
})
price = pd.concat([price, new])
price.head()
| 날짜 | 티커 | 종가 | 거래량 | |
|---|---|---|---|---|
| 0 | 2021-01-02 | 000001 | 1340 | 1000 |
| 1 | 2021-01-03 | 000001 | 1315 | 2000 |
| 0 | 2021-01-04 | 000001 | 1320 | 1500 |
해당 데이터를 동일한 방법으로 데이터베이스에 저장해보도록 하자.
engine = create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/exam')
price.to_sql('price', con=engine, if_exists='append', index=False)
data_sql = pd.read_sql('price', con=engine)
engine.dispose()
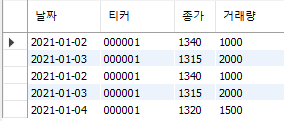
Fig. 6.4 price 테이블에 새로운 데이터 추가#
단순히 데이터를 추가하면 2021-01-02와 2021-01-03에 해당하는 데이터가 중복으로 들어가는 문제가 발생한다. to_sql() 함수 내에 if_exists = ‘replace’로 입력할 경우 새로운 데이터로 덮어쓰게 되어 이러한 문제가 해결되지만, 이는 이전 데이터(예: 2021년 이전)도 모두 삭제되는 문제가 발생한다. 따라서 기존에 값이 있는 2021-01-02와 2021-01-03 데이터는 그대로 두고, 새롭게 추가되는 2021-01-04 데이터만 추가할 필요가 있다.
MySQL에서 upsert를 구현하는 쿼리는 다음과 같다.
insert into @table
(arg1, arg2, arg3)
values
(@arg1, @arg2, @arg3 )
on duplicate key update (Key를 제외한 Update할 컬럼들 나열)
arg2 = @arg2, arg3 = @arg3
즉 [table]의 [arg1, arg2, arg3] 열에 [@arg1, @arg2, @arg3] 데이터를 추가하며, 만약 키 값(arg1)에 데이터(@arg1)가 이미 존재한다면 @arg2와 @arg3로 데이터를 업데이트 한다.
6.3.1. MySQL에서 upsert 기능 구현하기#
먼저 쉬운 이해를 위해 SQL에서 해당 기능이 어떻게 구현되는지 확인해보도록 하자. MySQL Workbench에서 다음의 쿼리를 입력하여 price_2 테이블을 만든다.
use exam;
CREATE TABLE price_2(
날짜 varchar(10),
티커 varchar(6),
종가 int,
거래량 int,
PRIMARY KEY(날짜, 티커)
);
총 4개 열(날짜, 티커, 종가, 거래량)으로 구성되어 있으며 날짜와 티커별로 종가와 거래량이 다르므로 날짜와 티커를 기본 키로 지정한다. 이제 테이블에 값을 넣어보도록 하자.
insert into price_2 (날짜, 티커, 종가, 거래량)
values
('2021-01-02', '000001', 1340, 1000),
('2021-01-03', '000001', 1315, 2000),
('2021-01-02', '000002', 500, 200);
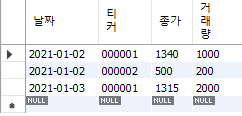
Fig. 6.5 테이블 생성 및 데이터 입력#
000001 종목은 1월 2일과 3일 모두 데이터가 입력되었지만, 000002 종목은 1월 2일 데이터만 입력되었다. upsert 기능을 이용해 데이터를 추가해보도록 하자.
insert into price_2 (날짜, 티커, 종가, 거래량)
values
('2021-01-02', '000001', 1340, 1000),
('2021-01-03', '000001', 1315, 2000),
('2021-01-02', '000002', 500, 200),
('2021-01-03', '000002', 1380, 3000)
as new
on duplicate key update
종가 = new.종가, 거래량 = new.거래량;
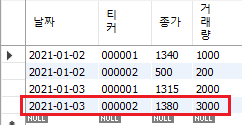
Fig. 6.6 데이터 업데이트#
앞의 [insert into … values] 부분은 일반적인 데이터를 입력하는 쿼리와 형태가 같으며, 그 후 new라는 별명을 붙여준 후 [on duplicate key update] 구문을 추가해준다. 즉 데이터를 입력하되, 키 값(날짜, 티커)을 기준으로 이미 데이터가 존재할 경우에는 입력이 아닌 업데이트를 해준다. 000001 종목의 1월 2~3일, 000002 종목의 1월 2일 데이터는 이미 존재하며 데이터가 바뀌지 않아 값이 그대로 유지된다. 반면 000002 종목의 1월 3일 데이터는 기존에 없던 값이기에 새롭게 추가된다.
이번에는 입력과 업데이트를 동시에 진행해보겠다.
insert into price_2 (날짜, 티커, 종가, 거래량)
values
('2021-01-02', '000001', 1300, 1100),
('2021-01-04', '000001', 1300, 2000)
as new
on duplicate key update
종가 = new.종가, 거래량 = new.거래량;
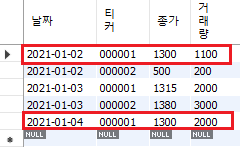
Fig. 6.7 upsert 기능 구현#
000001 종목의 1월 2일 데이터는 이미 테이블에 존재하기에 입력한 1300 / 1100으로 데이터를 업데이트한다.
000001 종목의 1월 4일 데이터는 테이블에 없는 값이기에 새로 입력한다.
이처럼 upsert 기능을 이용하면 시계열 데이터의 추가 및 수정을 한번에 할 수 있다.
6.3.2. 파이썬에서 upsert 기능 구현하기#
이번에는 upsert 기능을 파이썬에서 구현해보도록 하자.
price = pd.DataFrame({
"날짜": ['2021-01-04', '2021-01-04'],
"티커": ['000001', '000002'],
"종가": [1320, 1315],
"거래량": [2100, 1500]
})
args = price.values.tolist()
args
[['2021-01-04', '000001', 1320, 2100], ['2021-01-04', '000002', 1315, 1500]]
먼저 데이터베이스에 저장할 데이터를 리스트 형태로 만들어준다.
con = pymysql.connect(user='root',
passwd='1234',
host='127.0.0.1',
db='exam',
charset='utf8')
query = """
insert into price_2 (날짜, 티커, 종가, 거래량)
values (%s,%s,%s,%s) as new
on duplicate key update
종가 = new.종가, 거래량 = new.거래량;
"""
mycursor = con.cursor()
mycursor.executemany(query, args)
con.commit()
con.close()
exam 데이터베이스에 접속한다.
upsert 기능을 구현하는 쿼리를 입력하며, values 부분에는 입력하는 데이터의 열 갯수만큼 ‘%s’를 입력한다.
cursor()메서드를 통해 데이터베이스의 커서 객체를 가져온다.execute()메서드를 사용하여 SQL 쿼리를 데이터베이스 서버에 보낸다. 즉 %s 부분에 리스트로 만든 데이터가 입력되어 데이터베이스 서버에 전송된다.commit()메서드를 사용하여 데이터의 확정을 갱신한다.접속을 종료한다.
실제로 데이터를 확인해보면 1월 4일 000001 종목의 데이터는 수정이 되었으며, 000002 종목의 데이터는 새로 입력되었다.
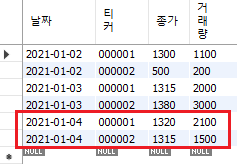
Fig. 6.8 파이썬에서 upsert 기능 구현#
마지막으로 예제로 사용했던 데이터베이스(exam)는 삭제해준다.
con = pymysql.connect(user='root',
passwd='1234',
host='127.0.0.1',
db='exam',
charset='utf8')
query = """
drop database exam;
"""
mycursor = con.cursor()
mycursor.execute(query)
con.commit()
con.close()